




Quartz를 활용한 동적 스케줄링 시스템 구축기
- 들어가며
최근 데이터 플랫폼을 개발하며, 사용자가 웹 화면에서 직접 작업 실행 주기를 설정하고 변경할 수 있는 동적 스케줄링 기능이 필요했다. 이 요구사항을 만족 시키기 위해 여러 기술적 대안을 찾아보았다.
구현 방법을 찾아보니
- Shell Script + cron
- Spring Scheduling
- Quartz
- Kafka Streams + 스케줄링 라이브러리(Quartz같은)
4가지 방법이 있다.
각각의 장단점을 간단히 살펴보면
- Shell Script + cron: 전통적이고 강력하지만, 스케줄 변경을 위해 서버에 직접 접속해 crontab 파일을 수정해야 하므로 동적 스케줄링 요구사항에는 맞지 않았다.
- Spring Scheduling (@Scheduled): Spring 애플리케이션과 완벽하게 통합되어 Bean을 직접 호출할 수 있다는 큰 장점이 있다. 하지만 동적으로 스케줄을 추가하거나 변경하는 것이 복잡하고, 스케줄 정보가 메모리 기반이라 애플리케이션 재시작 시 정보가 사라지는 단점이 있었다.
- Quartz: 강력한 동적 스케줄링 기능과 실행 정보를 데이터베이스에 영속화하는 기능을 제공한다. 특히 여러 서버가 하나의 DB를 바라보며 동작하는 클러스터링을 지원하여 고가용성 확보에 유리했다.
- Kafka Streams + 스케줄링 라이브러리: MSA 환경에서 수백만 건의 이벤트를 처리하는 대규모 시스템에 적합한 방식이다. 저희 프로젝트의 규모와 요구사항에는 다소 과하다고 판단했다.
각 기술의 장단점을 비교한 결과, 우리의 주된 요구사항인 **“동적 스케줄링”**과 배치성 작업의 안정적인 실행을 위한 “클러스터링” 및 **“영속성”**을 모두 만족하는 Quartz가 가장 적합한 선택이라고 생각해 Quartz를 사용하기로 결정했다.
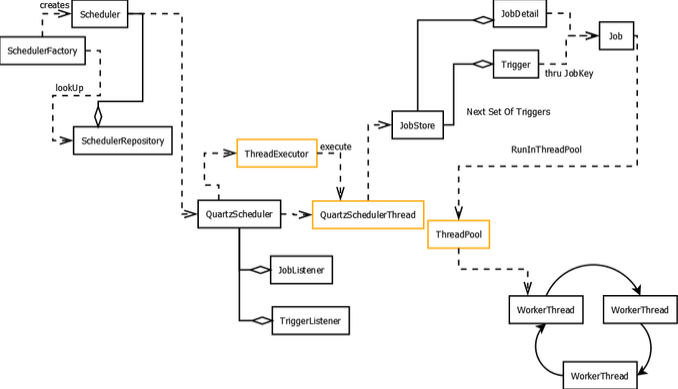
1. Quartz란?
- Terracotta라는 회사에 의해 개발된 Job Scheduling 라이브러리
- 완전히 자바로 개발되어 어느 자바 프로그램에서도 쉽게 통합해 개발 가능
- Quartz는 수십에서 수천개의 작업도 실행 가능하며 Interval형식이나 Cron 표현식으로 복잡한 스케줄링도 지원
장점
- DB기반 스케줄러 간의 Clustering 기능 제공
- In-memory Job Scheduler도 제공
- 영속성(Persistence): 스케줄 정보를 메모리(In-memory)뿐만 아니라 JDBC를 통해 데이터베이스에 저장할 수 있어, 애플리케이션이 재시작되어도 스케줄 정보가 유실되지 않는다.
- 여러 기본 Plug-in 제공
- ShutdownHookPlugin - JVM 종료 이벤트를 캐치해서 스케줄러에게 종료를 알려준다
- LoggingJobHistoryPlugin - Job 실행에 대한 로그를 남겨 디버깅할 때 유용하게 사용할 수 있다
단점
- Clustering 기능을 제공하지만, 단순한 random방식이라 완벽한 Cluster같의 로드 분산이 안된다.
- 스케줄링 실행에 대한 History를 보관하지 않는다. 추가 작업이 필요하다.
- Fixed Delay타입을 보장하지 않으므로 추가 작업이 필요하다.
2. Quartz의 주요 요소
- Job : 스케줄링 된 작업을 수행(정보 포함), Job 인스턴스를 정의하고 해당 인스턴스는 Spring 빈으로 등록 가능
- Quartz API에서 단 하나의 메서드를 가진 execute Job 인터페이스를 제공한다. 수행해야 하는 실제 작업을 이 메서드에서 구현한다.
- Job의 Trigger가 발생하면 스케줄러는 JobExecutionContext 개겣를 넘겨주고 execute 메서드를 호출한다.
- JobExecutionContext는 Scheduler, Trigger, JobDetail을 포함해 Job인스턴스에 대한 정보를 제공하는 객체이다.
- JobDataMap : JobDataMap은 Job인스턴스가 실행할 때 사용할 수 있게 원하는 정보를 담을 수 있는 객체이다.
- JobDetail : 작업(Job)의 인스턴스를 래핑하고 Job실행에 필요한 추가 정보를 제공 (ex - Job의 이름, 그룹, 기타 파라미터)
- JobDetail객체는 스케줄러에 Job을 등록할 때 사용되고, Quartz는 JobDetail을 통해 어떤 Job을 언제 실행할지를 관리한다.
- Trigger : Job을 언제 실행할지를 결정하는 Quartz의 구성 요소
- Trigger와 Job의 관계
- 1 Trigger = 1 Job
- 반드시 하나의 Trigger는 반드시 하나의 Job을 지정할 수 있다.
- N Trigger = 1 Job
- 하나의 Job을 여러 시간 떄로 실행시킬 수 있다. (ex - 매주 주말, 매 시간)
- 1 Trigger = 1 Job
- SimpleTrigger :한번 실행하거나 지정된 간격으로 반복 실행할 때 사용
- Crontrigger : Corn과 같은 방식으로 복잡한 시간 기반 스케줄을 설정할 때 사용 (분, 시, 일, 월, 요일)
- 복잡한 스케줄링도 실행 가능하다. (ex - 매월 마지막 주말에 오후 3시부터 3시 30분까지)
- Trigger와 Job의 관계
- Scheduler : 작업(Job)과 트리거(Trigger)를 등록/실행 관리하는 역할을 하며, 여러 작업과 트리거를 조정하며 작업을 실행할 시기와 방법 지정
- SchedulerFactory : Scheduler 인스턴스를 생성하고 구성하기 위한 인터페이스
- JobStore
- RAM
- JDBC
- 기타 JobStore (Redis, MongoDB)
- Misfire Instructions
- Misfire는 Job이 실행되어야 하는 시간, fire time을 지키지 못한 실행 불발을 의미한다.
- 이런 Misfire는 Scheduler가 종료될 떄나 쓰레드 풀에 사용 가능한 쓰레드가 없는 경우에 발생한다.
- Scheduler가 Misfire된 Trigger에 대해서 어떻게 처리할지에 대한 다양한 policy를 지원한다.
- ex - MISFIREINSTRUCTIONFIRE_NOW - 바로 실행, MISFIREINSTRUCTIONDO_NOTHING - 아무것도 하지 않음
- Listener
- Listener는 Scheduler의 이벤트를 받을 수 있도록 Quartz에서 제공하는 인터페이스이며 2가지가 있다.
- JobListener
- job실행 전후로 이벤트를 받을 수 있다.
- TriggerListener
- Trigger가 발생, 불발이 일어날 때, Trigger를 완료할 떄 이벤트를 받을 수 있다.
- JobListener
- Listener는 Scheduler의 이벤트를 받을 수 있도록 Quartz에서 제공하는 인터페이스이며 2가지가 있다.
3. 구현 순서
- build.gradle에 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-quartz'- application.yml에 quartz 설정값 추가
quartz:
# Quartz가 스케줄 정보를 저장할 방식을 jdbc로 지정 (DB 사용)
job-store-type: jdbc
jdbc:
# 애플리케이션 시작 시 Quartz 관련 테이블을 자동으로 생성/초기화
# 개발 초기에는 'always'가 편리하지만, 운영 환경에서는 'never'로 변경하고 DDL을 수동으로 실행하는 것을 권장
initialize-schema: always
properties:
org.quartz.scheduler.instanceName: my-clustered-scheduler
org.quartz.scheduler.instanceId: AUTO
org.quartz.threadPool.threadCount: 10
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
org.quartz.jobStore.tablePrefix: QRTZ_
# --- 클러스터링 설정 (여러 인스턴스로 앱을 실행할 경우 필수) ---
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.clusterCheckinInterval: 20000- DB 연동 + 클러스터링 설정.
- 운영환경에서는 initialize-schema: never로 바꿔야 함.
- QuartzConfig 추가
@Configuration
/**
* Spring Boot의 Quartz 자동 설정을 확장하여 커스텀 설정을 적용하는 클래스.
*/
@Configuration
public class QuartzConfig {
/**
* Quartz Job 인스턴스에 Spring의 @Autowired 의존성을 주입하기 위한 JobFactory를 Bean으로 등록합니다.
* @param applicationContext Spring의 ApplicationContext
* @return AutowiringSpringBeanJobFactory 인스턴스
*/
@Bean
public AutowiringSpringBeanJobFactory autowiringSpringBeanJobFactory(ApplicationContext applicationContext) {
AutowiringSpringBeanJobFactory jobFactory = new AutowiringSpringBeanJobFactory();
jobFactory.setApplicationContext(applicationContext);
return jobFactory;
}
/**
* Spring Boot가 자동으로 생성하는 SchedulerFactoryBean에 추가 설정을 적용하기 위한 Customizer입니다.
* 이 방법을 사용하면 Spring Boot의 자동 설정(예: auto-startup, DataSource 연결 등)을 그대로 활용하면서
* 우리가 필요한 JobFactory만 추가로 설정할 수 있습니다.
*
* @param jobFactory 위에서 Bean으로 등록한 커스텀 JobFactory
* @return SchedulerFactoryBeanCustomizer 인스턴스
*/
@Bean
public SchedulerFactoryBeanCustomizer schedulerFactoryBeanCustomizer(AutowiringSpringBeanJobFactory jobFactory) {
return schedulerFactoryBean -> {
// Spring Boot의 자동 설정을 기반으로, 우리가 만든 JobFactory를 사용하도록 설정합니다.
schedulerFactoryBean.setJobFactory(jobFactory);
// 여기에 다른 필요한 커스텀 설정을 추가할 수 있습니다.
// 예: schedulerFactoryBean.setWaitForJobsToCompleteOnShutdown(true);
};
}
}- Spring Boot의 자동 설정 대신, SchedulerFactoryBean을 직접 Bean으로 등록하여 세밀하게 제어
- Spring의 DataSource 사용.
- Quartz는 기본적으로 Job객체를 직접 생성하기 떄문에 Spring DI를 받을 수 없다 -> Quartz가 생성한 Job 객체에 @Autowired로 선언된 Spring Bean들을 주입해주는 역할
- AutowiringSpringBeanJobFactory.java: Quartz가 Job 인스턴스를 생성할 때, Spring의 ApplicationContext를 통해 의존성을 주입해주는 핵심적인 역할
- application.yml 설정을 그대로 적용.
- @EnableAutoConfiguration 어노테이션(@SpringBootApplication 어노테이션에 의해 포함됨)에 의해서 application.properties 내의 spring.datasource.* 속성은 정의하면 자동으로 인식
- AutowiringSpringBeanJobFactory 추가
- Quartz가 생성하는 Job 인스턴스에 Spring의 의존성(@Autowired)을 주입하기 위한 핵심 연결 클래스 - 이 클래스는 Spring Boot가 기본으로 제공하지 않으므로, 개발자가 직접 생성
public final class AutowiringSpringBeanJobFactory extends SpringBeanJobFactory implements ApplicationContextAware {
private transient AutowireCapableBeanFactory beanFactory;
@Override
public void setApplicationContext(final ApplicationContext context) {
beanFactory = context.getAutowireCapableBeanFactory();
}
@Override
protected Object createJobInstance(final TriggerFiredBundle bundle) throws Exception {
final Object job = super.createJobInstance(bundle);
beanFactory.autowireBean(job);
return job;
}
}- 핵심 역할: Quartz와 Spring은 서로 다른 생명주기를 가지기 때문에, Quartz가 직접 생성한 Job 객체는 원래 Spring의 DI(의존성 주입) 혜택을 받을 수 없다. 이 클래스는 그 간극을 메워주는 다리 역할
- 동작 원리:
- createJobInstance() 메소드는 Quartz 스케줄러가 Job을 실행하기 위해 Job 인스턴스를 생성한 직후에 호출
- 이 메소드를 오버라이드하여, Quartz가 막 생성한 순수한 객체(job)를 Spring의 AutowireCapableBeanFactory에 넘겨준다.
- beanFactory.autowireBean(job) 코드가 실행되는 순간, Spring은 해당 객체를 스캔하여 @Autowired가 붙은 모든 필드에 적절한 Bean을 주입
- 결과: 이 과정을 통해, 우리가 작성한 ExampleJob 클래스 안에서도 SomeService와 같은 다른 Spring Bean들을 @Autowired로 주입받아 사용할 수 있게 된다.
- job Api controller, service, dao 추가
job을 추가하길 원하는 service에서 job service를 호출해 job등록
// controller
@RestController
@RequestMapping("/wrk/api/clct")
@Tag(name = "Clct Job API", description = "연계 작업 관리 API 입니다.")
@RequiredArgsConstructor
public class WrkClctController {
...
@PostMapping
@Operation(summary = "등록", description = "연계 데이터를 등록합니다.")
public ApiResponse<Map<String, String>> create(@RequestBody @Valid SchedulSaveDto dto) {
wrkClctService.insert(dto);
Map<String, String> result = Map.of("schedulId", dto.getSchedulId());
result = Map.of("datalinkId", dto.getDatalinkId());
return new ApiResponse<>(SuccessCode.CREATED, result);
}
...
}
// service
@Slf4j
@Service
@RequiredArgsConstructor
public class WrkClctServiceImpl implements WrkClctService {
...
@Override
@Transactional
public String insert(SchedulSaveDto dto) {
wrkClctDao.datalinkInsert(dto);
switch (dto.getClctLinkType()) {
case "module": wrkClctDao.insertDatalinkModule(dto); break;
case "file": wrkClctDao.insertDatalinkFile(dto); break;
case "db": wrkClctDao.insertDatalinkDb(dto); break;
case "api": wrkClctDao.insertDatalinkApi(dto); break;
default: throw new IllegalArgumentException("지원하지 않는 연계 유형입니다: " + dto.getClctLinkType());
}
wrkClctDao.schedulInsert(dto);
// 1. 새로 생성된 스케줄의 상세 정보를 DB에서 조회합니다.
SchedulDetailDto newSchedul = wrkClctDao.getSchedulDetailById(dto.getSchedulId());
if (newSchedul != null) {
// 2. 타입과 상관없이, 모든 Job 정보(JobDetail)를 Quartz에 등록합니다.
quartzSchedulService.addOrUpdateJob(newSchedul);
// 3. "once"가 아니고 "실행" 상태일 때만 Cron 스케줄을 등록합니다.
if (!"once".equals(newSchedul.getExcnCycle()) && Objects.equals("t", newSchedul.getSchedulExcnYn())) {
log.info("[Quartz-Insert] 신규 정기 스케줄({})을 Quartz에 등록합니다.", newSchedul.getSchedulId());
quartzSchedulService.scheduleCronJob(newSchedul);
}
}
return dto.getSchedulId();
}
...
}- Controller → wrkClctService.insert() 호출.
- wrkClctService.insert()에서:
- DB에 스케줄 정보 저장.
- 반복 스케줄이면 QuartzSchedulService.addOrUpdateSchedul() 호출해서 Quartz에 등록.
- Job service추가
@Slf4j
@Service
@RequiredArgsConstructor
public class QuartzSchedulService {
private final Scheduler scheduler;
/**
* Job 정보(JobDetail)를 Quartz DB에 등록하거나 갱신합니다.
* 이 메소드는 Trigger를 만들지 않습니다.
*/
public void addOrUpdateJob(SchedulDetailDto schedulDetail) {
try {
JobDetail jobDetail = buildJobDetail(schedulDetail);
// .storeDurably()가 설정되어 있으므로 Trigger 없이 Job 정보만 저장/갱신 가능
scheduler.addJob(jobDetail, true); // true: 이미 존재하면 덮어쓰기
log.info("Quartz Job 정보 등록/갱신 성공: {}", schedulDetail.getSchedulTitle());
} catch (SchedulerException e) {
log.error("Quartz Job 정보 등록/갱신 실패 (Schedul ID: {})", schedulDetail.getSchedulId(), e);
}
}
/**
* Cron Trigger를 등록하거나 업데이트합니다.
* 이 메소드가 호출되기 전에 해당 JobDetail이 이미 등록되어 있어야 합니다.
*/
public void scheduleCronJob(SchedulDetailDto schedulDetail) {
try {
Trigger trigger = buildTrigger(schedulDetail);
if (scheduler.checkExists(trigger.getKey())) {
scheduler.rescheduleJob(trigger.getKey(), trigger);
log.info("Quartz 스케줄(Cron) 업데이트 성공: {}", schedulDetail.getSchedulTitle());
} else {
scheduler.scheduleJob(trigger);
log.info("Quartz 스케줄(Cron) 신규 등록 성공: {}", schedulDetail.getSchedulTitle());
}
} catch (SchedulerException e) {
log.error("Quartz 스케줄(Cron) 등록/수정 실패 (Schedul ID: {})", schedulDetail.getSchedulId(), e);
}
}
/**
* Quartz에서 스케줄을 삭제합니다.
* @param schedulId 삭제할 스케줄의 ID
*/
public void deleteSchedul(String schedulId) {
try {
JobKey jobKey = new JobKey(schedulId);
if (scheduler.checkExists(jobKey)) {
scheduler.deleteJob(jobKey);
log.info("Quartz 스케줄 삭제 성공: {}", schedulId);
}
} catch (SchedulerException e) {
log.error("Quartz 스케줄 삭제 실패 (Schedul ID: {})", schedulId, e);
}
}
/**
* 특정 Job을 즉시 한 번 실행합니다. (수동 실행용)
* @param schedulId 즉시 실행할 스케줄(Job)의 ID
*/
public void triggerJobNow(String schedulId) {
try {
JobKey jobKey = new JobKey(schedulId);
// 해당 Job이 DB에 등록되어 있는지 먼저 확인
if (scheduler.checkExists(jobKey)) {
// 고유한 이름으로 일회성 트리거를 생성
String tempTriggerKey = "manual-trigger-" + UUID.randomUUID().toString();
Trigger manualTrigger = TriggerBuilder.newTrigger()
.forJob(jobKey) // 기존에 등록된 Job을 가르킴
.withIdentity(tempTriggerKey)
.withDescription("Manual execution for " + schedulId)
.startNow() // "지금 당장 시작하라"는 스케줄
.build();
// 스케줄러에 일회성 트리거를 등록하여 Job을 실행
scheduler.scheduleJob(manualTrigger);
log.info("Job 즉시 실행 요청 성공 (Schedul ID: {})", schedulId);
} else {
log.warn("Job을 찾을 수 없어 즉시 실행할 수 없습니다 (Schedul ID: {})", schedulId);
// 필요하다면 여기서 예외
// throw new RuntimeException("Job not found: " + schedulId);
}
} catch (SchedulerException e) {
log.error("Job 즉시 실행 요청 실패 (Schedul ID: {})", schedulId, e);
}
}
private JobDetail buildJobDetail(SchedulDetailDto schedulDetail) { // 파라미터 타입 변경
return JobBuilder.newJob(DataPlatformJob.class)
.withIdentity(schedulDetail.getSchedulId())
.withDescription(schedulDetail.getSchedulTitle())
.storeDurably()
.build();
}
private Trigger buildTrigger(SchedulDetailDto schedulDetail) { // 파라미터 타입 변경
return TriggerBuilder.newTrigger()
.forJob(schedulDetail.getSchedulId())
.withIdentity(schedulDetail.getSchedulId())
.withSchedule(CronScheduleBuilder.cronSchedule(createCronExpression(schedulDetail)))
.build();
}
private String createCronExpression(SchedulDetailDto schedulDetail) { // 파라미터 타입 변경
String sec = schedulDetail.getExcnSec();
String min = schedulDetail.getExcnMin();
String hour = schedulDetail.getExcnHour();
String dayOfMonth = "?";
String month = "*";
String dayOfWeek = "?";
switch (schedulDetail.getExcnCycle()) {
case "day": // 매일
dayOfMonth = "*";
break;
case "week": // 매주
dayOfWeek = String.valueOf(schedulDetail.getExcnWday()); // Integer를 String으로 변환
break;
case "month": // 매월
dayOfMonth = schedulDetail.getExcnDe();
break;
default:
// "once"나 다른 타입은 Quartz에 등록되지 않으므로, 이 메소드가 호출될 일이 없음
// 만약 호출된다면 에러를 던지거나 기본값 처리
log.warn("지원하지 않는 주기 '{}'에 대한 Cron 표현식 생성이 시도되었습니다.", schedulDetail.getExcnCycle());
dayOfMonth = "*"; // 안전을 위한 기본값
break;
}
String cron = String.format("%s %s %s %s %s %s", sec, min, hour, dayOfMonth, month, dayOfWeek);
log.debug("생성된 Cron: [{}] for Schedul: {}", cron, schedulDetail.getSchedulTitle());
return cron;
}
}- Quartz에 Job 등록/수정/삭제/즉시 실행 기능 제공.
- job 추가
import com.egis.dataplatform.clct.dms.wrk.clct.dao.WrkClctDao;
import com.egis.dataplatform.clct.dms.wrk.clct.dto.response.SchedulDetailDto;
import lombok.extern.slf4j.Slf4j;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Slf4j
@Component
@DisallowConcurrentExecution
public class DataPlatformJob implements Job {
// Job은 Spring 컨테이너와 라이프사이클이 다르므로, @Autowired를 통해 Bean을 주입받아야 합니다.
@Autowired
private WrkClctDao wrkClctDao;
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
String schedulId = context.getJobDetail().getKey().getName();
log.info(">>>>>> Quartz Job 실행 시작 (Schedul ID: {}) <<<<<<", schedulId);
try {
SchedulDetailDto detail = wrkClctDao.getSchedulDetailById(schedulId);
if (detail == null) {
throw new JobExecutionException("스케줄 정보를 찾을 수 없습니다: " + schedulId);
}
log.info("스케줄 제목: [{}], 연계 유형: [{}]", detail.getSchedulTitle(), detail.getClctLinkType());
switch (detail.getClctLinkType()) {
case "module":
log.info("모듈 실행: {}", detail.getModuleDfn());
// moduleService.execute(detail);
break;
case "file":
log.info("파일 수집: {}/{}", detail.getFileDir(), detail.getFileNm());
// fileService.execute(detail);
break;
case "db":
log.info("DB 수집: {}.{}.{}", detail.getDbIp(), detail.getSchmaNm(), detail.getTableNm());
// dbService.execute(detail);
break;
case "api":
log.info("API 호출: {}", detail.getApiUrl());
// apiService.execute(detail);
break;
default:
log.warn("지원하지 않는 연계 유형입니다: {}", detail.getClctLinkType());
}
} catch (Exception e) {
log.error("Job 실행 중 에러 발생 (Schedul ID: {})", schedulId, e);
throw new JobExecutionException(e);
}
log.info(">>>>>> Quartz Job 실행 완료 (Schedul ID: {}) <<<<<<", schedulId);
}
}- Job 실행 시점마다 DB에서 최신 정보를 다시 조회.
- 연계 타입(module, file, db, api)에 따라 분기 실행.
- 스케줄이 실행될 때 수행할 실제 비즈니스 로직을 execute() 메소드 안에 작성
- SchedulInitializer 추가
@Slf4j
@Component
@RequiredArgsConstructor
public class SchedulInitializer implements CommandLineRunner {
private final Scheduler scheduler;
private final WrkClctDao wrkClctDao;
private final QuartzSchedulService quartzSchedulService;
@Override
public void run(String... args) {
log.info("===== [Quartz] 스케줄러 동기화 시작 =====");
int registeredCount = 0; // 등록된 스케줄 개수를 셀 변수
try {
// 1. Quartz의 모든 기존 스케줄을 초기화
scheduler.clear();
// 2. DB에서 모든 스케줄의 '상세' 정보를 한번에 조회
List<SchedulDetailDto> allSchedulDetails = wrkClctDao.getAllSchedulDetails();
log.info("DB에서 총 {}개의 스케줄 상세 정보를 조회했습니다.", allSchedulDetails.size());
for (SchedulDetailDto detail : allSchedulDetails) {
if ("once".equals(detail.getExcnCycle())) {
continue;
}
if (Objects.equals("t", detail.getSchedulExcnYn())) {
try {
// 3. 올바른 메소드를 호출하고, 올바른 타입의 객체를 전달합니다.
quartzSchedulService.addOrUpdateSchedul(detail);
registeredCount++; // 등록 성공 시 카운트 증가
} catch (Exception e) {
log.error("[Quartz] 스케줄 '{}' 등록 중 에러 발생", detail.getSchedulId(), e);
}
}
}
log.info("총 {}개의 활성 스케줄을 Quartz에 등록 완료.", registeredCount);
} catch (Exception e) {
log.error("[Quartz] 스케줄러 초기화 중 심각한 에러 발생", e);
}
log.info("===== [Quartz] 스케줄러 동기화 완료 =====");
}
}- 애플리케이션 시작 시 DB ↔ Quartz 상태를 동기화.
- DB에 있는 활성화된 스케줄을 Quartz에 등록.
- 기존 Quartz Job/Trigger 모두 초기화 후 재등록.
- 필요 시 TriggerListener, JobListener 구현
- TriggerListener
- TriggerListener를 상속받아 구현한다.
- 메서드 이름으로 쉽게 알 수 있듯이 이벤트(ex. triggerFire, triggerMisfired) 발생시 호출되는 메서드들
- vetoJobExecution메서드는 해당 Trigger를 veto(거부, 금지) 시킬지 결정할 수 있는 메서드
- true이면 veto를 시켜서 Job이 실행되지 않고 false이면 veto를 시키지 않아 Job을 실행시킬 수 있어서 특정 조건을 넣어서 실행 여부를 결정 짓을 수 있는 메서드
- JobListener
- JobListener를 상속받아 구현한다.
- jobExecutionVetoed는 TriggersListener.vetoJobExecution() 메서드에서 veto를 시킨 경우 호출한다.
4. 디버깅 방법
방법은 크게 3가지다.
- 로그 확인
어플리케이션 시작 시나 스케줄 등록 API호출 시 콘솔에 출력되는 로그를 통해 확인이 가능하다
- 데이터베이스 테이블 직접 조회
Quartz는 모든 Job과 Trigger 정보를 DB에 저장하므로, DB테이블을 직접 조회하는 것이 가장 확실하다.
주로 아래의 3개 테이블을 확인하면 된다.
- QRTZ_JOB_DETAILS : 어떤 Job들이 등록되어 있는지 확인한다.
- QRTZ_TRIGGERS : 어떤 Trigger들이 등록되었고, 어떤 Job에 연결되어 있는지 확인한다.
- QRTZ_CRON_TRIGGERS : Cron 스케줄의 상세정보(Cron 표현식)을 확인한다.
확인하기 좋은 SQL문
SELECT
A.SCHED_NAME,
A.JOB_NAME,
A.JOB_GROUP,
A.DESCRIPTION AS JOB_DESCRIPTION,
B.TRIGGER_NAME,
B.TRIGGER_STATE,
B.NEXT_FIRE_TIME,
B.PREV_FIRE_TIME,
C.CRON_EXPRESSION
FROM
QRTZ_JOB_DETAILS A
JOIN
QRTZ_TRIGGERS B ON A.SCHED_NAME = B.SCHED_NAME AND A.JOB_NAME = B.JOB_NAME AND A.JOB_GROUP = B.JOB_GROUP
LEFT JOIN
QRTZ_CRON_TRIGGERS C ON B.SCHED_NAME = C.SCHED_NAME AND B.TRIGGER_NAME = C.TRIGGER_NAME AND B.TRIGGER_GROUP = C.TRIGGER_GROUP
ORDER BY
B.NEXT_FIRE_TIME ASC;위의 쿼리를 실행하면
- TRIGGER_STATE : WAITING (실행 대기 중), ACQUIRED (실행 준비 중), PAUSED (일시 정지) 등의 상태를 확인이 가능하다. WAITING이면 정상이다
- NEXT_FIRE_TIME: 다음 실행 예정 시간이 타임스탬프(timestamp) 형태로 표시된다.
- CRON_EXPRESSION: 등록된 Cron 표현식을 직접 확인이 가능하다.
- JMX(Java Management Extensions)을 통한 실시간 모니터링
Spring Boot 어플리케이션이 JMX 기능을 활성화하면, JConsole이나 VisualVM같은 모니터링 도구를 통해 실시간으로 Quartz 스케줄러의 상태를 볼 수 있다.
해당 기술스택은 사용하지 않아서 잘 모르겠지만 찾아보니 사용하는 것 같다.
추후에 운영환경에서 모니터링 도구가 필요하면 JMX 찾아보고 적용해봐야겠다.
5. Quartz의 스레드
Application.yml에 threadPool.threadCount: 10가 있는데 의미는
Quartz 스케줄러 내부에 “10개의 Worker Thread를 가진 스레드 풀을 만들라는 의미이다.
실행할 작업(Job)이 생기면 즉시 달려가서 처리하는 것
작업순서
- Quartz 스케줄러의 메인 스레드(QuartzSchedulerThread)는 clusterCheckinInterval은 주기적으로 데이터베이스(QRTZ_TRIGGERS 테이블)을 확인
- 스케줄러 메인 스레드는 3개의 Job을 작업큐에 넣는다.
- 각각의 스레드가 작업을 가져가서 execute() 메소드를 실행한다.
- 이 작업은 서로를 기다리지 않고 동시에(Concurrently) 병렬로 실행된다.
DB 락을 누가 먼저 차지하느냐에 따라 결정되는 무작위적인 경쟁 방식을 통해, 결과적으로 여러 노드에 작업이 분산되는 효과를 얻는 Quartz 클러스터링의 동작 방식
6. Quartz에서 말하는 클러스터(Cluster)
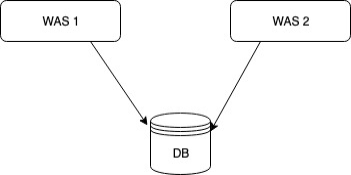
Quartz에서 말하는 클러스터란 이미지처럼 여러 개의 독립적인 애플리케이션 서버(WAS1, WAS2)가 하나의 공유 데이터베이스를 바라보며 동작하는 구조
- 이 두 개의 Quartz 인스턴스는 동일한 QRTZ_ 테이블들을 함께 사용합니다.
- 이것이 가능하려면 application.yml에 org.quartz.jobStore.isClustered: true 설정이 반드시 필요합니다.
6.1 로드 밸런싱
Quartz의 로드밸런싱은 “일감을 먼저 차지하기 위한 경쟁(Race to Work)” 방식으로 이루어진다.
네트워크 로드밸런서와는 다르게 Quartz는 WAS 1이 얼마나 바쁜지, WAS 2가 얼마나 한가한지 전혀 알지 못한다.
오직 “누가 먼저 데이터베이스 QRTZ_LOCKS 테이블에 락을 거는 데 성공하는가?” 라는, 순전히 타이밍에 의존하는 무작위적인(random) 경쟁으로 로드밸런싱이 이루어진다.
동작방식
- DB Lock : QRTZ_LOCKS라는 테이블에는 TRIGGERS_ACCESS와 같은 여러 종류의 락(Lock)레코드가 있다.
- 락 획득 경쟁 : clusterCheckinInterval마다 Job을 처리하는지 확인하기위해 QRTZ_LOCKS테이블의 TRIGGERS_ACCESS락을 획득하려고 시도한다.
- 락을 획득한 노드는 QRTZ_TRIGGERS 테이블을 스캔해 실행해야 할 작업을 찾는다. 그리고 그 작업의 상태를 ACQUIRED로 업데이트해 다른 노드가 가져가지 못하도록 표시한다.
- 락 해체 : 일감 선점이 끝나면 즉시 락을 해제하여 다른 노드가 락을 획득하고 남은 일감을 찾아갈 수 있도록 한다.
- 작업 실행 : 락 해체와는 별개로, 선점한 작업들을 자신의 스레드 풀에 할당하여 실행한다.
Tip!!
- Quartz의 핵심 개념은 **“무엇을 할 것인가 (Job)“**와 **“언제 할 것인가 (Trigger)“**를 분리하는 것
- Job (JobDetail): 실제 수행할 작업의 내용과 속성을 정의합니다. (예: “A라는 작업을 한다”)
- Trigger: Job을 실행시킬 시점이나 조건을 정의합니다. (예: “매일 5시에”, “매주 월요일에”, “지금 당장”)
- 하나의 Job에 여러 개의 Trigger를 붙일 수 있습니다. 예를 들어, 하나의 DataPlatformJob에 대해
- 매일 5시에 실행되는 Cron Trigger (정기 스케줄)
- 사용자가 ‘즉시 실행’ 버튼을 누를 때마다 생성되는 Simple Trigger (수동 실행)
- 이렇게 두 종류의 Trigger가 동시에 존재 가능
- .storeDurably()가 없다면: Job은 반드시 최소 하나 이상의 Trigger와 함께 등록한다. 만약 마지막 Trigger가 삭제되면 Job도 함께 삭제됩니다.
- .storeDurably()가 있다면: Job은 트리거가 하나도 없어도 DB에 독립적으로 존재할 수 있다. 이것이 바로 “실행 주기가 없는(once) 작업도 수동으로 실행”하거나, “정기 스케줄과 수동 실행을 모두 지원”하는 기능의 핵심
- 추후에 Muti WAS환경 적용에 필요하면 다음 글 참고하자 - Multi WAS 환경을 위한 Cluster 환경의 Quartz Job Scheduler 구현
Reference
Quartz Job Scheduler란? - Frank Oh
[Java] 스케줄링 & Spring Boot Quartz 이해하고 적용하기 -1 : 설정 및 간단예시 - Contributor9
Spring Boot + Quartz을 이용한 Job Scheduler 구현 (In-memory)
Multi WAS 환경을 위한 Cluster 환경의 Quartz Job Scheduler 구현