




KMP 알고리즘
알고리즘 문제 푼지 오래된 것 같아 leetcode를 기웃기웃 해보니
요런게 있다
leetcode에 study plan을 정해서 매일 문제 풀어보려고 하는데
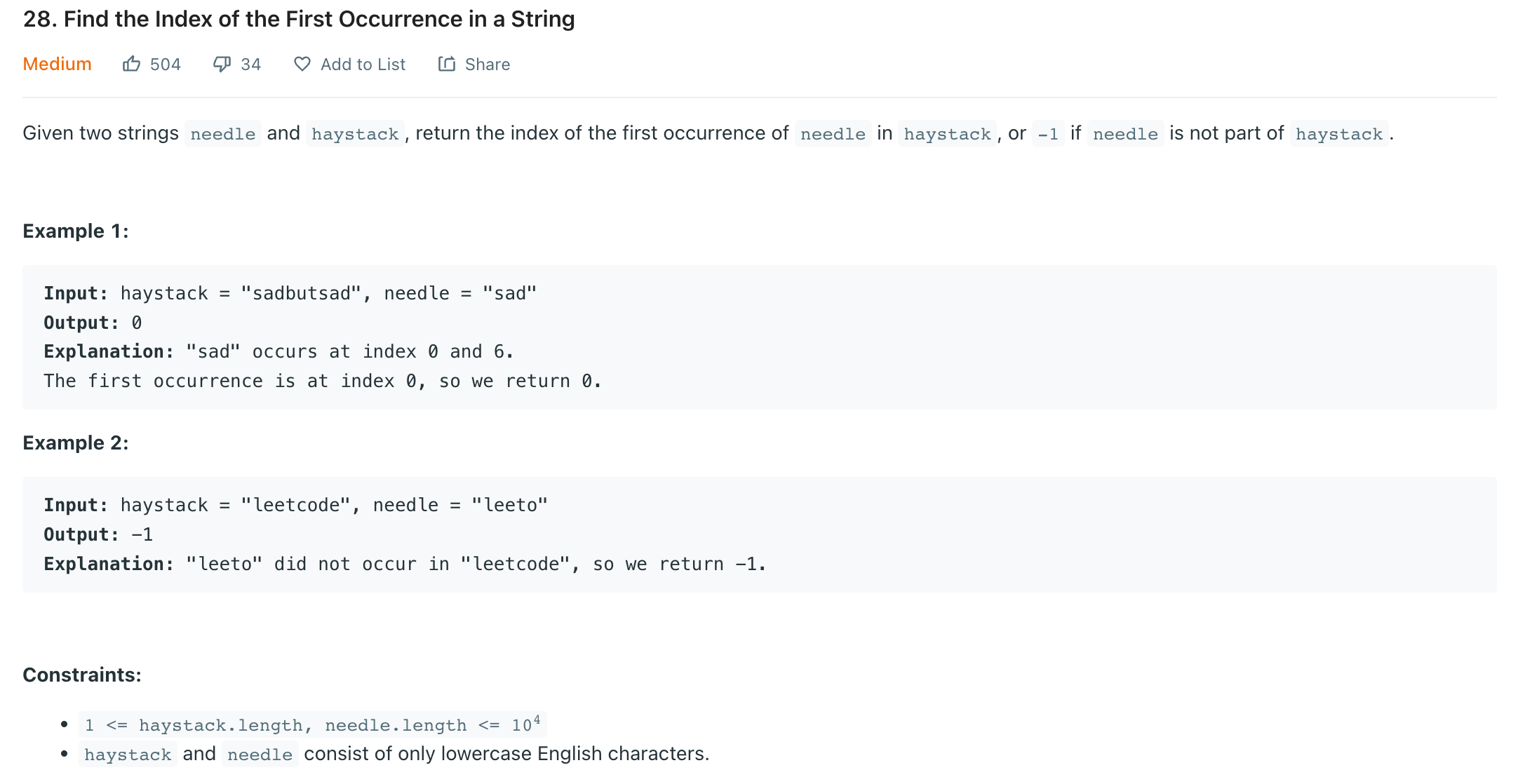
28번 문제 보고 kmp 알고리즘 정리하던게 생각나서 정리한다 하핳…
(28번은 그냥 java String 함수 indexOf써도 통과함)
KMP 알고리즘 이란?
접두사, 접미사를 활용(전처리)해 공통되는 부분을 건너 뛰어 모든 경우를 계산하지 않고
반복되는 연산을 줄여 매칭 문자열을 빠르게 계산하는 방법
일반적으로 문자열을 brute-force로 패턴 매칭을 할 경우에는 전부 순회하면서 확인하는 방식으로 동작해
시간 복잡도는 O(문자열 길이 * 패턴 길이) 가 된다
KMP 알고리즘은 어디서부터 어디까지 일치했는지에 대한 정보(전처리)를 토대로 다음 비교를 할 위치를 찾는 것이 핵심 아이디어다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| origin | a | a | b | a | a | b | b | a | a | b | a | a | b | c | b | c |
| pattern | a | a | b | a | a | b | c |
요렇게 불일치가 일어났을 때 다음 비교를
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| origin | a | a | b | a | a | b | b | a | a | b | a | a | b | c | b | c |
| pattern | a | a | b | a | a | b | c |
이렇게 수행이 된다.
KMP 알고리즘을 이해하기 위해선 몇가지 개념을 이해해야 한다.
접두사 : 단어 앞에 붙은 단어
접미사 : 단어 끝에 붙은 단어
실패 함수 : 문자열 일치 여부를 검사하다가, 불일치가 발생하면 어떤 조치를 취해야 하는지에 대한 함수
–> 문자 매칭에 실패하기 직전 상황에서, 접두사와 접미사가 일치하는 최대 길이
라고 이해하면 된다
아래 실패 함수의 예시를 확인해보자
origin text : aabaabbaabaabcbc
pattern : aabaabc
일 때 먼저 pattern의 실패함수 pi 를 구하면
| i | N[i] | 접두사이면서 접미사인 최대 문자열 | pi[i] |
|---|---|---|---|
| 0 | a | (없음) | 0 |
| 1 | aa | a | 1 |
| 2 | aab | (없음) | 0 |
| 3 | aaba | a | 1 |
| 4 | aabaa | aa | 2 |
| 5 | aabaab | aab | 3 |
| 6 | aabaabc | (없음) | 0 |
index 0 1 2 3 4 5 6
a a b a a b c
pi[] 0 1 0 1 2 3 0요런 형태로 pi[] 배열이 만들어 진다.
kmp알고리즘을 다시 한번 살펴보면
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| origin | a | a | b | a | a | b | b | a | a | b | a | a | b | c | b | c |
| pattern | a | a | b | a | a | b | c |
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| origin | a | a | b | a | a | b | b | a | a | b | a | a | b | c | b | c |
| pattern | a | a | b | a | a | b | c |
이런 모양으로 이전 까지 공통된 부분(aab)를 건너 뛴 채 비교하는 형태가 된다.
실제 소스에선 i = 6, j = 3을 카르키고 계속 진행되고,
값이 매칭 될 때마다 길이를 비교해 전체가 매칭되는지 확인한다
자세한 설명은 소스를 보고 확인해보자
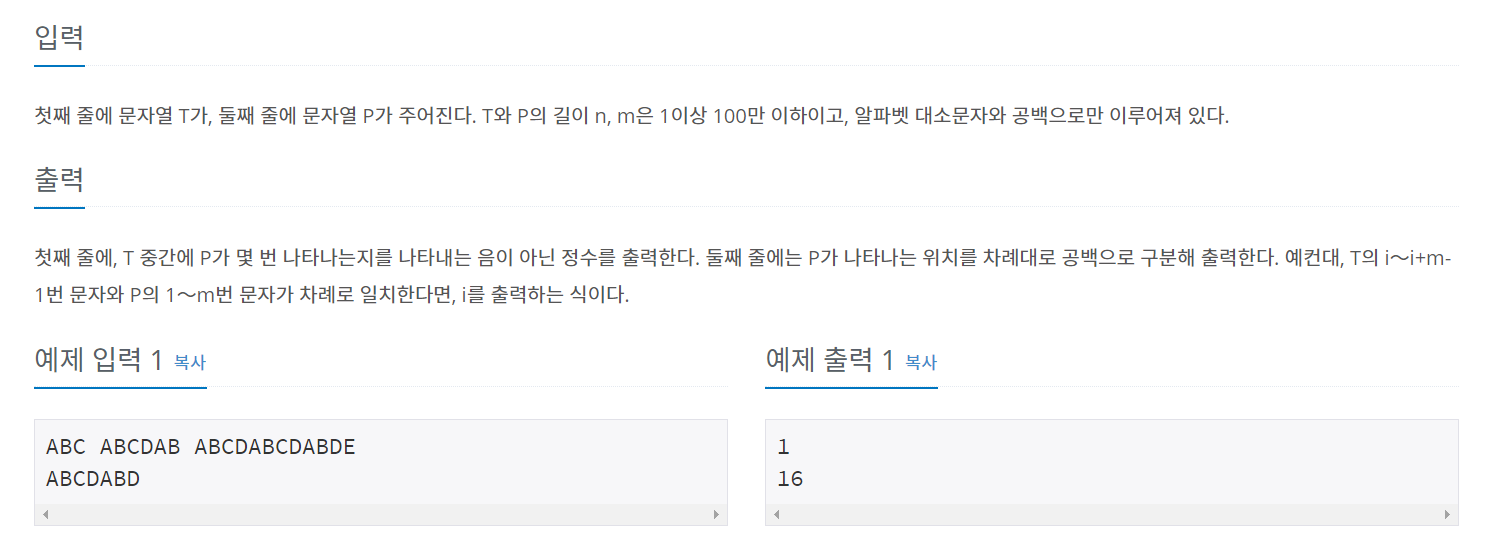
1786번 문제
package package33;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
public class num1786_finish {
static int cnt;
static ArrayList<Integer> result = new ArrayList<Integer>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String origin = br.readLine();
String pattern = br.readLine();
KMP(origin, pattern);
System.out.println(cnt);
for (int i = 0; i < cnt; i++)
System.out.println(result.get(i));
}
// 대응 된 문자수 matched만 유지하면서 orgin 모두 순회
// 글자마다 matched 적절히 갱신
public static void KMP(String origin, String pattern) {
int N = origin.length(), M = pattern.length();
int[] pi = getPartialMatch(pattern);
// 현재 대응된 글자 수
int j = 0;
for(int i=0; i< N; i++){ // i = begin + matched
while(j > 0 && origin.charAt(i) != pattern.charAt(j)) {
j = pi[j - 1];
}
//글자 대응 될 경우
if(origin.charAt(i) == pattern.charAt(j)){
// 전체 대응 (pattern 길이 확인)
if(j == M - 1){
++cnt;
result.add(i - j + 1);
j = pi[j];
} else {
j++;
}
}
}
}
// O(pattern 길이)
// 접두사, 접미사 일치 테이블 계산
public static int[] getPartialMatch(String pattern) {
// 초기화
int len = pattern.length();
int[] pi = new int[len];
int j = 0;
for (int i = 1; i < len; i++) {
// 맞는 위치가 나올 때 까지 j - 1칸의 공통 부분 위치로 이동
// j-1 까지 접두사와 접미사가 일치
while (j > 0 && pattern.charAt(i) != pattern.charAt(j)) {
j = pi[j - 1];
}
// 맞는 경우
if (pattern.charAt(i) == pattern.charAt(j))
// 공통 문자열의 길이는 j의 위치(배열의 index) + 1
pi[i] = ++j;
}
return pi;
}
}
풀이 방법
- 접두사도 되고 접미사도 되는 문자열의 최대 길이를 가진 실패 함수 배열 계산
- 구한 배열을 통해 문자열 매칭을 탐색할 때 점프를 해 계산
KMP 함수부터 간략히 설명하면
i는 원본 텍스트의 현재 비교위치, j는 패턴의 현재 비교위치를 나타내는 변수로
i와 j가 일치했을 때, 일치하지 않았을 때를 나눠서 생각해야한다.
일치 했을 때
-> i, j를 한칸 씩 오른쪽으로 이동 시키면서 비교
일치 하지 않았을 경우
-> 이전까지 접두사와 접미사가 일치한 부분 부터 확인하기 위해 (공통된 부분은 건너 뛰고)
-> pi[j-1]로 이동 후 비교한다
getPartialMatch함수는
KMP함수와 동일하게 동작하는데
j는 접두사의 위치, i는 접미사의 위치다
0번째 인덱스는 문자가 1개이기 때문에 제외하고 시작하기 위해서
i를 1부터 시작하고
동일한 글자가 있는지 전부 비교해서
pi배열을 완성시킨 후에 반환한다
| i | N[i] | 접두사이면서 접미사인 최대 문자열 | pi[i] |
|---|---|---|---|
| 0 | a | (없음) | 0 |
| 1 | aa | a | 1 |
| 2 | aab | (없음) | 0 |
| 3 | aaba | a | 1 |
| 4 | aabaa | aa | 2 |
| 5 | aabaab | aab | 3 |
| 6 | aabaabc | (없음) | 0 |
이 그림과 동일하게 값을 하나씩 넣으면서 동작해 pattern의 길이인 O(M) 만큼 돈다
Reference
알고리즘 문제 해결전략 (20.1 ~ 20.2) - 종만북
KMP 문자열 탐색 알고리즘이 동작하는 구체적인 원리 - injae Kim
[알고리즘] 문자열 매칭 알고리즘 KMP (Java) - 그릿 속의 해빗
[알고리즘 정리] KMP, 문자열 패턴 매칭 알고리즘
[알고리즘] KMP 알고리즘