




Elasticsearch 검색 품질 올리기
음… 데이터 적재는 어느정도 마무리 됐고, 기능도 어느정도 구현이 완료되고 검색 결과를 높이기 위한 방법을 계속 고민중이다.
텍스트만으로 검색 순위를 매기니 잘 되는거 같기도하고 아닌거 같기도 하고…
그러던 중 미션이 떨어졌다.
“Elasticsearch 스코어 알고리즘 특징 정리하고 알려주세요. 알아보고 geometry 데이터에 적합한 알고리즘 있으면 변경하고요.”
…머리 아프다. 후… 정리한다.
1. 검색 엔진은 어떻게 ‘관련도’를 알까? - 스코어링 알고리즘
Elasticsearch는 기본적으로 **“이 문서가 검색어와 얼마나 관련이 있는가?”**를 숫자로 표현하는데, 이것이 바로 스코어(_score)다.
검색 쿼리(query)에 대해 관련 있는 문서를 찾은 후, 이 관련성에 따라 정렬하기 위한 점수를 계산하는 규칙이 바로 스코어링 알고리즘이다.
“신나는 개발”처럼 여러 단어로 검색하면, “신나는”과 “개발” 각각에 대한 점수를 계산하고 합산한다. 여기서 각 단어를 **텀(term)**이라고 부른다.
추가로 search쿼리에 “explain”: true 옵션을 사용하면 내부에서 스코어를 어떤식으로 처리하고 있는지 확인 가능하다.
1.1 TF-IDF (Term Frequency - Inverse Document Frequency)
- TF(d,t) (단어 빈도, Term Frequency): 특정 문서(d) 안에서 검색어(t)가 얼마나 자주 등장하는가?
- ex) “강남 맛집”을 검색할 때, A문서에 ‘맛집’이 10번, B문서에 1번 나오면 A문서의 TF 점수가 더 높다.
- IDF (역문서 빈도, Inverse Document Frequency): 전체 문서들 중에서 이 검색어가 얼마나 희귀한 단어인가? (1/DF)
- ‘맛집’처럼 여러 문서에 자주 등장하는 단어는 IDF가 낮고(중요도↓), ‘누룽지통닭’처럼 희귀한 단어는 IDF가 높다(중요도↑).
- “the”, “a”, “is” 같은 불용어(stopword)가 낮은 점수를 받는 원리다.
- norm: 문서 길이 가중치 : 텀(term)이 등장하는 문서의 길이에 대한 가중치, 문서 길이가 길수록 검색 점수가 낮아진다.
- ex) “철수의 취미는 축구다” > “영희의 취미는 축구와 야구다”

결론: TF-IDF = (특정 문서 내 단어 등장 빈도) * (전체에서 단어의 희귀성 점수)
더 자세한 설명은 요기
1.2 BM25
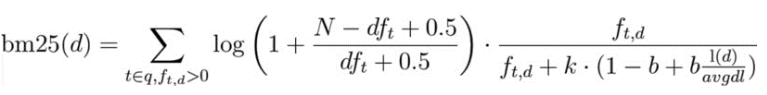
TF-IDF의 개선판이며, 현재 Elasticsearch(Lucene)의 기본(Default) 유사도 알고리즘이다. TF-IDF의 단점을 보완하여 훨씬 정교한 점수를 계산한다.
(Elastic search 5.0버전부터 기본 알고리즘이 BM25로 변경)
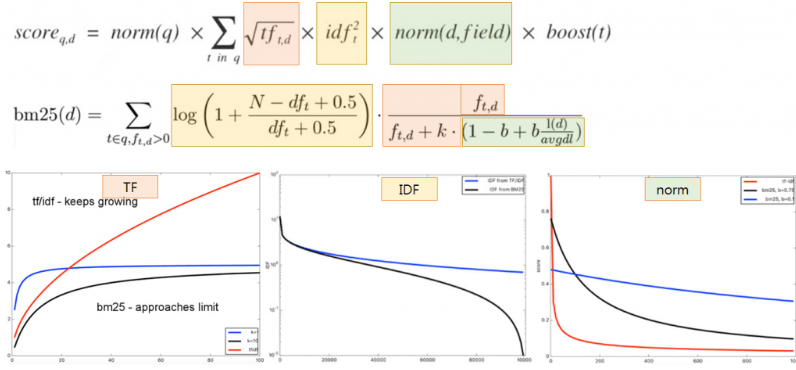
BM25가 더 똑똑한 이유
- TF(Term Frequency): 단어 빈도
- TF의 영향이 줄어든다.
- TF에서는 단어 빈도가 높아질수록 검색 점수도 지속적으로 높아지는 반면, BM25에서는 특정 값으로 수렴한다.
- IDF(Inverse Document Frequency): 문서 역빈도
- IDF의 영향이 커진다.
- BM25에서는 DF가 높아지면 검색 점수가 0으로 급격히 수렴하므로, 불용어가 검색 점수에 영향을 덜 미친다.
- Field-Length norm
- 문서 길이의 영향이 줄어든다.
- BM25에서는 문서의 평균 길이(avgdl)를 계산에 사용하며, 문서의 길이가 검색 점수에 영향을 덜 미친다.
1.2.1 단어 빈도(TF)의 포화도(Saturation) 개념 도입
TF-IDF는 ‘맛집’이라는 단어가 10번 나오면 1번 나온 것보다 10배 중요하다고 계산한다. 하지만 그렇지 않다.
어느 정도 이상 반복되면 중요도는 더 이상 크게 증가하지 않는다. BM25는 이처럼 단어 빈도가 점수에 미치는 영향이 점차 줄어들도록 설계되었다. (k1 파라미터로 조절)
1.2.2 문서 길이를 고려한 정규화
똑같이 ‘맛집’이 한 번 등장했더라도, 100글자짜리 짧은 문서에서의 ‘맛집’과 10,000글자짜리 긴 문서에서의 ‘맛집’은 중요도가 다르다. BM25는 문서 길이를 고려하여 점수를 보정한다. (b 파라미터로 조절)
결론: 대부분의 경우, 우리가 신경쓰지 않아도 BM25가 꽤 합리적인 텍스트 관련도 점수를 계산해준다.
2. 알고리즘 변경 방법
2.1 elastic search 제공 similarity
매핑(Mapping) 설정에서 필드별로 유사도(similarity) 모델을 지정할 수 있다.
- BM25: 기본값.
- classic: TF-IDF 알고리즘.
- boolean: 단순히 일치 여부만 따져서 점수를 1.0 또는 0으로 부여.
PUT my-index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"similarity": "BM25"
},
"content": {
"type": "text",
"similarity": "classic" // TF-IDF
},
"tag": {
"type": "text",
"similarity": "boolean"
}
}
}
}2.2 scripted similarity
스코어링 공식을 스크립트로 만들어서 적용하는 방법
TF, IDF 같은 저수준(low-level) 통계 정보에 직접 접근하여 점수를 계산
하지만 Script query 공식 문서의 최상단에 적혀있는 것처럼, script query는 성능이 좋지 않다.
결론
- 이 방법은 스코어링 모델의 핵심, 즉 엔진 자체를 교체하는 것과 같다.
- BM25가 우리 서비스 데이터에 근본적으로 맞지 않는다는 강력한 확신이 있을 때, 혹은 새로운 랭킹 논문을 구현해볼 때나 사용하는 전문가의 영역이다.
- Geo 데이터 튜닝을 위해 이걸 건드리는 건 올바른 접근이 아니다.
3. Geometry 데이터 기반 점수 조작 방법
핵심은 “위치 기반으로 점수를 어떻게 매길 것인가?”
BM25가 계산한 텍스트 점수는 그대로 활용하되, ‘거리’라는 요소를 추가해 최종 점수를 튜닝해야 한다.
3.1 function_score 활용
- Document의 score 계산 방식을 조작할 수 있게 해주는 쿼리
function_score는 기존 쿼리가 계산한 _score에 우리가 정의한 함수를 적용하여 최종 점수를 조작하는 기능이다.
- boost_factor
- 가장 간단한 함수 - 단순 상수를 곱하여 계산
- 필터를 이용하여 부스팅할 문서를 결정
- field_value_factor
- 숫자형 필드의 값을 스코어에 이용
- 대표적으로 카운트된 값 등의 숫자형 필드를 검색 결과에 이용할 때 사용
- script_score
- 스크립트 표현식을 사용하여 문서의 다른 숫자 필드 값에서 파생 된 계산으로 다른 쿼리를 래핑하고 선택적으로 점수를 사용자가 지정 가능
- 가장 자유도가 높은 스코어링 방식
- random_score
- 문서를 랜덤하게 정렬하고 싶을 때 사용
- seed 값을 동일하게 주면 동일한 결과가 나옴
- decay function
- 특정 필드의 값을 이용하여 스코어를 점진적으로 줄여 나가는 함수
Geo 데이터를 튜닝할 때는 주로 **Decay 함수(감쇠 함수)**를 사용한다.
- gauss: 기준점에서 멀어질수록 점수가 부드러운 정규분포 곡선을 그리며 감소 (가장 많이 사용).
- linear: 직선 형태로 일정하게 감소.
- exp: 지수 형태로 빠르게 감소.
Decay 함수 형식
{
“TYPE”: {
“FIELD_NAME”: {
“origin”: “…”,
“offset”: “…”,
“scale”: “…”,
“decay”: “…”
}
}
}- offset: orgin 으로부터 스코어가 줄어들지 않는 구간의 거리
- origin: 함수 곡선의 중심, 가장 스코어가 높은 지점
- scale: origin 으로부터 멀어지는 단위
- decay: scale 당 줄어드는 단위
-> scale & decay 이 두값의 조합으로 스코어 값이 줄어드는 기준을 정한다.
“Origin으로부터 Scale 거리만큼 떨어지면 점수가 Decay 배수가 된다.”
GET elk_local_data/_search?explain=true
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "카페",
"fields": ["name^3", "name.ngram"]
}
},
"functions": [
{
"gauss": {
"location": { // geo_point 타입 필드
"origin": "37.498, 127.027", // 기준점: 강남역 (사용자 위치)
"scale": "1km",
"offset": "200m",
"decay": 0.5
}
}
}
],
"score_mode": "multiply" // (텍스트 관련도 점수) * (거리 점수) = 최종 점수
}
},
"size": 1
}{
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": 17.346048,
"hits": [
{
"_shard": "[elk_local_data][0]",
"_node": "-gAJcFD2TJOXWRdG44RD-w",
"_index": "elk_local_data",
"_id": "07_24_04_P-3210000-3210000-101-2011-00185",
"_score": 17.346048,
"_source": {
"table_name": "ld_rest",
"host": {
"name": "bf1f1a8a8cb3"
},
"log": {
"file": {
"path": "/usr/share/logstash/input/elk_local_data_view_export.csv"
}
},
"y": 37.497819507625,
"message": """07_24_04_P-3210000-3210000-101-2011-00185,AAFS,일반음식점,카페 빛,127.026207052742,37.497819507625,ld_rest,
""",
"x": 127.026207052742,
"type": "AAFS",
"type_name": "일반음식점",
"@version": "1",
"name": "카페 빛",
"event": {
"original": """07_24_04_P-3210000-3210000-101-2011-00185,AAFS,일반음식점,카페 빛,127.026207052742,37.497819507625,ld_rest,
"""
},
"id": "07_24_04_P-3210000-3210000-101-2011-00185",
"geom": null,
"location": [
127.026207052742,
37.497819507625
],
"@timestamp": "2025-09-19T06:38:12.536564038Z"
},
"_explanation": {
"value": 17.346048,
"description": "function score, product of:",
"details": [
{
"value": 17.346048,
"description": "max of:",
"details": [
{
"value": 17.346048,
"description": "weight(name:카페 in 733403) [PerFieldSimilarity], result of:",
"details": [
{
"value": 17.346048,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 6.6000004,
"description": "boost",
"details": []
},
{
"value": 7.3263526,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 8231,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 12510467,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.3587309,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 2,
"description": "dl, length of field",
"details": []
},
{
"value": 1.2099988,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
},
{
"value": 9.54385,
"description": "weight(name.ngram:카페 in 733403) [PerFieldSimilarity], result of:",
"details": [
{
"value": 9.54385,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 5.681399,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 42588,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 12493742,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.76356435,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 1,
"description": "dl, length of field",
"details": []
},
{
"value": 93.290436,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 1,
"description": "min of:",
"details": [
{
"value": 1,
"description": "Function for field location:",
"details": [
{
"value": 1,
"description": "exp(-0.5*pow(MIN of: [Math.max(arcDistance(37.4978194758296, 127.02620700001717(=doc value),37.498, 127.027(=origin)) - 200.0(=offset), 0)],2.0)/721347.5204444818)",
"details": []
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}explain 결과 해설
- function score, product of:: score_mode가 multiply이므로, 이후 나오는 두 점수를 곱하겠다는 의미다.
- 첫 번째 value: 17.346048: multi_match 쿼리로 계산된 텍스트 관련도 점수다.
- max of:는 여러 필드 중 가장 높은 점수를 택했다는 의미.
- name 필드(boost 3배 적용)와 name.ngram 필드에서 각각 점수를 계산했고, 그중 name 필드의 점수가 더 높아 선택되었다.
- 두 번째 value: 1: functions에 정의한 gauss 함수의 결과 점수다.
- 결과 문서인 “카페 빛”의 위치가 origin(강남역)에서 offset으로 설정한 200m 이내에 있기 때문에, 거리로 인한 점수 감소가 전혀 없어 만점인 1.0이 나왔다.
- 최종 스코어: 텍스트 점수 17.346048 * 거리 점수 1.0 = 17.346048
만약 문서가 origin에서 1km 떨어져 있었다면 거리 점수는 decay 값인 0.5가 되어, 최종 스코어는 17.346048 * 0.5 = 8.673024가 되었을 것이다.
3.2 ETC
- distance_feature 쿼리: function_score보다 간단하게 거리 점수를 부여하고 싶을 때 bool 쿼리의 should 절에 넣어 사용할 수 있다. 사용법이 더 쉽지만 기능은 제한적이다.
- script_score 쿼리: Decay 함수로 표현하기 어려운 복잡한 거리 계산 로직이 필요할 때 사용한다. 스크립트를 직접 짜야 하므로 성능 저하가 발생할 수 있어 신중하게 사용해야 한다.
결론 및 정리
- Elasticsearch는 기본적으로 BM25 알고리즘을 사용하여 텍스트 관련도 점수를 매긴다. 대부분의 경우 매우 훌륭하게 동작한다.
- 해당 단어가 문서에서 많이 등장했다면 높은 점수를 주되,
- 문서의 길이가 너무 길다 싶으면 점수를 적당히 깎아주고,
- 똑같은 단어가 너무 많다 싶으면 적당히 또 깍아주고,
- 해당 단어가 혹시나 다른 문서에서도 흔하게 등장하고 있다면 대폭 깎는다.
- 스코어링 알고리즘 자체를 바꾸는 것(similarity 변경) 보다는
- 거리, 인기도, 최신순 등 비즈니스 로직을 점수에 반영하고 싶을 때는 function_score를 사용
- function_score와 gauss Decay 함수를 조합하면 **‘가까울수록 높은 점수’**를 주는 로직을 세밀하게 구현할 수 있다.
Reference
BM25 - Elasticsearch 5.0에서 검색하는 새로운 방법 - 송준이
[ ElasticSearch ] Score 계산과 function_score
Elasticsearch로 알아보는 BM25 알고리즘
Elasticsearch로 알아보는 BM25 알고리즘 2
[Elasticsearch 입문] BM25 랭킹 알고리즘 작성자 IML
[Python] IR 검색 알고리즘 - BM25 / 엘라스틱서치 랭킹 알고리즘 / 파이썬