




ELK Stack 정리 (개념부터 데이터 적재, 쿼리)
다른 부서에서 데이터 플랫폼 데이터를 사용하는데 검색 속도 향상을 위해 ELK에 데이터를 적재해 제공하는 업무가 주어졌다.
ELK 빠르게 정리하고 logstash를 통해 적재하는 방법을 정리한다.
1. 개요
ELK Stack은 데이터 수집, 분석, 시각화를 위한 세 가지 오픈소스 프로젝트(Elasticsearch, Logstash, Kibana)의 조합이다.
- Elasticsearch
- 고속 검색 및 분석을 위한 분산형 데이터 저장소
- 구조화된/비구조화된 데이터를 효율적으로 저장 및 쿼리 수행
- Apache Lucene 기반의 분산 검색 및 분석 엔진
- JSON 기반으로 데이터를 저장하고, 역인덱스(Inverted Index) 구조 덕분에 RDB의 LIKE와는 비교가 안 될 정도로 빠른 Full-text 검색이 가능하다
- 모든 기능은 RESTful API로 제어된다.
- Logstash
- 다양한 소스에서 데이터를 수집, 변환, 필터링
- 처리된 데이터를 Elasticsearch에 전송
- 다양한 소스에서 데이터를 수집(Input), 원하는 형태로 가공(Filter), 목적지로 전송(Output)
- Kibana
- Elasticsearch에 저장된 데이터를 시각화
- 대시보드 구성 및 실시간 로그 모니터링 기능 제공
- ELK Stack은 실시간 로그 분석, 애플리케이션 성능 모니터링(APM), 보안 이벤트 분석 등에 널리 사용됩니다.
ELK Stack은 실시간 로그 분석, 애플리케이션 성능 모니터링(APM), 보안 이벤트 분석 등에 널리 사용
시스템 구성
| 구성 | 요소 | 설명 접속 주소 |
|---|---|---|
| Kibana | Elasticsearch 데이터를 시각화하고 대시보드로 확인 가능 | http://192.168.50.248:5601 |
| Elasticsearch | 수집된 데이터를 저장하고 검색하는 저장소 역할 수행 | http://192.168.50.248:9200 |
| Logstash | 외부 데이터를 수집·가공해 Elasticsearch로 전달 | Docker 내부에서 파이프라인 실행 |
Elastic Search가 빠른 이유
결론부터 말하자면 역색인 때문이다.
역색인은 텍스트를 여러개의 키워드로 쪼개 저장하고, 키워드를 통해 문서를 찾아내는 방식이다.
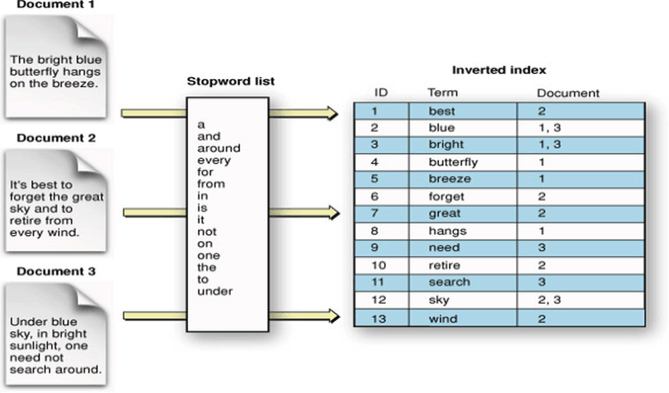
일반적인 RDBMS에는 단어가 100000번째 등장한다고 가정하면 100,000번째 행까지 탐색한다.
반면 Elastic Search의 경우 위의 그림과 같이 Document가 어디에 위치했는지 값을 가지고 있으므로 Inverted index를 통해 단어가 어디에 위치했는지 찾을 수 있다.
마치 해시 테이블을 사용하는 것 처럼 시간 복잡도가 거의 O(1)에 수렴한다.
관련된 공식문서
2. 데이터 수집 및 저장 절차
2.1 데이터 수집 파이프라인 (logstash 설정)
2.1.1 conf 파일 작성
- JDBC(DB -> Elasticsearch) 설정
설정파일 경로: /var/www/elk/docker-elk-main/logstash/pipeline/logstash_jdbc.conf
# Logstash 설정 파일 예시 (JDBC → Elasticsearch 적재)
input {
# [1] 입력(input) 단계: Logstash가 데이터를 어디서 읽을지 정의
jdbc {
# JDBC 드라이버 JAR 파일 경로 (PostgreSQL 기준)
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/postgre
sql-42.7.2.jar"
# JDBC 드라이버 클래스명 (PostgreSQL)
jdbc_driver_class => "org.postgresql.Driver"
# DB 접속 URL (호스트/포트/DB명)
jdbc_connection_string => "jdbc:postgresql://192.168.50.247:25432/ai"
# DB 접속 계정 정보
jdbc_user => "username"
jdbc_password => "password"
# 한번에 읽어올 데이터 건수 (페이징, 성능 최적화)
jdbc_fetch_size => 500
# 데이터 적재 주기 (cron 표현식, 매일 자정에 실행)
schedule => "0 0 * * *"
# 실제 쿼리문 (가져올 컬럼 명시)
statement => "
SELECT ogc_fid, fid, ufid, bjcd, name, divi, kind, serv, anno, nmly, rdnm,
bonu,
bunu, post, scls, fmta, gidn, layer, xval, yval FROM geoai.bldg;
ELK 데이터 적재 및 조회 매뉴얼 2
"
# 입력 데이터 타입 구분(선택, 있으면 downstream에서 조건 분기 가능)
type => "data"
}
}
filter {
# [2] 필터(filter) 단계: (필요시 데이터 가공/정제 가능)
}
output {
# [3] 출력(output) 단계: 데이터를 어디로 보낼지 정의
elasticsearch {
hosts => "http://192.168.50.248:9200"
user => "elastic"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
# [A] 날짜별 인덱스 생성 (예: building-2025.07.10)
index => "building-%{+YYYY.MM.dd}"
# [B] 단일 인덱스 사용 (항상 building에만 누적/갱신됨)
# index => "building"
# 문서 고유 ID 지정 (ufid 값 사용, 중복 방지)
document_id => "%{ufid}"
}
stdout {
# 수집된 데이터 콘솔 출력 (디버깅/개발용)
codec => rubydebug
}
}- JDBC 데이터 수집 준비 및 유의사항
- JDBC 드라이버 준비: 사용 DB에 맞는 JDBC JAR 파일을 Logstash 서버에 배치
- 적재 주기 설정: schedule 주기를 환경에 맞게 설정. (테스트: 1분, 운영: 하루 1회 등)
- 대용량(DB -> Elasticsearch) JDBC 설정
- 페이징 설정 추가
- docker 설정 시 logstash 메모리 값을 충분히 여유롭게 설정해줘야 한다.
input {
jdbc {
# --- DB 접속 정보 ---
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/postgresql-42.7.2.jar"
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://192.168.50.116:35432/gangnam"
jdbc_user => "user"
jdbc_password => "password"
# --- 쿼리 ---
statement => "SELECT jibun_address, ST_AsText(xgeometry) as xgeometry FROM public.elk_jibun_address_view"
# --- 페이징 설정 활성화 ---
jdbc_paging_enabled => true
# 페이지 당 가져올 데이터 수 (메모리가 충분하니 크게 설정)
jdbc_page_size => 50000
}
}
filter {
}
output {
elasticsearch {
hosts => ["http://192.168.50.248:9200"]
user => "elastic"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
index => "elk_jibun_address"
document_id => "%{jibun_address}"
}
# 진행 상황을 점(.)으로 확인
stdout {
codec => dots
}
}- CSV(CSV -> Elasticsearch) 설정
설정파일 경로: /var/www/elk/docker-elk-main/logstash/pipeline/logstash_food.conf
# Logstash 설정 파일 예시 (CSV 파일 → 파싱 → 가공 → Elasticsearch 저장)
input {
# [1] 입력(input) 단계: Logstash가 데이터를 어디서 읽을지 정의
file {
# 읽을 CSV 파일 경로 (Docker 컨테이너 내부 기준 경로)
path => "/usr/share/logstash/input/fulldata_07_24_04_P_일반음식점_utf8.csv"
# 파일 시작부터 읽기 (기존에 읽은 위치 정보가 없을 경우)
start_position => "beginning"
# 이전에 읽은 위치를 저장할 파일 경로 (중복 수집 방지)
sincedb_path => "/usr/share/logstash/state/.sincedb_food"
# 파일을 일반 텍스트 형식으로 읽기
codec => "plain"
}
}
filter {
# [2] 필터(filter) 단계: 읽은 데이터를 변환, 가공하는 단계
csv {
# CSV 파일 파싱 설정
separator => "," # 컬럼 구분자는 쉼표(,)
skip_header => true # 첫 줄(헤더 행)은 무시
columns => [ # 사용할 컬럼 목록 지정 (순서 중요)
"번호", "사업장명", "개방서비스명", "소재지전체주소", "도로명전체주소", "lon", "lat"
]
}
mutate {
# [2-1] mutate는 필드 값을 변형하는 데 사용되는 필터
convert => { "번호" => "integer" } # 번호를 정수로 변환
convert => { "lon" => "float" } # 경도(lon) 필드를 실수(float)로 변환
convert => { "lat" => "float" } # 위도(lat) 필드를 실수(float)로 변환
# 문자열 필드 값에서 앞뒤 공백 제거
strip => [
"사업장명", "개방서비스명", "소재지전체주소", "도로명전체주소"
]
}
}
output {
# [3] 출력(output) 단계: 데이터를 어디로 보낼지 정의
elasticsearch {
hosts => "http://192.168.50.248:9200"
user => "elastic"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
index => "logstash_food_index"
# Elasticsearch 응답 대기 시간 설정 (초 단위)
timeout => 60
}
stdout {
# 수집 데이터를 콘솔에 출력 (디버깅용)
codec => rubydebug
}
}- CSV 파일 준비 및 유의사항
- 인코딩: 반드시 UTF-8로 저장되어야 함
- 헤더 포함: skip_header => true 이므로 CSV 첫 줄에 컬럼명이 있어야 함.
- 불필요한 컬럼: columns 옵션에 지정된 컬럼만 추출되며, 나머지는 무시됨.
- 컬럼 순서 주의: 실제 CSV 파일의 컬럼 순서와 columns 설정의 순서가 일치해야 함.
- 파일 위치: Logstash 설정에 지정된 경로( /usr/share/logstash/input/ )에 CSV 파일이 존재해야 함.
2.2 pipelinse.yml에 설정 추가
설정 경로: /var/www/elk/docker-elk-main/logstash/config/pipelinse.yml
# Logstash에서 사용할 파이프라인 정의
- pipeline.id: logstash_food # 파이프라인 고유 ID (식별자 역할)
path.config: "/usr/share/logstash/pipeline/logstash_food.conf" # 파이프라인 설정 파일(.conf)의 경로
pipeline.ecs_compatibility: v8 # ECS(Elastic Common Schema) 호환성 설정 (v8 기준 구조 적용)
pipeline.batch.size: 1000 # 한 번에 처리할 이벤트(batch)의 최대 개수
pipeline.batch.delay: 5 # batch가 가득 차지 않았을 때 대기할 최대 시간(ms)2.3 Logstash Docker 컨테이너 재시작
# 실행 중인 컨테이너 목록 확인
docker ps
# Logstash 컨테이너 재시작
docker restart docker-elk-main_logstash_13. Query 정리
- 전체 문서 조회 (match_all)
GET logstash_food_index/_search
{
"query": {
"match_all": {} // 모든 문서를 검색합니다.
},
"size": 10 // 상위 10건만 조회합니다.
}- match 쿼리 (분석된 텍스트 검색
GET logstash_food_index/_search
{
"query": {
"match": {
"사업장명": "김밥" // '김밥'이라는 단어가 포함된 문서를 검색 (예: 김밥천국, 나라
김밥 등)
}
}
}- term 쿼리 (정확히 일치하는 값 검색)
GET logstash_food_index/_search
{
"query": {
"term": {
"개방서비스명.keyword": "일반음식점" // 분석되지 않은 정확한 값과 일치하는 문서만 검색 (.keyword 사용)
}
}
}- wildcard 쿼리 (와일드카드 검색 / LIKE와 유사)
GET logstash_food_index/_search
{
"query": {
"wildcard": {
"사업장명.keyword": "*김밥*" // '김밥'이 포함된 모든 문서를 검색합니다.
}
}
}- prefix 쿼리 (시작 텍스트 검색)
GET logstash_food_index/_search
{
"query": {
"prefix": {
"사업장명.keyword": "한솥" // '한솥'으로 시작하는 사업장명 검색 (예: 한솥도시락)
}
}
}- 위도/경도 범위 필터
GET logstash_food_index/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "lat": { "gte": 37.4, "lte": 37.6 } } }, // 위도 37.4~37.6 사이
{ "range": { "lon": { "gte": 126.8, "lte": 127.0 } } } // 경도 126.8~127.0 사이
]
}
}
}- 숫자/날짜 범위 검색 (range)
GET logstash_food_index/_search
{
"query": {
"range": {
"번호": {
"gte": 1000, // 1000 이상
"lte": 2000 // 2000 이하
}
}
}
}- exists (필드 존재 여부)
GET logstash_food_index/_search
{
"query": {
"exists": {
"field": "도로명전체주소" // 해당 필드가 존재하는 문서만 반환
}
}
}- 특정 필드로 정렬 + 상위 N건
GET logstash_food_index/_search
{
"query": {
"match_all": {}
},
"sort": [
{ "번호": "desc" } // 번호 필드 기준 내림차순 정렬
],
"size": 5 // 상위 5건만 조회
}- 집계 (aggregation)
GET logstash_food_index/_search
{
"size": 0, // 검색 결과는 반환하지 않음 (집계만 수행)
"aggs": {
"service_count": {
"terms": {
"field": "개방서비스명.keyword", // 개방서비스명별로 그룹핑
"size": 10 // 상위 10개만 반환
}
}
}
}- match_phrase (정확한 구절 검색)
GET logstash_food_index/_search
{
"query": {
"match_phrase": {
"사업장명": "김밥천국" // 단어가 연속적으로 등장해야 검색 (순서 일치)
}
}
}- bool 조합 (AND/OR/NOT)
GET logstash_food_index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "사업장명": "김밥" } }, // 김밥 포함
{ "term": { "개방서비스명.keyword": "일반음식점" } } // 일반음식점 일치
],
"must_not": [
{ "match": { "사업장명": "천국" } } // 천국 미포함
]
}
}
}- ⑬ fuzzy (오타 허용)
GET logstash_food_index/_search
{
"query": {
"fuzzy": {
"사업장명": {
"value": "깁밥", // 오타 포함 단어 입력
"fuzziness": "AUTO" // 자동 유사도 적용(오타 교정)
}
}
}
}- multi_match (여러 필드 동시 검색)
GET logstash_food_index/_search
{
"query": {
"multi_match": {
"query": "김밥", // 검색어
"fields": ["사업장명", "도로명전체주소"] // 두 필드에서 모두 검색
}
}
}- 여러 인덱스 동시 검색
GET /elk_local_data,elk_road_address/_search
{
"query": {
"match": {
"message": "error"
}
}
}