




Elastic Search Analyzer 정리
1. 분석기(analyzer)
분석기는 **색인 시점(Index Time)**과 검색 시점(Search Time) 모두에서 작동하는 핵심 컴포넌트. 단순한 데이터 전처리를 넘어서 검색 품질과 성능을 결정하는 중요한 아키텍처 요소
색인 시점의 분석기는 단순히 텍스트를 나누는 도구가 아니라, 검색 품질을 결정짓는 정교한 ‘데이터 전처리 파이프라인’
이 파이프라인은 반드시 다음 순서로 실행된다.
- Character Filter : HTML태그나 불필요한 기호를 제거/변경 (옵션)
- Tokenizer : 텍스트를 실질적인 토큰 단위로 잘라낸다. (반드시 포함)
- Token Filter : 잘라진 토큰들을 소문자로 바꾸거나, 동의어를 추가하거나, 불필요한 단어를 버린다. (옵션)
이 3단계를 거쳐 최종 생성된 토큰들이 역인덱스에 저장되어 검색에 사용된다.
2. Character Filter
필터는 토크나이저에 전달되기 전에 문자 스트림을 사전 처리하는데 사용된다.
2.1 HTML 스트립 문자 필터
HTML요소를 제거하고 HTML 엔티티를 디코딩된 값으로 바꾼다.
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"html_strip"
]
}
}
}
}
}analyzer에 char_filter를 추가한다.
escaped_tags 파라미터로 특정 태그를 보존할 수 있으며, 프로덕션에서는 XSS 방지를 위해 신중하게 사용한다.
2.2 매핑 문자 필터
키와 값이 있는데 키와 동일한 문자열을 발견하면 해당 키와 연관된 값으로 대체한다.
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_mappings_char_filter"
]
}
},
"char_filter": {
"my_mappings_char_filter": {
"type": "mapping",
"mappings": [
":) => _happy_",
":( => _sad_"
]
}
}
}
}
}mapping 문자 필터를 선언하고 analyzer에 char_filter로 등록한다.
2.3 패턴 문자 필터
정규표현식을 사용해 지정된 대체 문자열로 대체한다.
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}3. Tokenizer
Character-Filtering을 통해 정제된 원문(문자열)에서 Token을 추출하는 과정
- Standard Tokenizer: 대부분의 언어에서 준수하게 동작하는 기본 토크나이저. 문법을 기반으로 단어를 분리하고 구두점 등을 제거
- Whitespace Tokenizer: 오직 공백(스페이스, 탭, 개행)만을 기준으로 텍스트를 분리 -> 가장 단순하지만, 구두점이 토큰에 포함될 수 있다.
- Letter Tokenizer: 문자가 아닌 것(공백, 숫자, 기호)을 기준으로 분리
- UAX URL Email Tokenizer: URL이나 이메일 주소를 하나의 토큰으로 인식하도록 특화
- Nori Tokenizer: 한글 형태소 분석을 위한 토크나이저 (후술)
4. Token Filter
토큰 단위의 처리이고, 빠른 검색을 위해 검색에 사용될 텀 들을 미리 분리해서 역 인덱스에 저장한다.
4.1 NGram
house를 min_gram : 2, max_gram : 3 으로 설정하면 다음과 같이 분석되어 총 7개의 토큰을 저장한다.
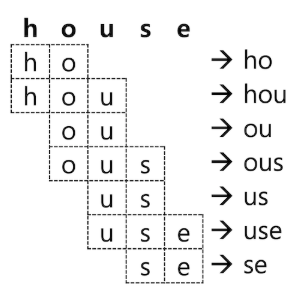
찾아보니 검색 결과를 예상하기 어렵기 때문에 일반적인 텍스트 검색에는 사용하지 않는 것이 좋다.
ngram을 사용하기에 적합한 사례는 카테고리 목록이나 태그 목록과 같이 전체 개수가 많지 않은 데이터 집단에 부분 일치나 오타 보정 검색에 적합
4.2 Edge NGram
텀 앞쪽의 ngram 만 저장
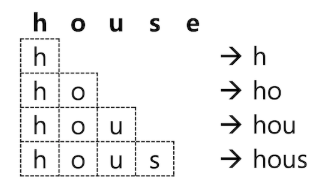
입력과 동시에 검색어 추천 기능을 구현하는데 최적화
4.3 shingle
문자가 아니라 단어 단위로 구성된 묶음을 Shingle 이라고 하며 “type”: “shingle” 토큰 필터의 이용이 가능
주로 구(phrase) 검색의 정확도를 높일 때 사용
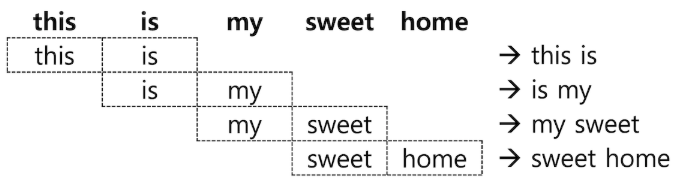
Tip!!
N-gram Tokenizer와 N-gram Token Filter와 헷갈릴 수 있는데 둘다 텍스트를 작은 단위로 나누는 역할을 하지만 언제, 무엇을 대상으로 작동하는지에서 결정적인 차이가 있다.
N-gram Tokenizer는 텍스트 전체를 하나의 긴 문자열로 보고, 지정된 크기의 n-gram으로 직접 잘라 토큰을 생성한다. 공백이나 구두점도 문자열의 일부로 취급한다.
장점은 단어의 경계를 무시하므로 중간 검색어나 오타에 강하다. -> 자동완성 기능 구현이나 단어 경계를 넘는 부분 검색, 하이픈이 중요한 데이터 검색에 에 매우 유용
단점은 공백이나 특수 문자를 포함한 의미 없는 토큰이 많이 생성될 수 있다.
N-gram Token Filter는 분리된 토큰에 대해 n-gram을 생성한다.
장점으로는 단어 내 부분 일치 검색 구현이 가능해지고, 의미 없는 공백이나 구두점 관련 n-gram이 생성되지 않아 더 깔끔하다.
단점으로는 단어 경계를 넘나드는 검색은 불가능하다. ex) ‘ch en’ -> ‘search engine’ x
사용하는 부분을 정리하면
- 지번/도로명 주소, 상품 코드 검색: N-gram Tokenizer (또는 Edge N-gram Tokenizer)가 더 적합 (’-’ 문자가 의미가 있기 때문에)
- 업소명 검색: Standard Tokenizer + N-gram Token Filter 조합. 의미 단위로 단어를 나누고(스타벅스, 강남역점), 각 단어 내에서 부분 검색(스타, 강남)을 허용하는 것이 가장 효율적
5. 한국어 분석기 (Nori)
- nori는 Elasticsearch가 공식 지원하는 한글 형태소 분석기
- 내부 사전을 참조하여 문장을 의미 단위(형태소)로 분해하고 품사를 태깅
- nori_part_of_speech 토큰 필터와 함께 사용하면 조사(‘은/는/이/가’), 어미 등 검색에 불필요한 품사를 제거하여 색인 효율과 검색 정확도를 크게 향상
- 토크나이저 : nori_tokenizer
- 토큰필터 : nori_part_of_speech(불필요한 품사 태그를 지정하여 삭제), nori_readingform(한자를 한글로 변환하는 필터
), nori_number(한글로 된 숫자를 숫자로 변환)
6. 역인덱싱
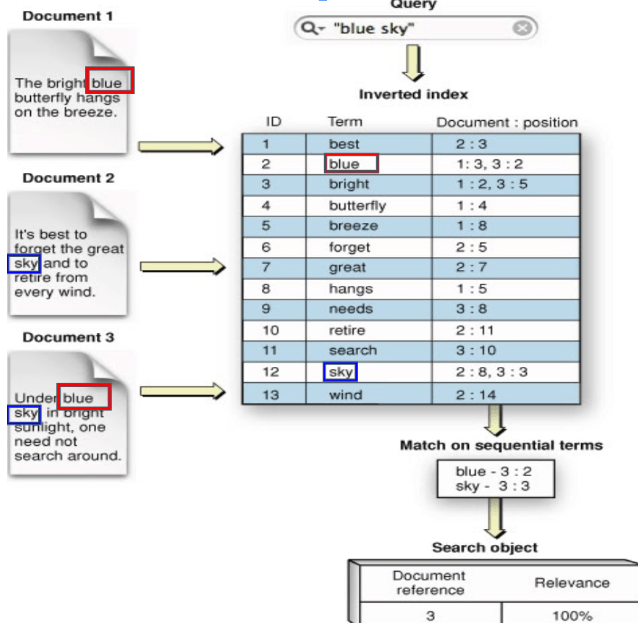
역인덱스는 용어(Term) → 문서 ID 리스트 매핑 구조로, 각 용어마다 다음 정보를 포함한다.
- 문서 빈도(Document Frequency): 용어가 나타나는 문서 수
- 용어 빈도(Term Frequency): 각 문서 내 용어 출현 횟수
- 위치 정보(Positions): 구문 검색을 위한 토큰 위치
- 오프셋 정보(Offsets): 하이라이팅을 위한 문자 위치
7. 분석기 API
- POST _analyze
- 필터와 토크나이저를 테스트하기 위해 API로 제공
- analyzer, field, character filter, tokenizer, filter 항목의 분석 결과를 볼 수 있음
| 파라미터 | deafult값 | 설명 |
|---|---|---|
| analyzer | 인덱스 명을 지정하여 api호출 시 세팅에 정의된 분석기를 지정하여 분석 가능 | |
| char_filter | tokenizer를 분석하기 전 문자를 전처리하여 나온 결과를 확인 가능 | |
| explain | false | 분석 결과의 과정 전체를 확인 |
| field | 인덱스명에 매핑된 필드명에 지정된 분석기의 분석 | |
| filter | filter로 지정된 분석기의 분석 | |
| normalizer | 필드 데이터 타입이 keyword인 항목의 테스트 변형을 위한 분석기로 변형된 결과 확인 | |
| tokenizer | 텍스트를 특정 규칙에 따라 토큰을 분할 한 결과 확인 |
GET carmaster.analyzer/_analyze
{
"char_filter": [
"html_strip"
],
"tokenizer": "whitespace",
"filter": [
"lowercase",
"trim"
],
"text": ["<b>싼타페</b> TM 디젤 2.5 터보"],
"explain": true
}8. 설정
- elastic search Dockerfile 수정 (설치)
nori는 Elastic Search에 기본 포함된 기능이 아닌 플러그인이라 설치부터 해줘야 한다.
Docker를 쓴다면 install 명령어를 한 줄 추가한다.
ARG ELASTIC_VERSION
# https://www.docker.elastic.co/
FROM docker.elastic.co/elasticsearch/elasticsearch:${ELASTIC_VERSION:-8.17.2}
# Add your elasticsearch plugins setup here
# Example: RUN elasticsearch-plugin install analysis-icu
RUN bin/elasticsearch-plugin install analysis-nori- template 업데이트 (분석기 커스텀 & 필드에 적용)
{
"index_patterns": ["elk_local_data*"],
"template": {
"settings": {
"index.max_ngram_diff": 15, // ngram 이나 edge_ngram 사용 시 max_gram과 min_gram의 차이 허용치
"analysis": {
"tokenizer": {
"address_ngram_tokenizer": { "type": "ngram", "min_gram": 2, "max_gram": 10, "token_chars": [ "letter", "digit" ] },
"korean_nori_tokenizer": { "type": "nori_tokenizer", "decompound_mode": "mixed" }
},
"filter": {
"business_name_ngram_filter": { "type": "ngram", "min_gram": 2, "max_gram": 7 },
"nori_pos_filter": { "type": "nori_part_of_speech", "stoptags": [ "E", "J", "IC", "MAJ", "MM", "SP", "SSC", "SSO", "SC", "SE", "XPN", "XSA", "XSN", "XSV" ] }
},
"analyzer": {
// 텍스트를 잘게 자른 후, lowercase 필터로 모두 소문자 처리하여 대소문자 구분 없이 검색되게 합니다.
"address_analyzer": { "tokenizer": "address_ngram_tokenizer", "filter": [ "lowercase" ] },
// 정확도 높은 한글 검색을 위한 표준 분석기입니다. nori로 의미 단위로 자르고, 불필요한 조사를 제거한 후, 소문자 처리합니다. 가장 기본적이고 중요한 분석기입니다.
"korean_nori_analyzer": { "tokenizer": "korean_nori_tokenizer", "filter": [ "lowercase", "nori_pos_filter" ] },
// 오타 및 부분 검색까지 지원하는 상호명 분석기, 형태소 분석 토큰과 ngram 토큰을 모두 갖게 되어 검색 유연성이 극대화
"business_name_analyzer": { "tokenizer": "korean_nori_tokenizer", "filter": [ "lowercase", "nori_pos_filter", "business_name_ngram_filter" ] }
}
}
},
"mappings": {
"properties": {
"id": { "type": "keyword" },
"type": { "type": "keyword" },
"type_name": {
"type": "text",
"fields": { "keyword": { "type": "keyword" } }
},
"name": {
"type": "text",
"analyzer": "korean_nori_analyzer",
"fields": {
"ngram": {
"type": "text",
"analyzer": "business_name_analyzer",
"search_analyzer": "korean_nori_analyzer"
},
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"x": { "type": "float" },
"y": { "type": "float" },
"location": { "type": "geo_point" },
"table_name": { "type": "keyword" },
"geom": {
"type": "text",
"index": false
}
}
}
}
}크게 두 부분으로 나뉜다.
- settings : 인덱스 레벨의 설정 정의, 커스텀 분석기를 정의하는 analysis부분이 핵심
- nori_pos_filter: nori가 분석한 토큰의 품사(Part-of-Speech)를 보고 불필요한 것을 제거하는 필터 ex - E(어미), J(조사)
- analyzer: 위에서 정의한 tokenizer와 filter 부품들을 조립하여 최종 ‘분석기 레시피’를 완성하는 곳
- mappings : 각 필드의 데이터 타입과 해당 필드에 어떤 분석기를 적용할지를 정의하는 데이터 스키마에 해당
- name: name 필드에 대한 매핑 정의입니다.
- type: “text”: 전문(Full-text) 검색이 가능한 텍스트 필드로 지정
- korean_nori_analyzer: 검색 시에는 이 분석기를 사용, “스타벅”이라고 검색하면, 검색어 자체를 ngram으로 쪼개지 않고 의미 있는 단위로만 분석
- business_name_analyzer : 색인 시에는 이 분석기 사용, 형태소 분석 토큰과 ngram 토큰 모두 저장
- name: name 필드에 대한 매핑 정의입니다.
다음과 같이 검색된다.
GET /_search
{
"query": {
"match": {
"name": "강남 스타벅스"
}
}
}- 기본 name필드는 색인 시와 검색 시 모두 korean_nori_analyzer가 사용
GET /_search
{
"query": {
"match": {
"name.ngram": "강남 스타벅스"
}
}
}name.ngram 이라는 서브 필드를 대상으로 검색 쿼리를 실행하면 색인은 business_name_analyzer이걸로 되는데 검색은 korean_nori_analyzer 분석
두 분석기 장점 활용
GET /_search
{
"query": {
"multi_match": {
"query": "강남 스타벅스",
"fields": [ "name", "name.ngram" ]
}
}
}검색어 “강남 스타벅스”을 korean_nori_analyzer로 분석하여 [강남, 스벅] 토큰으로 name 필드를 검색
검색어 “강남 스타벅스”을 korean_nori_analyzer(search_analyzer)로 분석하여 [강남, 스벅] 토큰으로 name.ngram 필드를 검색
-> Elasticsearch는 이 두 검색 결과를 합산하고, 더 높은 관련도 점수(_score)를 가진 문서를 상위에 노출
9. 동의어, 불용어 처리
- 동의어 -> config 폴더 하위에 동의어 사전을 구성해서 적용
- 불용어 -> config 폴더에 불용어 사전 파일 생성해 적용
Reference
Character filter - Elastic Search Document
HTML strip character filter - Elastic Search Document
Mapping character filter - Elastic Search Document
Pattern replace character filter - Elastic Search Document
검색엔진의 Analyzer, 형태소분석기 ≠ 토크나이저 - 요기요
[Elasticsearch] 분석기(analyzer)
6.5 토크나이저 - Tokenizer - Elastic 가이드북
6.6.4 NGram, Edge NGram, Shingle - Elastic 가이드북
6.7.2 노리 (nori) 한글 형태소 분석기 - Elastic 가이드북