스프링 DB 2편 - 데이터 접근 활용 기술 정리
SQL Mapper 주요 기능
- SQL결과를 객체로 편리하게 매핑
- JDBC를 사용할 때 발생하는 여러 중복을 제거
ORM의 주요 기능
- 기본적인 SQL은 JPA가 대신 작성하고 처리
- JPA는 자바 진영의 ORM표준, Hibernete는 JPA에서 가장 많이 사용하는 구현체
- 스프링 데이터 JPA, QueryDSL은 JPA를 더 편리하게 사용하게 도와주는 프로젝트
1. JdbcTemplate
JdbcTemplate은 JDBC를 매우 편리하게 사용할 수 있게 도와준다.
장점
- 설정의 편리함
- JdbcTemplate는
spring-jdbc라이브러리에 포함되어 있는데, 이 라이브러리는 스프링으로 JDBC를 사용할 때 기본이 되는 라이브러리 - 별도의 복잡한 설정 없이 바로 사용 가능
- JdbcTemplate는
- 반복 문제 해결
- JdbcTemplate은 템플릿 콜백 패턴을 사용해서, JDBC를 직접 사용할 때 발생하는 대부분의 반복 작업을 대신 처리해준다.
- 개발자는 SQL을 작성하고, 전달할 파라미터를 정의하고, 응답 값을 매핑한다.
- 커넥션 획득
- statement 를 준비하고 실행
- 결과를 반복하도록 루프를 실행
- 커넥션 종료, statement , resultset 종료
- 트랜잭션 다루기 위한 커넥션 동기화
- 예외 발생시 스프링 예외 변환기 실행
하지만 동적 SQL을 해결하기 어렵다는 단점이 있다.
@Slf4j
@Repository
public class JdbcTemplateItemRepositoryV1 implements ItemRepository {
private final JdbcTemplate template;
public JdbcTemplateItemRepositoryV1(DataSource dataSource) {
this.template = new JdbcTemplate(dataSource);
}
@Override
public Item save(Item item) {
String sql = "insert into item (item_name, price, quantity) values ( ?, ?, ?)";
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(connection -> {
//자동 증가 키
PreparedStatement ps = connection.prepareStatement(sql, new String[]
{"id"});
ps.setString(1, item.getItemName());
ps.setInt(2, item.getPrice());
ps.setInt(3, item.getQuantity());
return ps;
}, keyHolder);
long key = keyHolder.getKey().longValue();
item.setId(key);
return item;
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
String sql = "update item set item_name=?, price=?, quantity=? where id =?";
template.update(sql,
updateParam.getItemName(),
updateParam.getPrice(),
updateParam.getQuantity(),
itemId);
}
@Override
public Optional<Item> findById(Long id) {
String sql = "select id, item_name, price, quantity from item where id = ?";
try {
Item item = template.queryForObject(sql, itemRowMapper(), id);
return Optional.of(item);
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
String sql = "select id, item_name, price, quantity from item";
//동적 쿼리
if (StringUtils.hasText(itemName) || maxPrice != null) {
sql += " where";
}
boolean andFlag = false;
List<Object> param = new ArrayList<>();
if (StringUtils.hasText(itemName)) {
sql += " item_name like concat('%',?,'%')";
param.add(itemName);
andFlag = true;
}
if (maxPrice != null) {
if (andFlag) {
sql += " and";
}
sql += " price <= ?";
param.add(maxPrice);
}
log.info("sql={}", sql);
return template.query(sql, itemRowMapper(), param.toArray());
}
private RowMapper<Item> itemRowMapper() {
return (rs, rowNum) -> {
Item item = new Item();
item.setId(rs.getLong("id"));
item.setItemName(rs.getString("item_name"));
item.setPrice(rs.getInt("price"));
item.setQuantity(rs.getInt("quantity"));
return item;
};
}
}- JDBCTemplate은 DataSource가 필요하다
- dataSource를 의존관계 주입을 받고 생성자 내부에서 JdbcTemplate를 생성한다.
- 관례상 이 방법을 많이 사용
template.update()
- 데이터를 변경할 때 사용한다.
- INSERT , UPDATE , DELETE SQL에 사용한다.
- template.update() 의 반환 값은 int 인데, 영향 받은 로우 수를 반환한다
template.queryForObject()
- 결과 로우가 하나일 때 사용한다.
- RowMapper 는 데이터베이스의 반환 결과인 ResultSet 을 객체로 변환한다.
template.query()
- 결과가 하나 이상일 때 사용한다.
- 마찬가지로 RowMapper 는 데이터베이스의 반환 결과인 ResultSet 을 객체로 변환한다.
동적 쿼리 문제
동적 쿼리가 언듯보면 쉬워 보이지만, 막상 개발해보면 다양한 상황
어떤 경우엔 where넣고, 어떤 경우엔 and 넣는지 모두 계산해야 한다.
DB 접근 설정
spring.profiles.active=local
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sasrc/main/resources/application.properties에 다음과 같이 설정하면 스프링 부트가 해당 설정을 사용해 커넥션 풀과 DataSource, 트랜잭션 매니저를 스프링 빈으로 자동 등록
JDBC Template - 이름 지정 바인딩
JdbcTemplate을 기본으로 사용하면 파라미터를 순서대로 바인딩 한다.
String sql = "update item set item_name=?, price=?, quantity=? where id=?";
template.update(sql,
itemName,
price,
quantity,
itemId);순서가 맞춰서 바인딩 되기 때문에 코드를 잘못 작성할 경우 큰 문제
=> JdbcTemplate는 이런 문제를 보완하기 위해 NamedParameterJdbcTemplate라는 이름 지정해서 파라미터를 바인딩하는 기능 제공
@Slf4j
@Repository
public class JdbcTemplateItemRepositoryV2 implements ItemRepository {
private final NamedParameterJdbcTemplate template;
public JdbcTemplateItemRepositoryV2(DataSource dataSource) {
this.template = new NamedParameterJdbcTemplate(dataSource);
}
@Override
public Item save(Item item) {
String sql = "insert into item (item_name, price, quantity) " +
"values (:itemName, :price, :quantity)";
SqlParameterSource param = new BeanPropertySqlParameterSource(item);
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(sql, param, keyHolder);
Long key = keyHolder.getKey().longValue();
item.setId(key);
return item;
}
...
}다음과 같이 ? 대신에 :파라미터이름을 받는다.
이름 지정 파라미터
파라미터를 전달하려면 Map 처럼 key , value 데이터 구조를 만들어서 전달해야 한다.
자주 사용하는 파라미터의 종류는 크게 3가지가 있다.
//단순히 Map 사용
Map<String, Object> param = Map.of("id", id);
Item item = template.queryForObject(sql, param, itemRowMapper());
// Map 과 유사한데, SQL 타입을 지정할 수 있는 등 SQL에 좀 더 특화된 기능을 제공
SqlParameterSource param = new MapSqlParameterSource()
.addValue("itemName", updateParam.getItemName())
// 는 자바 빈 프로퍼티 규약을 통해서 자동으로 파라미터 객체를 생성한다.
//예) (`getXxx()` -> xxx, `getItemName()` -> itemName)
SqlParameterSource param = new BeanPropertySqlParameterSource(item);
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(sql, param, keyHolder);BeanPropertyRowMapper
BeanPropertyRowMapper 는 ResultSet 의 결과를 받아서 자바빈 규약에 맞추어 데이터를 변환한다.
private RowMapper<Item> itemRowMapper() {
return (rs, rowNum) -> {
Item item = new Item();
item.setId(rs.getLong("id"));
item.setItemName(rs.getString("item_name"));
item.setPrice(rs.getInt("price"));
item.setQuantity(rs.getInt("quantity"));
return item;
};
}
private RowMapper<Item> itemRowMapper() {
return BeanPropertyRowMapper.newInstance(Item.class); //camel 변환 지원
}BeanPropertyRowMapper 는 언더스코어 표기법을 카멜로 자동 변환해준다
JdbcTemplate - SimpleJdbcInsert
Jdbc Template는 InsertSQL을 직접 작성하지 않아도 되도록 SimpleJdbcInsert라는 편리한 기능 제공
@Slf4j
@Repository
public class JdbcTemplateItemRepositoryV3 implements ItemRepository {
private final NamedParameterJdbcTemplate template;
private final SimpleJdbcInsert jdbcInsert;
public JdbcTemplateItemRepositoryV3(DataSource dataSource) {
this.template = new NamedParameterJdbcTemplate(dataSource);
this.jdbcInsert = new SimpleJdbcInsert(dataSource)
.withTableName("item")
.usingGeneratedKeyColumns("id");
// .usingColumns("item_name", "price", "quantity"); //생략 가능
}
@Override
public Item save(Item item) {
SqlParameterSource param = new BeanPropertySqlParameterSource(item);
Number key = jdbcInsert.executeAndReturnKey(param);
item.setId(key.longValue());
return item;
}
...
}SimpleJdbcInsert 는 생성 시점에 데이터베이스 테이블의 메타 데이터를 조회한다. 따라서 어떤 컬럼이 있는지 확인 할 수 있으므로 usingColumns 을 생략할 수 있다.
SQL을 실행하면 생성된 키 값을 반환해 편리하게 조회가 가능하다.
정리
JdbcTemplate이 제공하는 주요 기능은 다음과 같다.
- JdbcTemplate
- 순서 기반 파라미터 바인딩을 지원한다.
- NamedParameterJdbcTemplate
- 이름 기반 파라미터 바인딩을 지원한다. (권장)
- SimpleJdbcInsert
- INSERT SQL을 편리하게 사용할 수 있다.
- SimpleJdbcCall
- 스토어드 프로시저를 편리하게 호출할 수 있다
JdbcTemplate의 단점이 있는데, 바로 동적 쿼리 문제를 해결하지 못한다.
SQL을 자바 코드로 작성하기 때문에 SQL라인이 코드를 넘어갈 때 마다 문자 더하기를 해줘야 한다.
동적 쿼리 문제를 해결하면서 동시에 SQL을 편리하게 작성하는데 도와주는 기술이 MyBatis
2. 데이터 접근 기술 - 테스트
src/test/resources/application.properties에도 설정을 추가한다.
@SpringBootTest
class ItemRepositoryTest {}
@Slf4j
//@Import(MemoryConfig.class)
//@Import(JdbcTemplateV1Config.class)
//@Import(JdbcTemplateV2Config.class)
@Import(JdbcTemplateV3Config.class)
@SpringBootApplication(scanBasePackages = "hello.itemservice.web")
public class ItemServiceApplication {}@SpringBootTest설정이 있으면 @SpringBootApplication을 찾아서 설정으로 사용한다.
실제 DB를 연동해서 실행하면 기존 데이터가 테스트에 영향을 준다.
이런 문제를 해결하려면 테스트를 다른 환경과 철저하게 분리해야 한다.
가장 간단한 방법은 테스트 전용 데이터베이스를 별도로 운영하는 것이다.
H2 데이터베이스를 용도에 따라 2가지로 구분하면 된다.
- jdbc:h2:tcp://localhost/~/test local에서 접근하는 서버 전용 데이터베이스
- jdbc:h2:tcp://localhost/~/testcase test 케이스에서 사용하는 전용 데이터베이스
테스트에서 매우 중요한 원칙은 다음과 같다.
테스트는 다른 테스트와 격리해야 한다.
테스트는 반복해서 실행할 수 있어야 한다.
테스트가 끝날 때 마다 추가한 데이터에 DELETE SQL 을 사용할 수도 있지만, 비정상적으로 종료됐을 때 DELETE SQL 을 호출하지 못할 수 도 있다.
테스트 데이터 롤백
테스트가 끝나고 나서 트랜잭션을 강제로 롤백해버리면 데이터가 깔끔하게 제거된다.
DataSource와 TransactionManager는 스프링 부트가 자동으로 의존성 주입을 해준다.
테스트를 하면서 데이터를 이미 저장했는데, 중간에 테스트가 실패해서 롤백을 호출하지 못해도 트랜잭션을 커밋하지 않았기 때문에 데이터베이스에 해당 데이터가 반영되지 않는다.
//트랜잭션 관련 코드
@Autowired
PlatformTransactionManager transactionManager;
TransactionStatus status;
@BeforeEach
void beforeEach() {
//트랜잭션 시작
status = transactionManager.getTransaction(new
DefaultTransactionDefinition());
}
@AfterEach
void afterEach() {
//MemoryItemRepository 의 경우 제한적으로 사용
if (itemRepository instanceof MemoryItemRepository) {
((MemoryItemRepository) itemRepository).clearStore();
}
//트랜잭션 롤백
transactionManager.rollback(status);
}@Transactional
@Transactional은 테스트에서 사용하면 특별하게 동작한다.
@Transactional이 테스트에 있으며 스프링은 테스트를 트랜잭션 안에서 실행하고, 테스트가 끝나면 트랜잭션을 자동으로 롤백
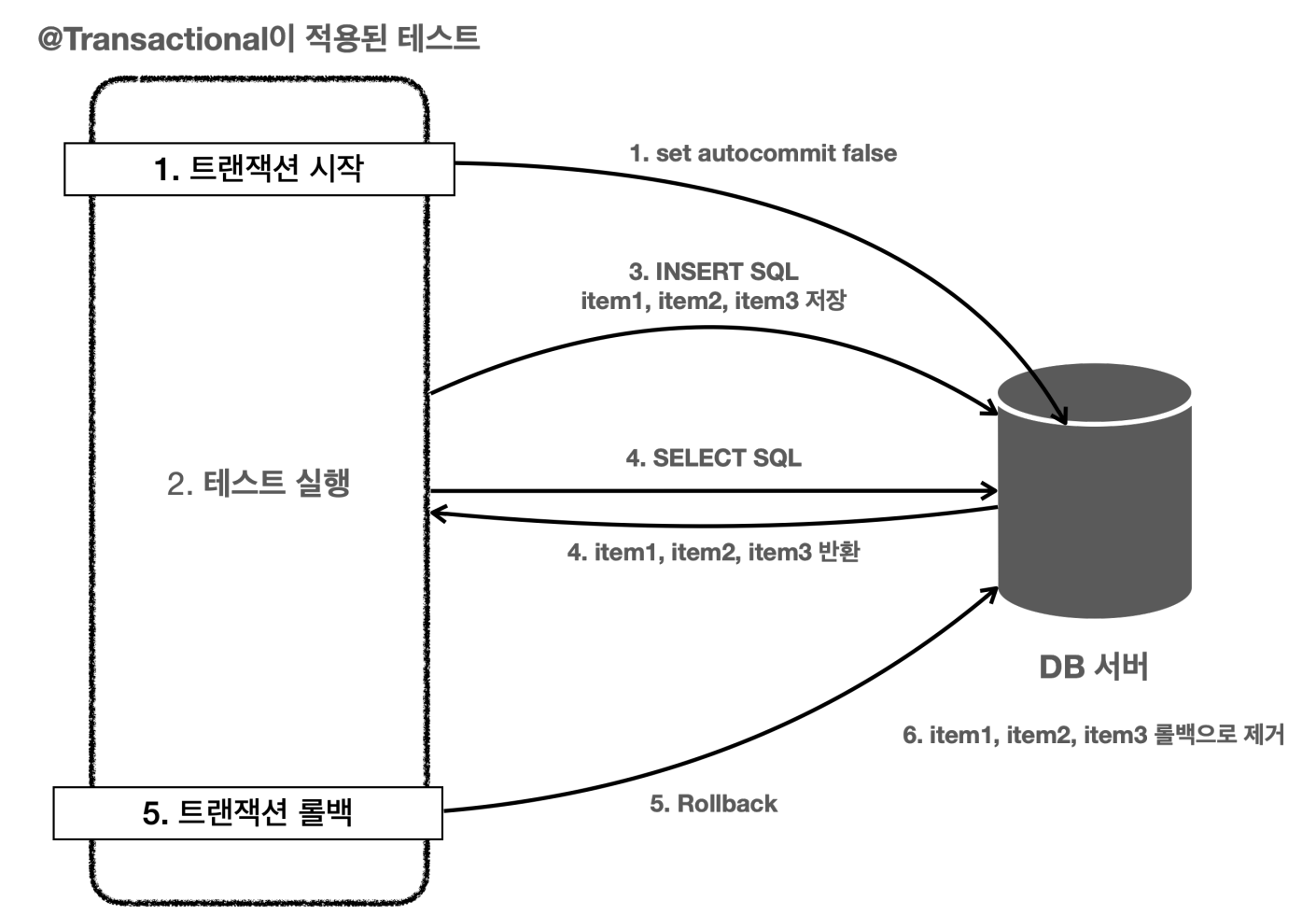
- 테스트에 @Transactional 애노테이션이 테스트 메서드나 클래스에 있으면 먼저 트랜잭션을 시작한다
- @Transactional 이 테스트에 있으면 테스트가 끝날때 트랜잭션을 강제로 롤백한다
- 테스트에서 트랜 잭션을 실행하면 테스트 실행이 종료될 때 까지 테스트가 실행하는 모든 코드가 같은 트랜잭션 범위에 들어간다고 이해 (추후 설명)
강제로 커밋하기 - @Commit
정말 가끔은 데이터베이스에 데이터가 잘 보관되었는지 최종 결과를 눈으로 확인하고 싶을 때도 있다. @Commit 이나 @Rollback(value = false) 를 붙여주면 된다.
//@Rollback(value = false)
@Commit
@Transactional
@SpringBootTest
class ItemRepositoryTest {}임베디드 모드 테스트
- H2 데이터베이스는 자바로 개발되어 있고, JVM안에서 메모리 모드로 동작하는 특별한 기능을 제공
- 애플리케이션을 실행할 때 H2 데이터베이스도 해당 JVM 메모리에 포함해서 함께 실행 가능
- 애플리케이션이 종료되면 임베디드 모드로 동작하는 H2 데이터베이스도 함께 종료되고, 데이터도 모두 사라진다.
@Import(JdbcTemplateV3Config.class)
@SpringBootApplication(scanBasePackages = "hello.itemservice.web")
public class ItemServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ItemServiceApplication.class, args);
}
@Bean
@Profile("test") // 프로필이 test 인 경우에만 데이터소스를 스프링 빈으로 등록
public DataSource dataSource() {
log.info("메모리 데이터베이스 초기화");
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:mem:db;DB_CLOSE_DELAY=-1");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
}jdbc:h2:mem:db : 이 부분이 중요하다. 데이터소스를 만들때 이렇게 적으면 임베디드 모드(메모리 모드)로 동작하는 H2 데이터베이스를 사용할 수 있다.
DB_CLOSE_DELAY=-1 : 임베디드 모드에서는 데이터베이스 커넥션 연결이 모두 끊어지면 데이터베이스도 종료되는데, 그것을 방지하는 설정이다.
스프링 부트는 SQL 스크립트를 실행해서 애플리케이션 로딩 시점에 데이터베이스를 초기화하는 기능을 제공한다.
SQL을 작성하고 src/test/resources/schema.sql에 생성한다.
drop table if exists item CASCADE;
create table item
(
id bigint generated by default as identity,
item_name varchar(10),
price integer,
quantity integer,
primary key (id)
);
스프링 부트는 데이터베이스에 대한 별다른 설정이 없으면 임베디드 데이터베이스를 사용
메모리 DB용 데이터소스 설정과 아래의 application.properties의 데이터베이스 설정정보도 지워도 된다.
spring.datasource.url=jdbc:h2:tcp://localhost/~/testcase
spring.datasource.username=sa
jdbcTemplate sql log이렇게 별다른 정보가 없으면 스프링 부트는 임베디드 모드로 접근하는 데이터소스(DataSource)를 만들어서 제공한다.
3. MyBatis
SQL Mapper
- JdbcTemplate와 비교해서 MyBatis의 가장 매력적인 점은 SQL을 XML에 편리하게 작성
- 동적 쿼리를 매우 편리하게 작성
- JDBC는 스프링 내장 기능, 별도의 설정 없이 사용 가능
- MyBatis는 약간의 설정 필요
- 스프링 부트가 버전관리해주는 공식 라이브러리가 아니라 버전을 따로 관리해야 한다.
application.properties은 main, test 모두 수정해야 한다.
spring.profiles.active=local
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sa
logging.level.org.springframework.jdbc=debug
# MyBatis
mybatis.type-aliases-package=hello.itemservice.domain
# 언더바를 카멜로 자동 변경
mybatis.configurationmap-underscore-to-camel-case=true
# MyBatis에서 실행되는 쿼리 로그를 확인
logging.level.hello.itemservice.repository.mybatis=tracemybatis.type-aliases-package
- 타입 정보를 사용할 때는 패키지 이름을 적어야 하는데, 여기에 명시하면 패키지 이름 생략 가능
- 지정한 패키지와 하위 패키지 자동으로 인식
- 여러 위치 지정 시
,,;으로 구분
mybatis.configuration.map-underscore-to-camel-case
- JdbcTemplate의 BeanPropertyRowMapper 에서 처럼 언더바를 카멜로 자동 변경해주는 기능을 활성화 한다. 바로 다음에 설명하는 관례의 불일치 내용을 참고하자.
logging.level.hello.itemservice.repository.mybatis=trace
- MyBatis에서 실행되는 쿼리 로그를 확인할 수 있다.
package hello.itemservice.repository.mybatis;
@Mapper
public interface ItemMapper {
void save(Item item);
void update(@Param("id") Long id, @Param ("updateParam") ItemUpdateDto updateParam);
Optional<Item> findById(Long id);
List<Item> findAll(ItemSearchCond itemSearch);
}- 마이바티스 매핑 XML을 호출해주는 매퍼 인터페이스
- @Mapper` 애노테이션을 붙여야 함
- 이 인터페이스의 메서드를 호출하면 다음에 보이는
xml의 해당 SQL을 실행하고 결과를 돌려준다.
<!-- src/main/resources/hello/itemservice/repository/mybatis/ItemMapper.xml-->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="hello.itemservice.repository.mybatis.ItemMapper">
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into item (item_name, price, quantity)
values (#{itemName}, #{price}, #{quantity})
</insert>
<update id="update">
update item
set item_name=#{updateParam.itemName},
price=#{updateParam.price},
quantity=#{updateParam.quantity}
where id = #{id}
</update>
<select id="findById" resultType="Item">
select id, item_name, price, quantity
from item
where id = #{id}
</select>
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%',#{itemName},'%')
</if>
<if test="maxPrice != null">
and price <= #{maxPrice}
</if>
</where>
</select>
</mapper>- xml은
resources아래 경로에 만들어준다. - 원래 resultType에 패키지 명 다 적어야 하는데
mybatis.type-aliases-package로 해결 (클래스 이름만 적어준다.) <=는 충돌이 일어나서<=로 적어준다.- 기본적으로
mapper와xml의 경로를 맞춰준다. (패키지 경로 동일하게) - xml원하는 위치에 두고 싶으면
application.properties에 다음과 같이 설정
=>mybatis.mapper-locations=classpath:mapper/**/*.xml
=> 이렇게 하면resources/mapper를 포함한 그 하위 폴더에 있는 XML을 XML 매핑 파일로 인식
=> 테스트의application.properties파일도 함께 수정해야 테스트를 실행할 때 인식
void save(Item item);
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into item (item_name, price, quantity)
values (#{itemName}, #{price}, #{quantity})
</insert>insert
- 파라미터는
#{}문법을 사용 ->PreparedStatement를 사용, JDBC의 ? 치환이라 생각 - useGeneratedKeys
는 데이터베이스가 키를 생성해 주는IDENTITY` 전략일 때 사용 keyProperty는 생성되는 키의 속성 이름을 지정
void update(@Param("id") Long id, @Param("updateParam") ItemUpdateDto
updateParam);
<update id="update">
update item
set item_name=#{updateParam.itemName},
price=#{updateParam.price},
quantity=#{updateParam.quantity}
where id = #{id}
</update>update
- 파라미터가 1개만 있으면
@Param을 지정하지 않아도 되지만, 파라미터가 2개 이상이면@Param으로 이름을 지정해서 파라미터를 구분
Optional<Item> findById(Long id);
<select id="findById" resultType="Item">
select id, item_name, price, quantity
from item
where id = #{id}
</select>select
resultType은 반환 타입을 명시- 앞서 application.properties 에 mybatis.type-aliasespackage=hello.itemservice.domain 속성을 지정해 모든 패키지 명을 다 적지는 않아도 된다.
- 그렇지 않으면 모든 패키지 명을 다 적어야 한다.
List<Item> findAll(ItemSearchCond itemSearch);
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%',#{itemName},'%')
</if>
<if test="maxPrice != null">
and price <= #{maxPrice}
</if>
</where>
</select>select all
<where>,<if>같은 동적 쿼리 문법을 통해 편리한 동적 쿼리를 지원` 는 해당 조건이 만족하면 구문을 추가 <where>은 적절하게where문장을 만들어준다.- < : < / > : > / & : & 치환하여 사용
치환하지 않고 사용하고 싶으면 XML CDATA사용한다.
다만 이 구문 안에서는 XML TAG가 단순 문자로 인식하기 때문에 <if>, <where> 등이 적용되지 않는다.
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%',#{itemName},'%')
</if>
<if test="maxPrice != null">
<![CDATA[
and price <= #{maxPrice}
]]>
</if>
</where>
</select>Mapper가 있어도 Repository만들어서 사용
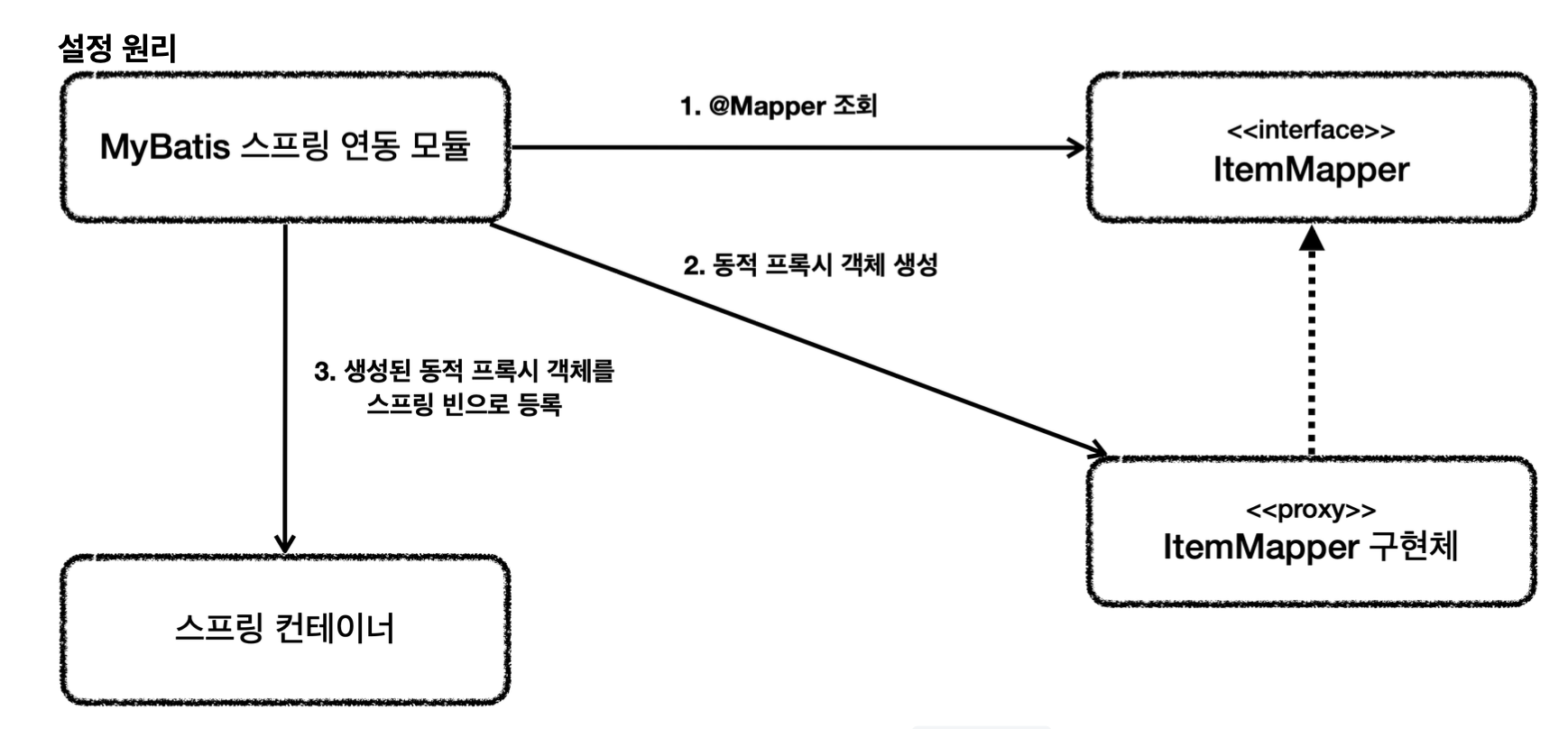
- 애플리케이션 로딩 시점에 MyBatis 스프링 연동 모듈은 @Mapper 가 붙어있는 인터페이스를 조사한다.
- 해당 인터페이스가 발견되면 동적 프록시 기술을 사용해서 ItemMapper 인터페이스의 구현체를 만든다.
- 생성된 구현체를 스프링 빈으로 등록한다.
매퍼 구현체
- 마이바티스 스프링 연동 모듈이 만들어주는 ItemMapper 의 구현체 덕분에 인터페이스 만으로 편리하게 XML의 데이터를 찾아서 호출할 수 있다.
- 원래 마이바티스를 사용하려면 더 번잡한 코드를 거쳐야 하는데, 이런 부분을 인터페이스 하나로 사용할 수 있다.
- 매퍼 구현체는 예외 변환까지 처리해준다. MyBatis에서 발생한 예외를 스프링 예외 추상화인 DataAccessException 에 맞게 변환해서 반환해준다.
- JdbcTemplate이 제공하는 예외 변환 기능을 여기서 도 제공한다고 이해하면 된다.
정리
- 매퍼 구현체 덕분에 마이바티스를 스프링에 편리하게 통합해서 사용할 수 있다.
- 매퍼 구현체를 사용하면 스프링 예외 추상화도 함께 적용된다.
- 마이바티스 스프링 연동 모듈이 많은 부분을 자동으로 설정해주는데, 데이터베이스 커넥션, 트랜잭션과 관련된 기능도 마이바티스와 함께 연동하고, 동기화해준다.
동적 쿼리
MyBatis의 동적 SQL기능
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
if문
<select id="findActiveBlogWithTitleLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
</select>switch문
<select id="findActiveBlogLike" resultType="Blog">
SELECT \* FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select><where> 사용
<where> 는 문장이 없으면 where 를 추가하지 않는다. 문장이 있으면 where 를 추가한다. 만약 and 가 먼저 시작 된다면 and를 지운다
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>foreach
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
<where>
<foreach item="item" index="index" collection="list" open="ID in (" separator="," close=")" nullable="true">
#{item}
</foreach>
</where>
</select>기타 기능
- 어노테이션 SQL 작성
- 재사용이 가능한 SQL조각
- Result Maps
- 결과를 매핑할 때 테이블은 user_id지만 객체는 id이다.
- 이런 경우 별칭
as를 사용한다.
<select id="selectUsers" resultType="User">
select
user_id as "id",
user_name as "userName",
hashed_password as "hashedPassword"
from some_table
where id = #{id}
</select>별칭을 사용하지 않고 resultMap 을 선언해서 사용하기도 한다.
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>4. JPA
객체와 RDBMS의 차이
- 상속
- 연관관계
- 데이터타입
- 데이터 식별 방법
JPA란?
Java Persistence API 자바 진형의 ORM기술 표준
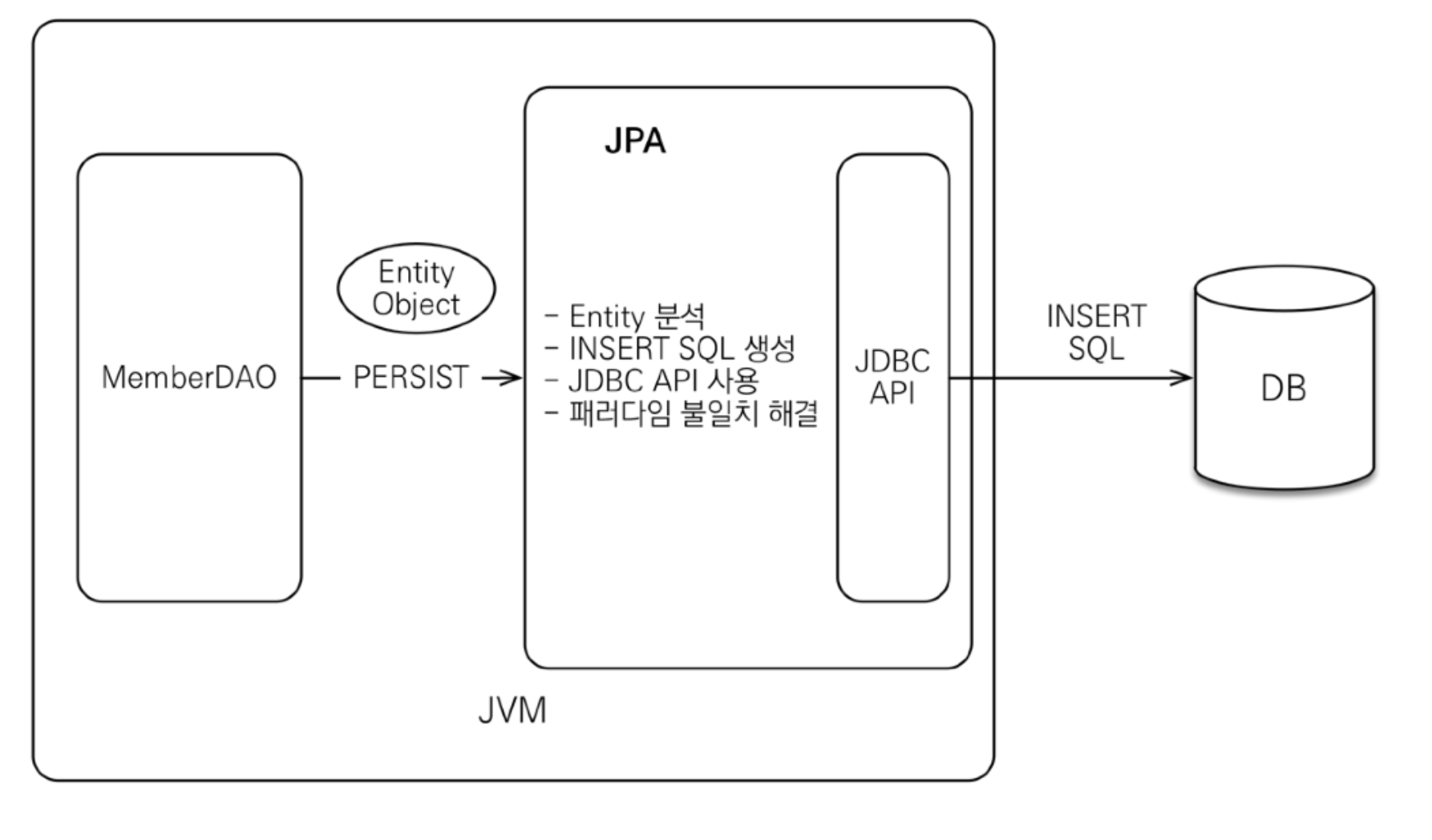
ORM이란?
Object-relational mapping (객체 관계 매핑)
- 객체는 객체대로 설계
- 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑
- 대중적인 언어에는 대부분 ORM 기술이 존재
JPA 사용해야 하는 이유
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 1차 캐시와 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 지연 로딩 : 객체가 실제 사용될 떄 로딩
- 즉시 로딩 : Join SQL로 한번에 연관된 객체까지 미리 조회
- 데이터 접근 추상화와 벤더 독립성
- 표준
@Data
@Entity
public class Item {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "item_name", length = 10)
private String itemName;
private Integer price;
private Integer quantity;
public Item() {
}
public Item(String itemName, Integer price, Integer quantity) {
this.itemName = itemName;
this.price = price;
this.quantity = quantity;
}
}@Entity : JPA가 사용하는 객체라는 뜻이다. 이 에노테이션이 있어야 JPA가 인식할 수 있다.
이렇게 @Entity 가 붙은 객체를 JPA에서는 엔티티라 한다.
@Id : 테이블의 PK와 해당 필드를 매핑한다.
@GeneratedValue(strategy = GenerationType.IDENTITY) : PK 생성 값을 데이터베이스에서 생성하는 IDENTITY 방식을 사용한다. 예) MySQL auto increment
@Column : 객체의 필드를 테이블의 컬럼과 매핑한다.
name = “item_name” : 객체는 itemName 이지만 테이블의 컬럼은 item_name 이므로 이렇게 매핑.
length = 10 : JPA의 매핑 정보로 DDL( create table )도 생성할 수 있는데, 그때 컬럼의 길이 값으로 활용된다. ( varchar 10 )
@Column 을 생략할 경우 필드의 이름을 테이블 컬럼 이름으로 사용한다.
참고로 지금처럼 스프링 부트와 통합해서 사용하면 필드 이름을 테이블 컬럼 명으로 변경할 때 객체 필드의 카멜 케이스를 테이블 컬럼의 언더스코어로 자동으로 변환해준다.
itemName item_name , 따라서 위 예제의 @Column(name = “item_name”) 를 생략해도 된다.
JPA는 public 또는 protected 의 기본 생성자가 필수이다
@Slf4j
@Repository
@Transactional
public class JpaItemRepository implements ItemRepository {
private final EntityManager em;
public JpaItemRepository(EntityManager em) {
this.em = em;
}
@Override
public Item save(Item item) {
em.persist(item);
return item;
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = em.find(Item.class, itemId);
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
Item item = em.find(Item.class, id);
return Optional.ofNullable(item);
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String jpql = "select i from Item i";
Integer maxPrice = cond.getMaxPrice();
String itemName = cond.getItemName();
if (StringUtils.hasText(itemName) || maxPrice != null) {
jpql += " where";
}
boolean andFlag = false;
List<Object> param = new ArrayList<>();
if (StringUtils.hasText(itemName)) {
jpql += " i.itemName like concat('%',:itemName,'%')";
param.add(itemName);
andFlag = true;
}
if (maxPrice != null) {
if (andFlag) {
jpql += " and";
}
jpql += " i.price <= :maxPrice";
param.add(maxPrice);
}
log.info("jpql={}", jpql);
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
if (StringUtils.hasText(itemName)) {
query.setParameter("itemName", itemName);
}
if (maxPrice != null) {
query.setParameter("maxPrice", maxPrice);
}
return query.getResultList();
}
}private final EntityManager em : 생성자를 보면 스프링을 통해 엔티티 매니저( EntityManager )라는 것을 주입
JPA의 모든 동작은 엔티티 매니저를 통해서 이루어진다.
엔티티매니저는 내부에 데이터소스를 가지고 있고, 데이터베이스에 접근할 수 있다.
@Transactional : JPA의 모든 데이터 변경(등록, 수정, 삭제)은 트랜잭션 안에서 이루어져야 한다.(항상 필요)
조회는 트랜잭션이 없어도 가능하다
update
- JPA는 트랜잭션이 커밋되는 시점에, 변경된 엔티티 객체가 있는지 확인한다.
- 특정 엔티티 객체가 변경된 경우에는 UPDATE SQL을 실행한다.
JPQL이란
JPA는 JPQL(Java Persistence Query Language)이라는 객체지향 쿼리 언어를 제공한다.
주로 여러 데이터를 복잡한 조건으로 조회할 때 사용한다
JPA 예외 변환
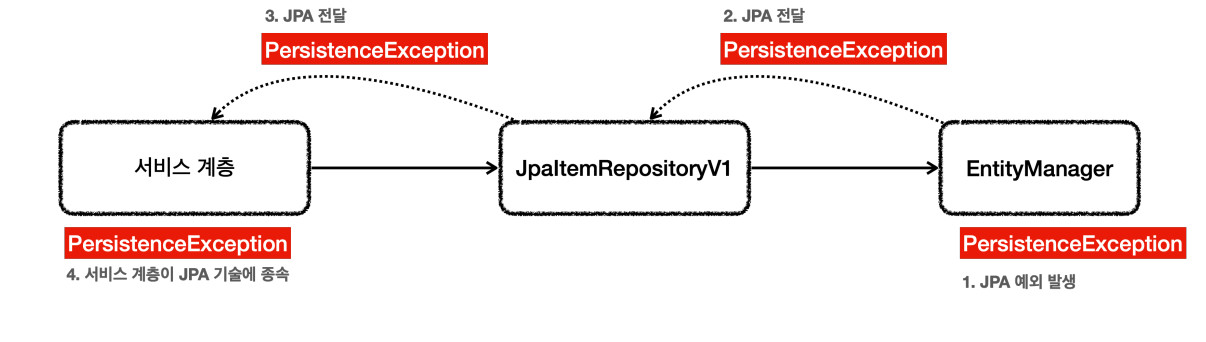
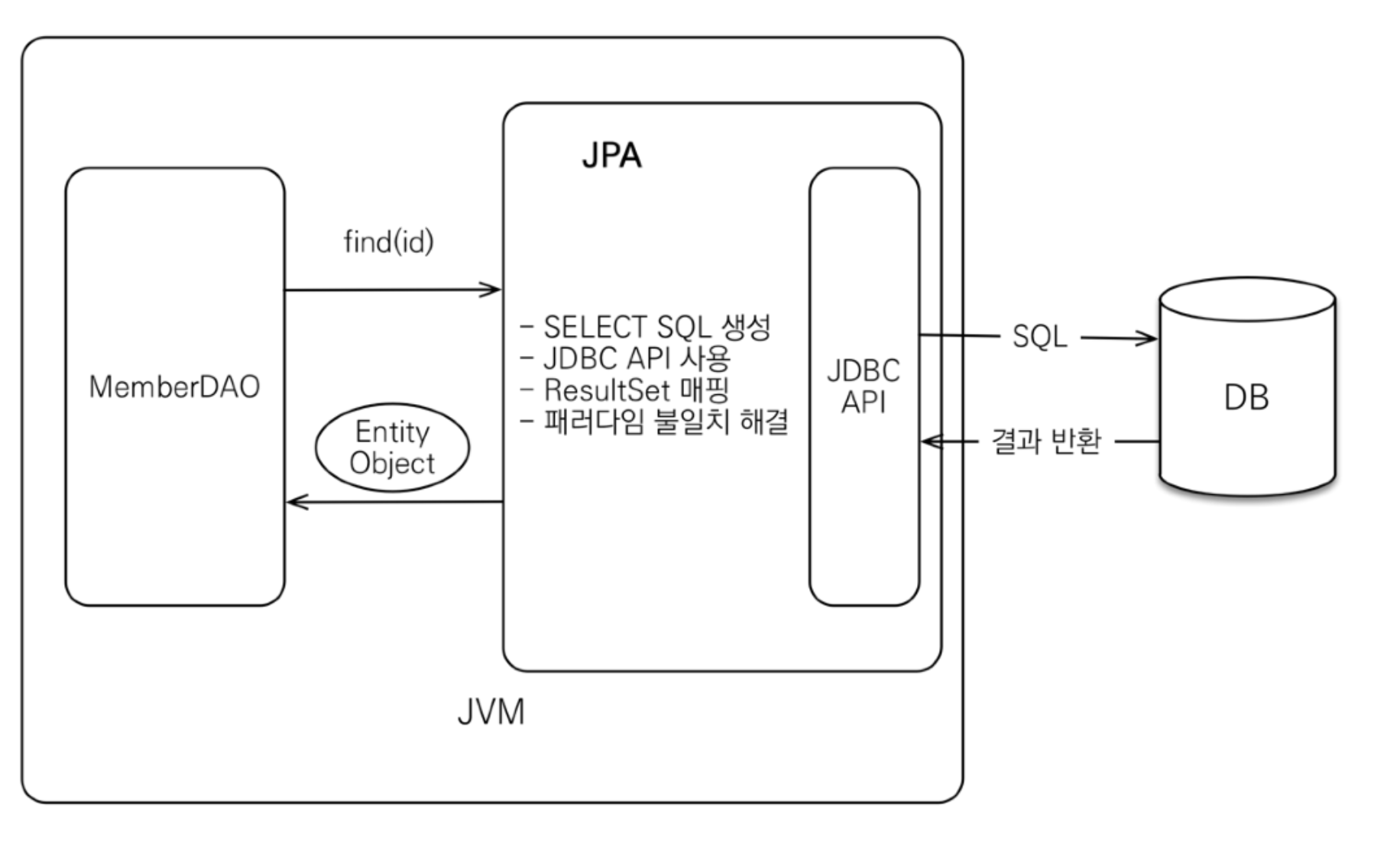
- EntityManager 는 순수한 JPA 기술이고, 스프링과는 관계가 없다. 따라서 엔티티 매니저는 예외가 발생하면 JPA 관련 예외를 발생시킨다.
- JPA는 PersistenceException 과 그 하위 예외를 발생시킨다.
- 추가로 JPA는 IllegalStateException , IllegalArgumentException 을 발생시킬 수 있다
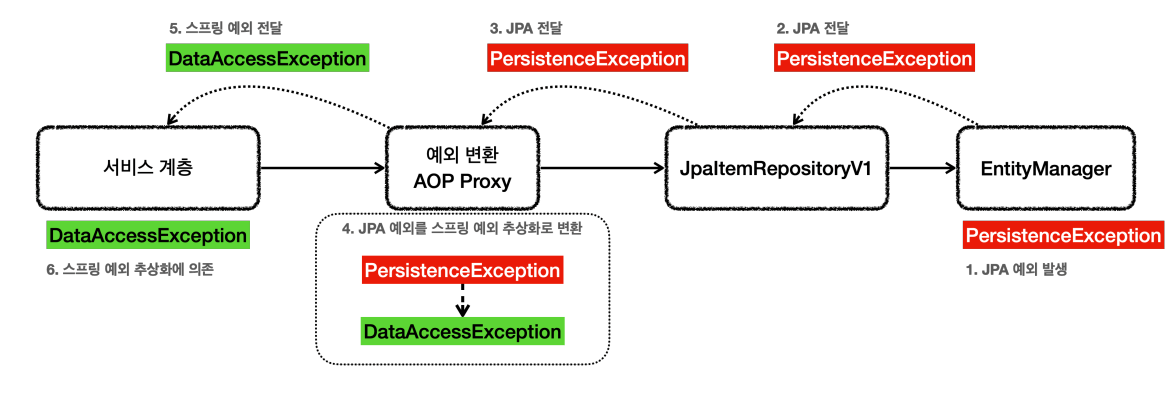
- @Repository는 JPA예외를 스프링 예외(DataAccessException)으로 변환시켜 준다.
- @Repository의 기능
- @Repository 가 붙은 클래스는 컴포넌트 스캔의 대상이 된다.
- @Repository 가 붙은 클래스는 예외 변환 AOP의 적용 대상이 된다.
- 스프링과 JPA를 함께 사용하는 경우 스프링은 JPA 예외 변환기 (PersistenceExceptionTranslator)를 등록한다.
- 예외 변환 AOP 프록시는 JPA 관련 예외가 발생하면 JPA 예외 변환기를 통해 발생한 예외를 스프링 데이터 접근 예외로 변환한다
- 스프링 부트는PersistenceExceptionTranslationPostProcessor 를 자동으로 등록하는데, 여기에서 @Repository 를 AOP 프록시로 만드는 어드바이저가 등록
- 복잡한 과정을 거쳐서 실제 예외를 변환하는데, 실제 JPA 예외를 변환하는 코드는 EntityManagerFactoryUtils.convertJpaAccessExceptionIfPossible() 이다.
5. Spring Data JPA
- 스프링 데이터 JPA는 JPA를 편리하게 사용할 수 있도록 도와주는 라이브러리
- 수많은 편리한 기능을 제공하지만 가장 대표적인 기능은 다음과 같다.
- 공통 인터페이스 기능
- 쿼리 메소드 기능
- 메소드 이름으로 쿼리를 자동으로 만들어주고 실행해주는 기능
- 조회: find…By , read…By , query…By , get…By
- 예:) findHelloBy 처럼 …에 식별하기 위한 내용(설명)이 들어가도 된다.
- COUNT: count…By 반환타입 long
- EXISTS: exists…By 반환타입 boolean
- 삭제: delete…By , remove…By 반환타입 long
- DISTINCT: findDistinct , findMemberDistinctBy
- LIMIT: findFirst3 , findFirst , findTop , findTop3
- 조회: find…By , read…By , query…By , get…By
- 메소드 이름으로 쿼리를 자동으로 만들어주고 실행해주는 기능
- 직접 JPQL을 사용하고 싶을 경우엔
@Query와 함꼐 JPQL작성
6. QueryDSL
Query의 문제점
- Query는 문자, Type-check불가능
- 실행하기 전까지 작동여부 확인 불가
- 에러는 크게 컴파일 에러, 런타임 에러
QueryDSL 장점
- QueryDSL은 컴파일 시 컴파일 오류 발생
- QueryDSL은 동적 쿼리 작성에 용이
- Java Code로 작성하기에 모듈화가 가능하다.
- DSL
- 도메인 + 특화 + 언어
- 특정한 도메인에 초점을 맞춘 제한적인 표현력을 가진 컴퓨터 프로그래밍 언어
- 특징 : 단순, 간결, 유창
- QueryDSL : 쿼리 + 도메인 + 특화 + 언어
- 데이터 쿼리 추상화
QueryDSL 사용
- 복잡한 과정을 거쳐서 실제 예외를 변환하는데, 실제 JPA 예외를 변환하는 코드는 EntityManagerFactoryUtils.convertJpaAccessExceptionIfPossible() 이다.
- 참고로 JPAQueryFactory 를 스프링 빈으로 등록해서 사용해도 된다.
7. 데이터 접근 기술 - 활용 방안
- DI, OCP를 지키기 위해 어댑터를 도입하고, 더 많은 코드를 유지한다.
- 어댑터를 제거하고 구조를 단순하게 가져가지만, DI, OCP를 포기하고, ItemService 코드를 직접 변경한다.
=> 결국 여기서 발생하는 트레이드 오프는 구조의 안정성 vs 단순한 구조와 개발의 편리성 사이의 선택이다.
어설픈 추상화는 오히려 독이된다
무엇보다 추상화도 비용이 든다.
실용적인 구조
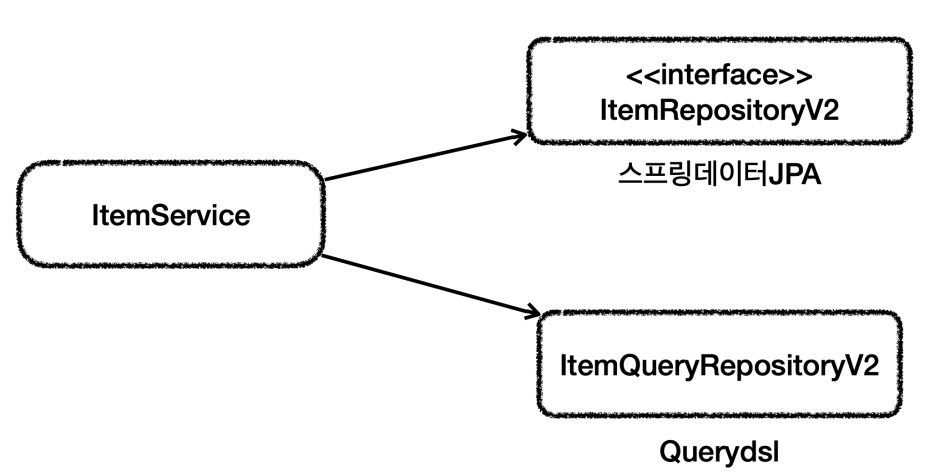
단순 조회는 스프링 데이터 JPA가 담당하고, 복잡한 조회 쿼리는 QueryDSL이 담당한다.
다양한 데이터 접근 기술 조합
- 실무에선 95% 정도는 JPA, 스프링 데이터 JPA, QueryDSL등으로 해결하고, 나머지 5%는 SQL을 직접 사용해야 하니 JDBCTemplate or MyBatis로 해결
- 트랜잭션 매니저 선택
- 모두 JPA기술을 사용하니
JpaTransactionManager사용 - JPA기술을 사용하면 스프링 부트는 자동으로
JpaTransactionManager를 스프링 빈에 등록 - JdbcTemplate, MyBatis는 내부에서 직접 SDBC를 사용해서
DataSourceTransactionManager를 사용JpaTransactionManager는DataSourceTransactionManager가 제공하는 기능을 대부분 제공- 내부에서는 DataSource와 JDBC커넥션을 사용하기 떄문
- 모두 JPA기술을 사용하니
=> 결과적으로 JpaTransactionManager를 하나만 스프링 빈에 등록하면 JPA, JdbcTemplate, MyBatis 모두를 하나의 트랜잭션으로 묶어서 사용이 가능 (롤백도 가능)
이렇게 사용할 경우에 JPA의 플러시 타이밍에 주의
JPA는 데이터 변경 사항을 즉시 DB에 반영하지 않는다.
하나의 트랜잭션 안에서 JPA를 통해 데이터를 변경한 다음 JdbcTemplate를 호출하는 경우 JPA가 변경한 데이터를 읽지 못하는 경우 생김
JPA변경 내역을 플러시 기능을 사용해 반영해줘야 사용 가능
8. 스프링 트랜잭션 이해
JPA와 JDBC기술은(각각의 데이터 접근 기술들은) 트랜잭션을 처리하는 방식에 차이가 있다.
따라서 JDBC 기술을 사용하다가 JPA 기술로 변경하게 되면 트랜잭션을 사용하는 코드도 모두 함께 변경해야 한다.
스프링은 이런 문제를 해결하기 위해 트랜잭션 추상화를 제공한다
스프링은 PlatformTransactionManager 라는 인터페이스를 통해 트랜잭션을 추상화한다.
스프링은 트랜잭션을 추상화해서 제공할 뿐만 아니라, 실무에서 주로 사용하는 데이터 접근 기술에 대한 트랜잭션 매니저의 구현체도 제공한다. 우리는 필요한 구현체를 스프링 빈으로 등록하고 주입 받아서 사용하기만 하면 된다.
여기에 더해서 스프링 부트는 어떤 데이터 접근 기술을 사용하는지를 자동으로 인식해서 적절한 트랜잭션 매니저를 선택해서 스프링 빈으로 등록해주기 때문에 트랜잭션 매니저를 선택하고 등록하는 과정도 생략할 수 있다.
예를 들어서 JdbcTemplate , MyBatis 를 사용하면
DataSourceTransactionManager(JdbcTransactionManager) 를 스프링 빈으로 등록하고, JPA를
사용하면 JpaTransactionManager 를 스프링 빈으로 등록해준다.
트랜잭션 적용 확인
- AOP기반으로 동작하기에 눈으로 확인이 어렵다.
- @Transactional 을 메서드나 클래스에 붙이면 해당 객체는 트랜잭션 AOP 적용의 대상이 되고, 결과적으로 실제 객체 대신에 트랜잭션을 처리해주는 프록시 객체가 스프링 빈에 등록된다.
- 실제로
@Transactinal을 사용하고, 주입받은 클래스를getClass()로 찍어보면 프록시 객체가 주입되어 나온다.
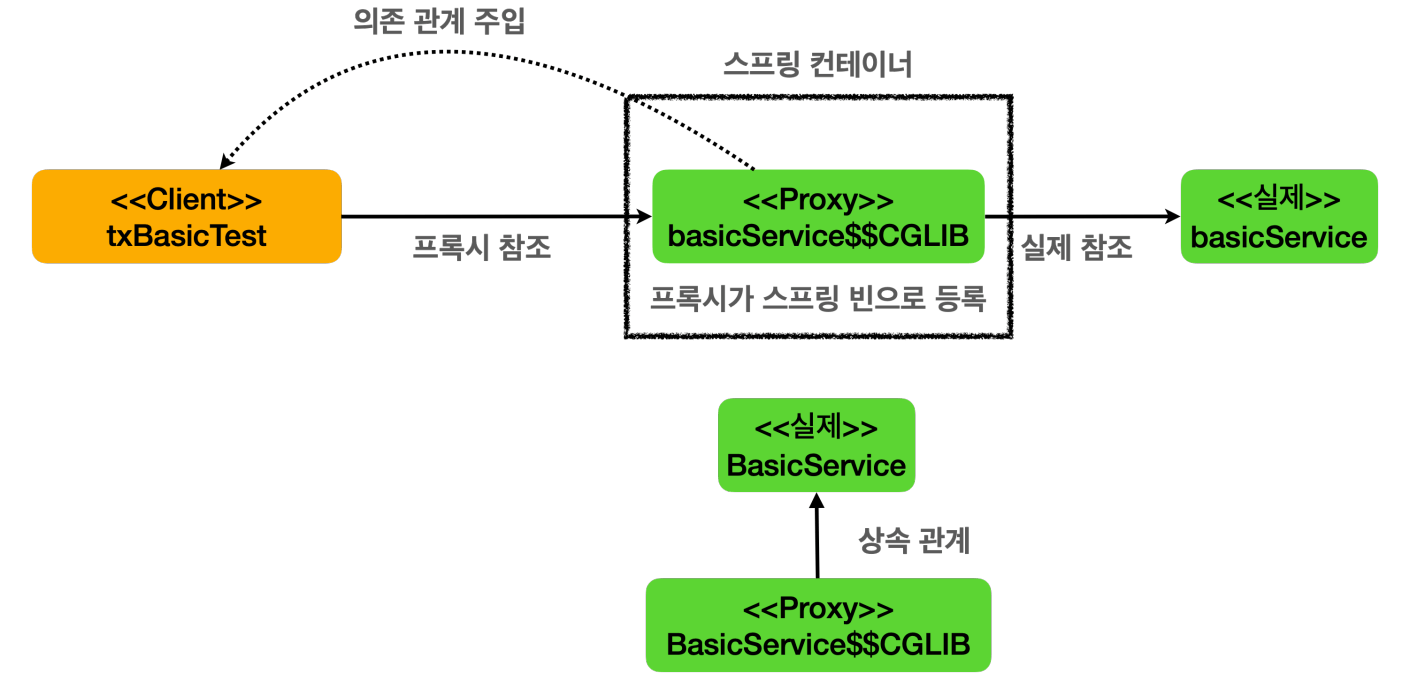
@Transactional어노테이션이 특정 클래스나 메서드에 하나라도 있으면 트랜잭션 AOP는 프록시를 만들어 스프링 컨테이너에 등록한다.- 핵심은 실제 객체 대신에 프록시가 스프링 컨테이너에 등록되었다는 점이다.
- 클라이언트인
txBasicTest는 스프링 컨테이너에 의존관계 주입을 요청한다. - 스프링 컨테이너에서는 실제 객체 대신 프록시가 스프링 빈으로 등록되어 있기 때문에 프록시를 주입한다.
트랜잭션 적용 위치
- 스프링에서 우선순위는 항상 더 구체적이고 자세한 것이 높은 우선순위를 가진다.
스프링의 @Transactional 은 다음 두 가지 규칙이 있다.
- 우선순위 규칙
- 클래스에 적용하면 메서드는 자동 적용
인터페이스에도 @Transactional적용
인터페이스에도 @Transactional을 적용할 수 있다.
우선순위는 다음과 같다.
- 클래스의 메서드 (우선순위가 높다.)
- 클래스의 타입
- 인터페이스의 메서드
- 인터페이스 타입
인터페이스에 @Transactional 사용하는 것은 스프링 공식 메뉴얼에서 권장하는 사항이 아니다.
AOP가 적용되지 않는 경우도 있기 떄문이다.
가급적 구현 클래스에서 @Transactional을 사용하자
트랜잭션 AOP 주의사항 - 프록시 내부 호출
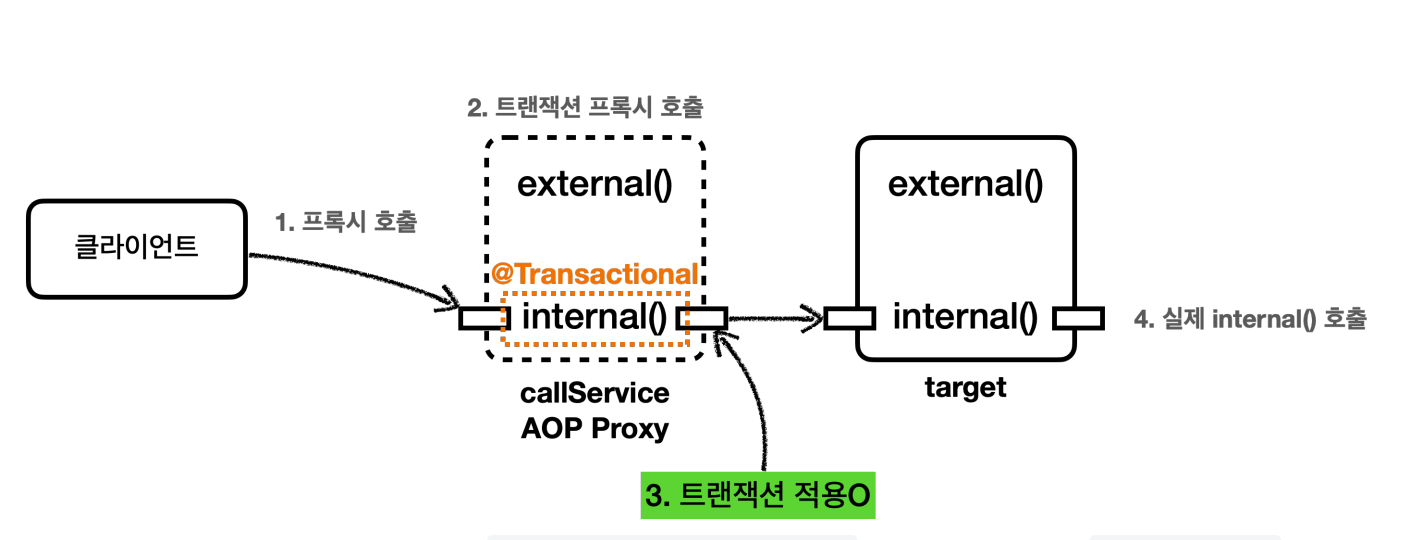
정상 호출
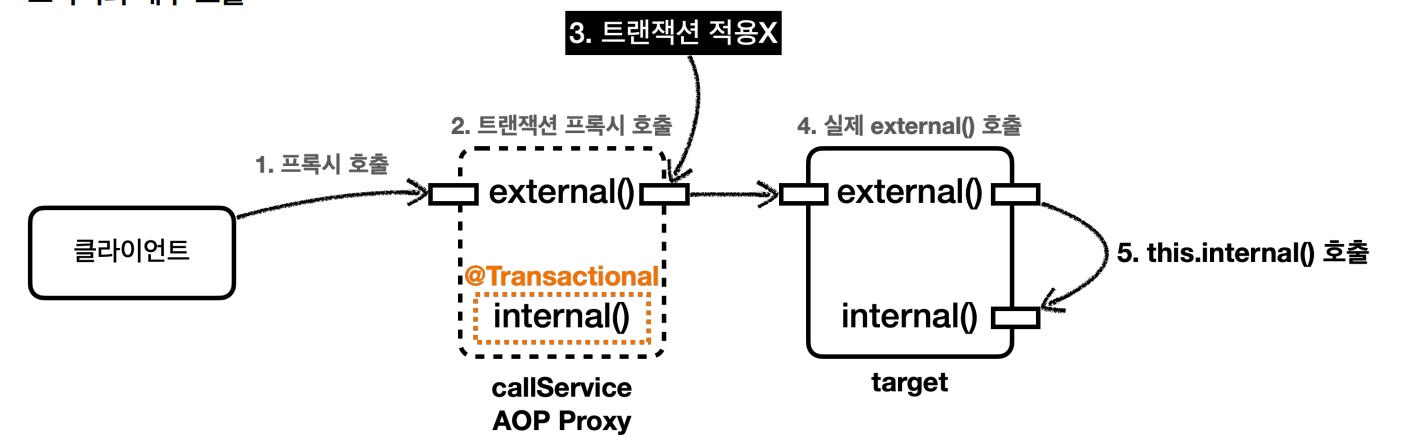
external() 메서드에서 @Transactional이 적용된 proxy객체인 internal이 아니라
내부의 internal() 메소드를 호출하면 내부 호출이 되어 프록시를 거치지 않아 트랜잭션이 적용되지 않는다.
external에서 internal을 호출 시 자기 자신의 내부 메서드를 호출하는 this.internal() 이 되는데, 여기서 this 는 자기 자신을 가리키므로, 실제 대상 객체( target )의 인스턴스를 뜻한다. 결과적으로 이러한 내부 호출은 프록시를 거치지 않는다.
내부 호출로 인해 트랜잭션이 적용되지 않는 것은 프록시 방식의 AOP 한계이다.
문제를 해결하는 방법은 내부 호출을 피하기 위해 메서드를 별도의 클래스로 분리하는 것이다.
아래와 같이 내부 호출을 외부 호출로 변경한다
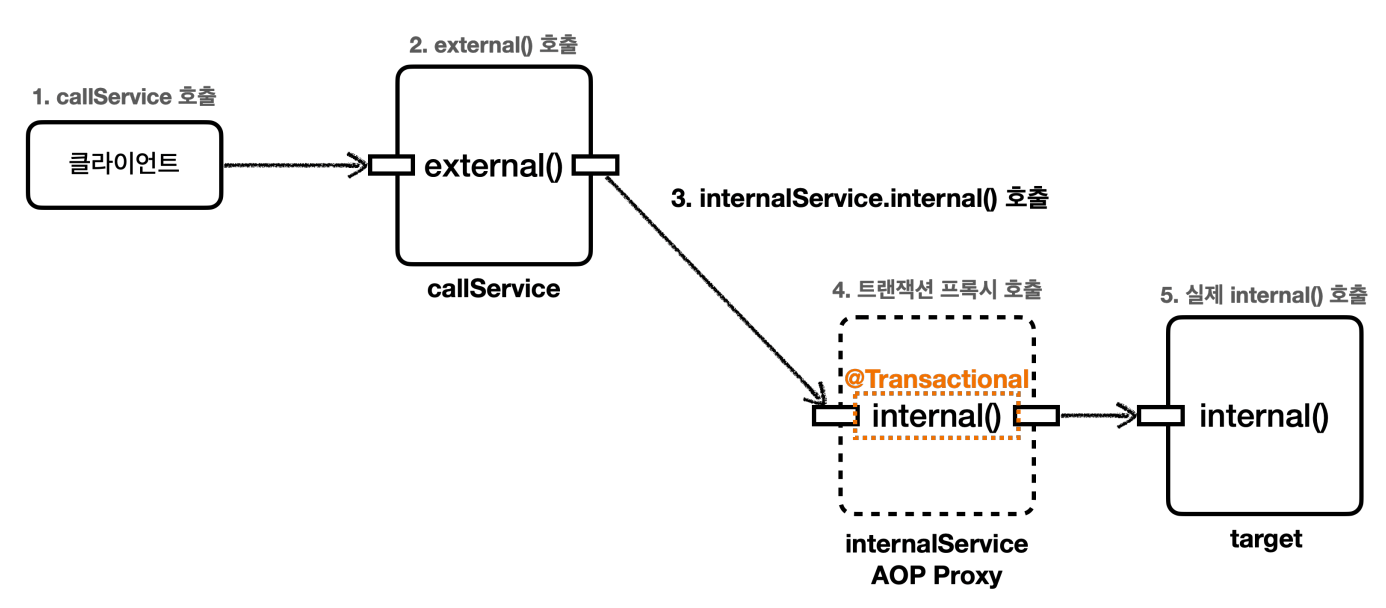
다른 해결방안도 있지만, 실무에서는 이렇게 별도의 클래스(서비스)로 분리하는 방법을 주로 사용한다.
트랜잭션 AOP 주의사항 - public 메서드에만 트랜잭션 적용
스프링 트랜잭션 AOP기능은 public메서드에만 트랜잭션을 적용하게 기본 설정이 되어있다.
그래서 protected , private , package-visible 에는 트랜잭션이 적용되지 않는다
클래스 레벨에 트랜잭션을 적용하면 모든 메서드에 트랜잭션이 걸릴 수 있다.
트랜잭션을 의도하지 않는 곳까지 과도하게 적용되지 않게 하기 위해 public에만 적용하도록 설정
(private나 protected같은 경우 트랜잭션을 사용하지 않을 의도를 가질 확률이 높음)
트랜잭션 AOP 주의사항 - 초기화 시점
초기화 코드가 먼저 호출되고, 그 다음에 트랜잭션 AOP가 적용되기 떄문에 초기화 시점에는 트랜잭션 획득 불가능
트랜잭션 옵션 소개
트랜잭션을 사용할 때 트랜잭션 매니저를 주입받아 사용한다.
@Transactional에서도 트랜잭션 프록시가 사용할 매니저를 지정해주어야 한다.
트랜잭션 매니저를 지정할 때는 value, transactionManager둘 중 하나에 트랜잭션 매니저의 스프링 빈의 이름을 적어주면 된다.
이 값을 생략하면 기본적으로 등록된 트랜잭션 매니저를 사용하기에 대부분 생략한다.
트랜잭션 매니저가 2개 이상이라면 다음과 같이 트랜잭션 매니저의 이름을 지정해서 구분한다.
public class TxService {
// value는 생략이 가능
// @Transactional("memberTxManager")
@Transactional(value = "memberTxManager")
public void member() {...}
@Transactional("orderTxManager")
public void order() {...}
}@Transactional(rollbackFor = Exception.class)예외 발생 시 트랜잭션의 기본 정책은 다음과 같다.
- 언체크 예외인
RuntimeException,Error와 하위 예외가 발생하면 롤백 - 체크 예외인
Exception과 그 하위 예외는 커밋
rollbackFor는 어떤 예외가 발생할 때 롤백하는지 지정할 수 있다.
- noRollBackFor : rollbackFor와 반대, 기본 저액에 추가로 어떤 예외가 발생했을 때 롤백하면 안되는지 지정
- propagation : 트랜잭션 전파에 대한 오변
- isolation : 트랜잭션 격리 수준을 지정 가능
- DEFAULT : 데이터베이스에서 설정한 격리 수준을 따른다.
- READ_UNCOMMITTED : 커밋되지 않은 읽기
- READ_COMMITTED : 커밋된 읽기
- REPEATABLE_READ : 반복 가능한 읽기
- SERIALIZABLE : 직렬화 가능
- timeout : 트랜잭션 수행시간에 대한 타임아웃을 초단위로 지정
- label : 트랜잭션 어노테이션 있는 값을 일거 어떤 동작을 하고 싶을 때 사용 (잘 사용 안함)
- readOnly : 기본적으로 읽기 쓰기가 모두 가능한 트랜잭션 생성
- readOnly=true 옵션을 사용하면 읽기 전용 트랜잭션이 생성된다
- 크게 3곳에 적용된다.
- 프레임워크
- JdbcTemplate는 읽기전용 트랜잭션 안에서 변경 기능을 실행하면 예외를 던진다.
- JPA는 읽기 전용 트랜잭션의 경우 커밋시점에 플러시 호출x (추가적인 다양한 최적화 발생)
- readOnly 옵션을 사용하면 읽기에서 다양한 성능 최적화가 발생할 수 있다.
- 추가로 변경이 필요 없으니 변경 감지를 위한 스냅샷 객체도 생성하지 않는다.
- 이렇게 JPA에서는 다양한 최적화가 발생한다
- JDBC드라이버
- 아래의 내용들은 DB와 드라이버 버전에 따라 다르게 동작, 사전에 확인 필요
- 읽기 전용 트랜잭션에서 변경 쿼리 발생 시 예외 던진다.
- 읽기, 쓰기(마스터 , 슬레이브) DB를 구분해서 요청
- 읽기 전용 트랜잭션의 경우 읽기 데이터베이스 커넥션 획득해서 사용
- DB
- 읽기 전용 트랜잭션의 경우 읽기만 하면 되므로, 내부에서 성능 최적화 발생
- 프레임워크
예외와 트랜잭션 커밋, 롤백
- 예외 발생시 스프링 트랜잭션 AOP는 예외의 종류에 따라 트랜잭션을 커밋하거나 롤백한다.
- 언체크 예외인 RuntimeException , Error 와 그 하위 예외가 발생하면 트랜잭션을 롤백한다.
- 체크 예외인 Exception 과 그 하위 예외가 발생하면 트랜잭션을 커밋한다.
스프링은 체크 예외는 커밋하고, 언체크(런타임) 예외는 롤백하는데 왜 이렇게 동작을 할까
기본적으로 체크예외는 비즈니스 의미가 있을 때 사용하고, 런타임 예외는 복구 불가능한 예외로 가정한다.
꼭 이런 정책을 따를 필요는 없고 rollbackFor옵션 사용해서 체크예외도 롤백하면 된다.
비즈니스 예외
- 정상: 주문시 결제를 성공하면 주문 데이터를 저장하고 결제 상태를 완료 로 처리한다.
- 시스템 예외: 주문시 내부에 복구 불가능한 예외가 발생하면 전체 데이터를 롤백한다. (보통 런타임 예외로 처리한다.)
- 비즈니스 예외: 주문시 결제 잔고가 부족하면 주문 데이터를 저장하고, 결제 상태를 대기 로 처리한다.
-> 이 경우 고객에게 잔고 부족을 알리고 별도의 계좌로 입금하도록 안내한다.
정리
- 비즈니스 상 오류 발생 -> 시스템이 정상동작 -> 트랜잭션을 커밋하는게 맞다
- 체크 예외의 경우에도 트랜잭션 커밋하지 않고 롤백하고 싶다. ->
rollbackFor옵션 사용 - 런타임 예외는 항상 롤백된다
- 체크 예외인 경우에만 비즈니스 상황에 맞게 커밋과 롤백을 선택
9. 스프링 트랜잭션 전파1 - 기본
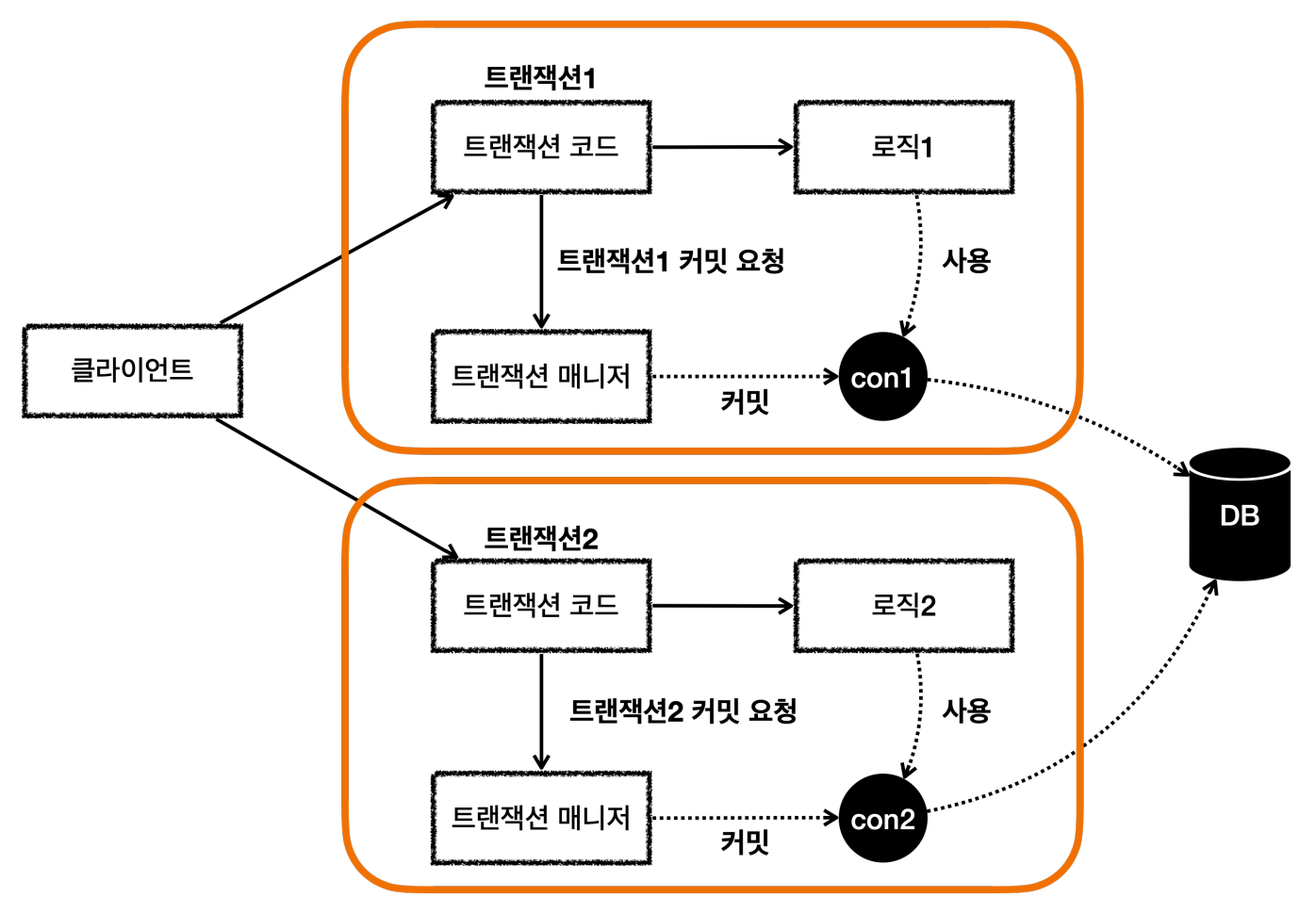
트랜잭션을 연속해서 2번 사용하면 같은 커넥션을 사용한 것을 볼 수 있다.
-> 커넥션은 재사용, 프록시 객체의 주소가 다르기 때문에 각각 커넥션 풀에서 커넥션을 조회한 것이다.
트랜잭션을 수행중인데 내부에서 트랜잭션을 중첩해서 사용한 경우
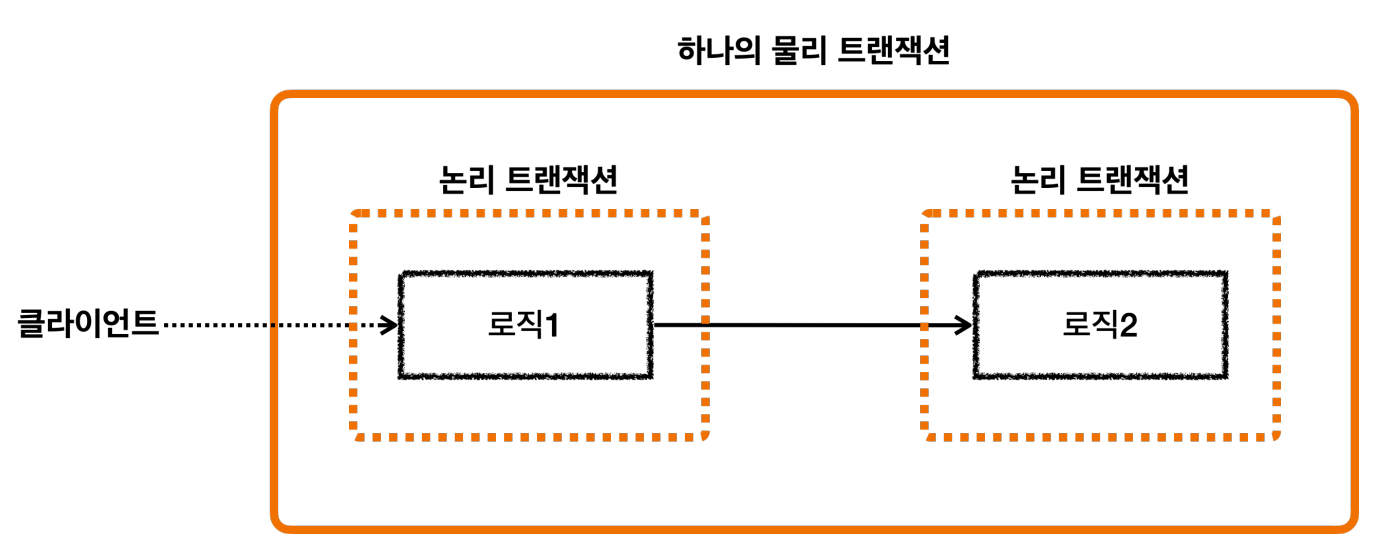
- 스프링은 이해를 돕기 위해 논리 트랜잭션과 물리 트랜잭션이라는 개념을 나눈다.
- 논리 트랜잭션들은 하나의 물리 트랜잭션으로 묶인다.
- 물리 트랜잭션은 우리가 이해하는 실제 데이터베이스에 적용되는 트랜잭션을 뜻한다. 실제 커넥션을 통해서 트랜잭션을 시작( setAutoCommit(false)) 하고, 실제 커넥션을 통해서 커밋, 롤백하는 단위이다.
- 논리 트랜잭션은 트랜잭션 매니저를 통해 트랜잭션을 사용하는 단위이다.
- 이러한 논리 트랜잭션 개념은 트랜잭션이 진행되는 중에 내부에 추가로 트랜잭션을 사용하는 경우에 나타난다.
논리 트랜잭션 개념을 도입해 단순한 원칙 2가지를 만든다.
- 모든 논리 트랜잭션이 커밋되어야 물리 트랜잭션이 커밋된다.
- 하나의 논리 트랜잭션이라도 롤백되면 물리 트랜잭션은 롤백된다.
외부 트랜잭션에 내부트랜잭션이 있는경우 내부 트랜잭션은 새로운 트랜잭션이 생기지 않고 그대로 이어 받는다.
외부 트랜잭션과 내부 트랜잭션이 하나의 물리 트랜잭션으로 묶이는 것이다.
만약 내부 트랜잭션이 실제 물리 트랜잭션을 커밋하면 트랜잭션이 끝난다. -> 내부 트랜잭션은 물리 트랜잭션을 커밋하면 안된다.
스프링은 이렇게 여러 트랜잭션이 함께 사용되는 경우, 처음 트랜잭션을 시작한 외부 트랜잭션이 실제 물리 트랜잭션을 관리하도록 한다.
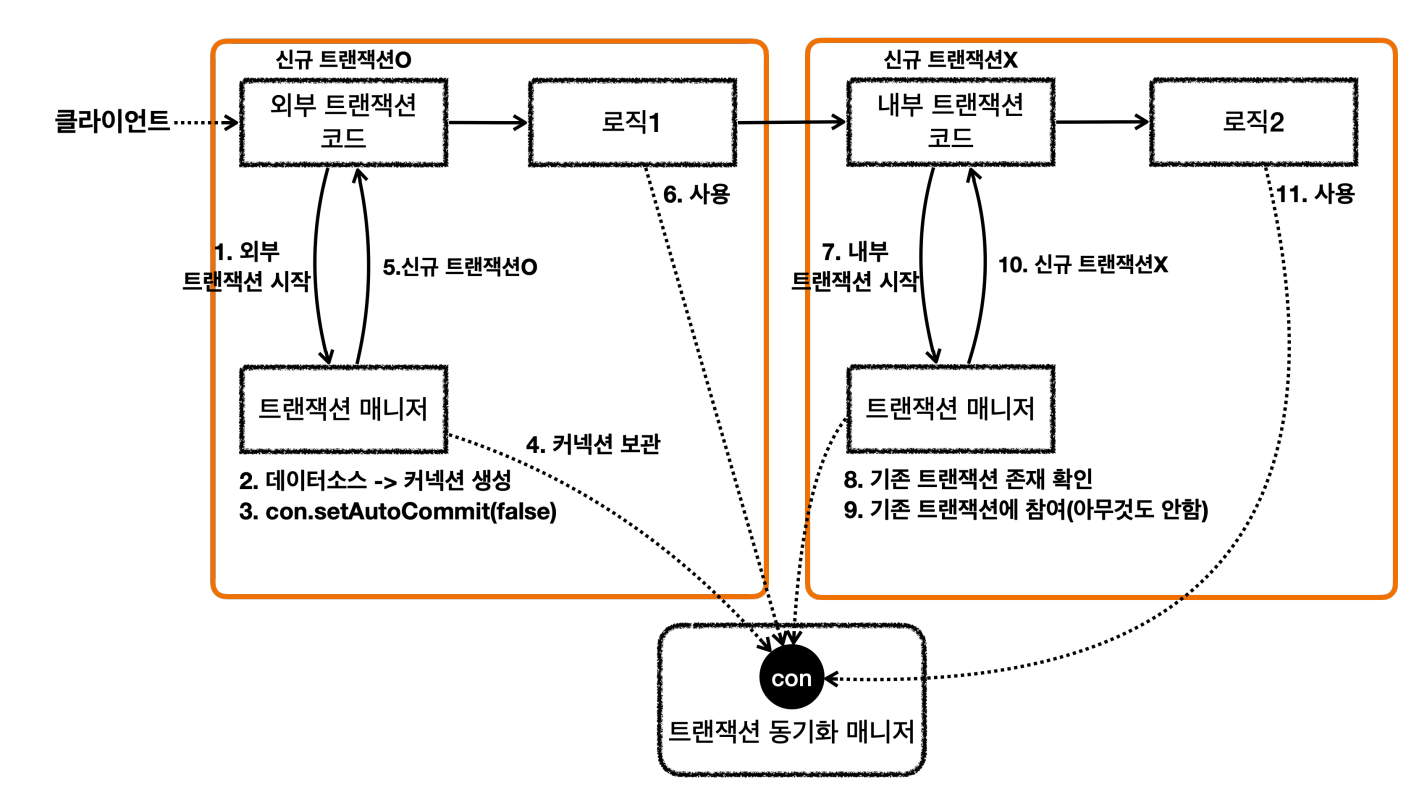
요청 흐름
응답 흐름
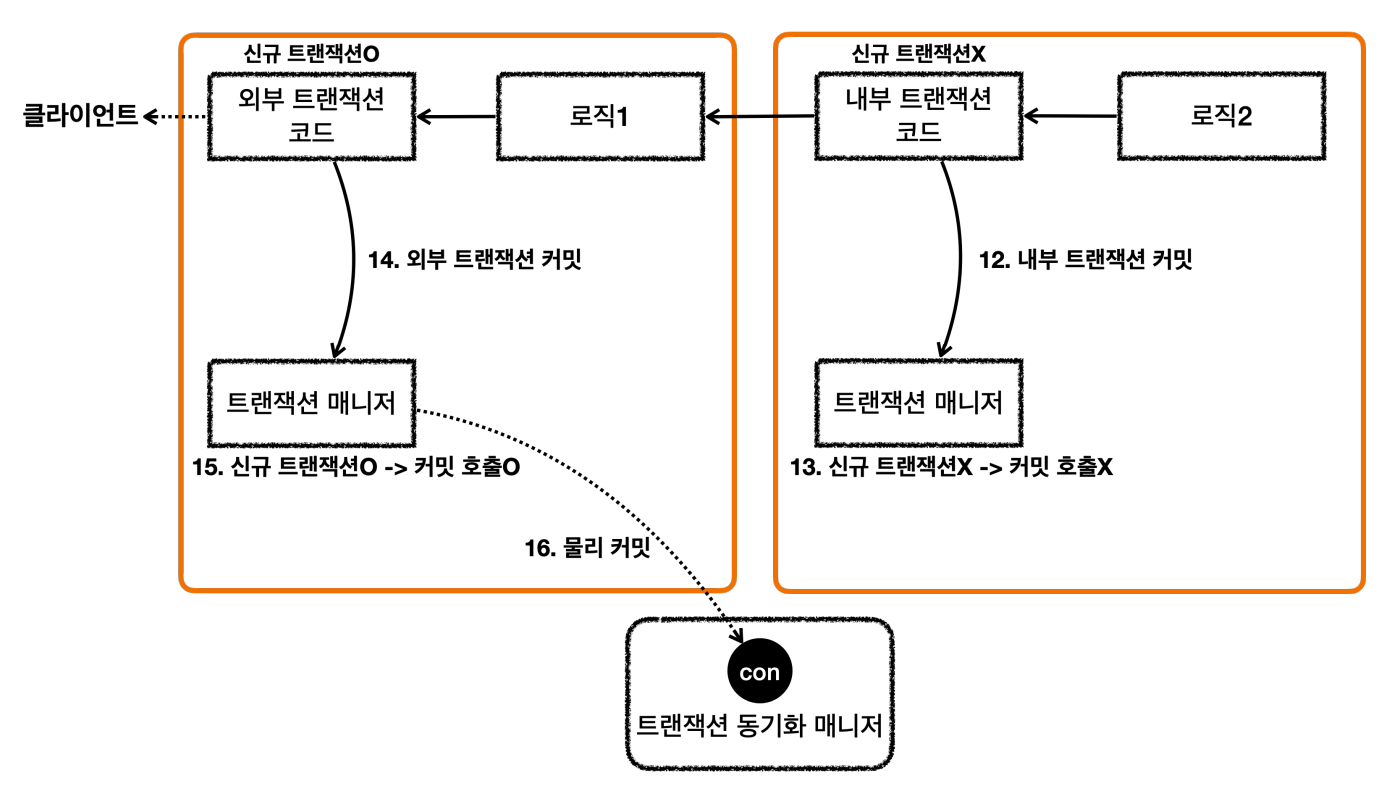
요기서 포인트는 내부 트랜잭션이 요청시에는 신규 트랜잭션이 아니고, 기존 트랜잭션에 참여해 아무것도 안한다.
응답시에는 실제 커밋을 호출하지 않는다.
여기서 정리하면
- 핵심은 트랜잭션 매니저에 커밋을 호출한다고 해서 항상 실제 커넥션에 물리 커밋이 발생하지 않는다.
- 신규 트랜잭션인 경우에만 실제 커넥션을 사용해서 물리 커밋과 롤백을 수행
- 신규 트랜잭션이 아니면 실제 물리 커넥션을 사용하지 않는다.
- 트랜잭션이 내부에서 추가로 사용되면, 트랜잭션 매니저를 통해 논리 트랜잭션을 관리하고, 모든 논리 트랜잭션이 커밋되면 물리 트랜잭션이 커밋된다고 이해하면 된다.
외부 트랜잭션만 롤백하는 경우는 당연히 물리 롤백이 일어난다.
그러면 내부 트랜잭션의 경우에는 어떻게 동작할까?
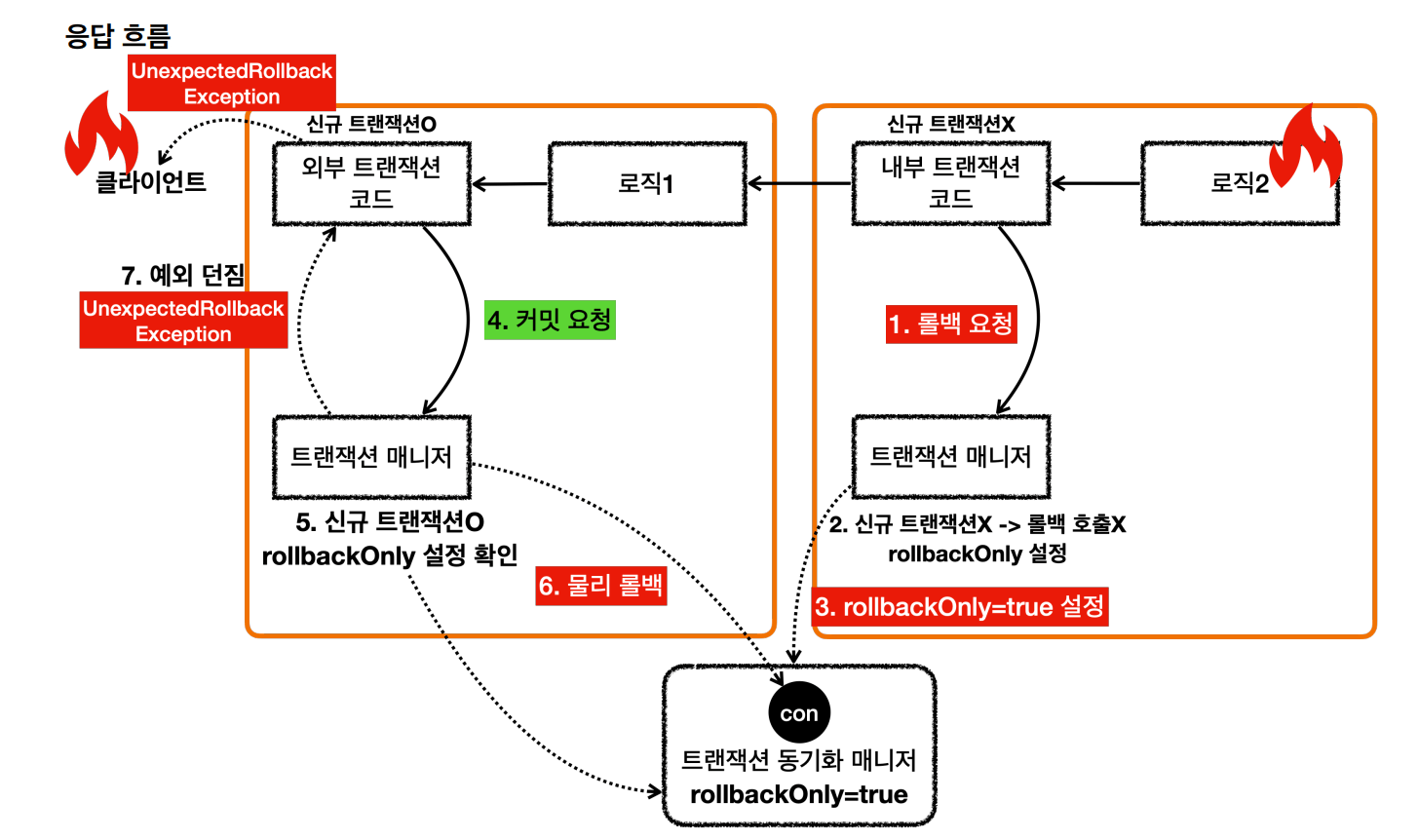
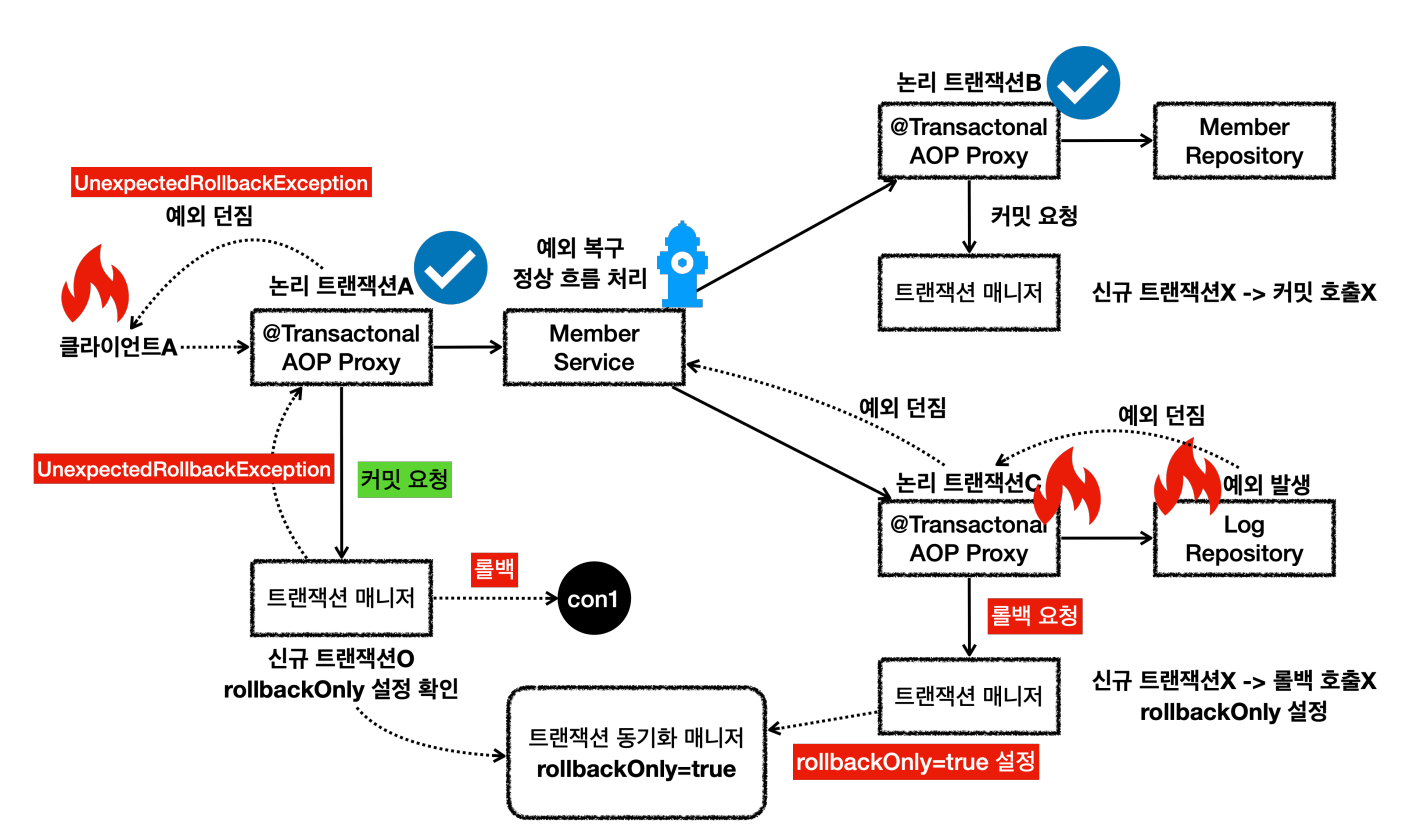
내부 트랜잭션은 물리 트랜잭션을 롤백하지 않는 대신에 트랜잭션 동기화 매니저에 rollbackOnly=true라는 표시를 해둔다.
정리
- 논리 트랜잭션이 하나라도 롤백되면 물리 트랜잭션은 롤백된다.
- 내부 논리 트랜잭션이 롤백되면 롤백 전용 마크를 표시한다.
- 외부 트랜잭션을 커밋할 때 롤백 전용 마크를 확인한다. 롤백 전용 마크가 표시되어 있으면 물리 트랜잭션을 롤백하고, UnexpectedRollbackException 예외를 던진다.
REQUIRES_NEW
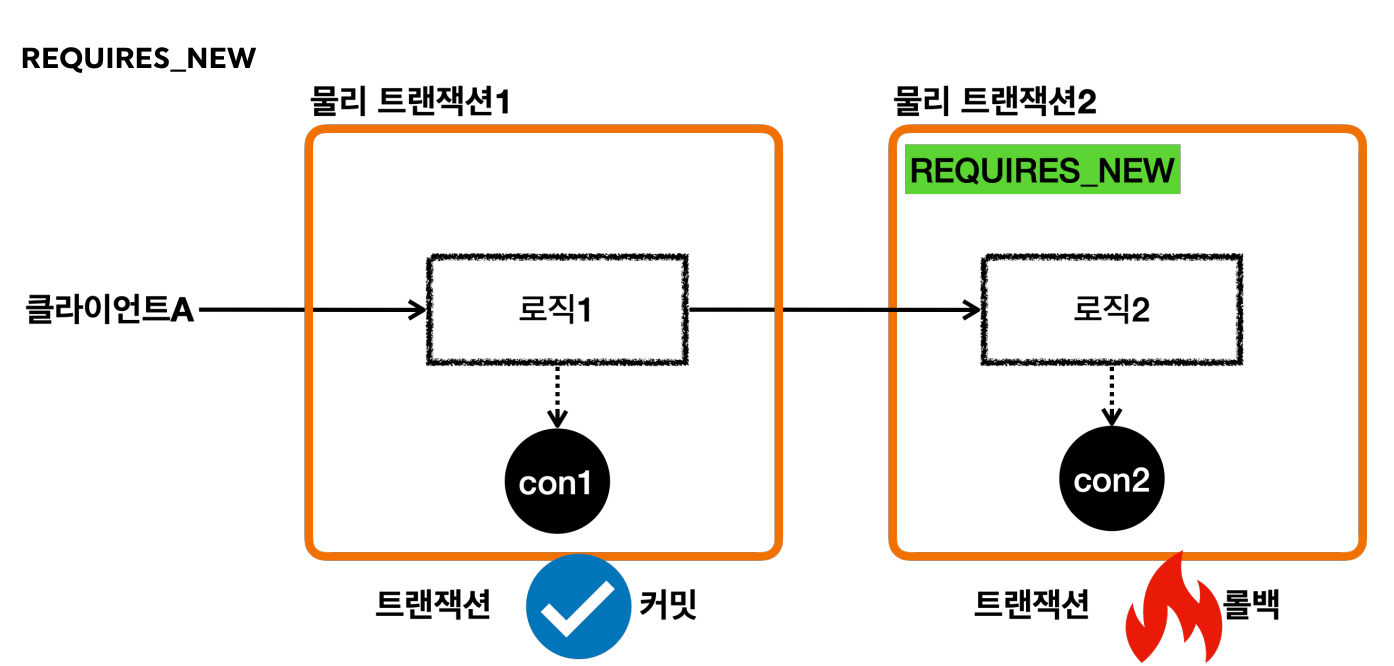
사진과 같이 물리 트랜잭션과 내부 트랜잭션을 분리하기 위해선 REQUIRES_NEW옵션을 사용하면 된다.
- 외부 트랜잭션과 내부 트랜잭션이 각각 별도의 물리 트랜잭션을 가진다.
- 별도의 물리 트랜잭션을 가진다는 뜻은 DB커넥션을 따로 사용한다는 뜻이다.
요청 흐름과 응답 흐름은 다음과 같다.
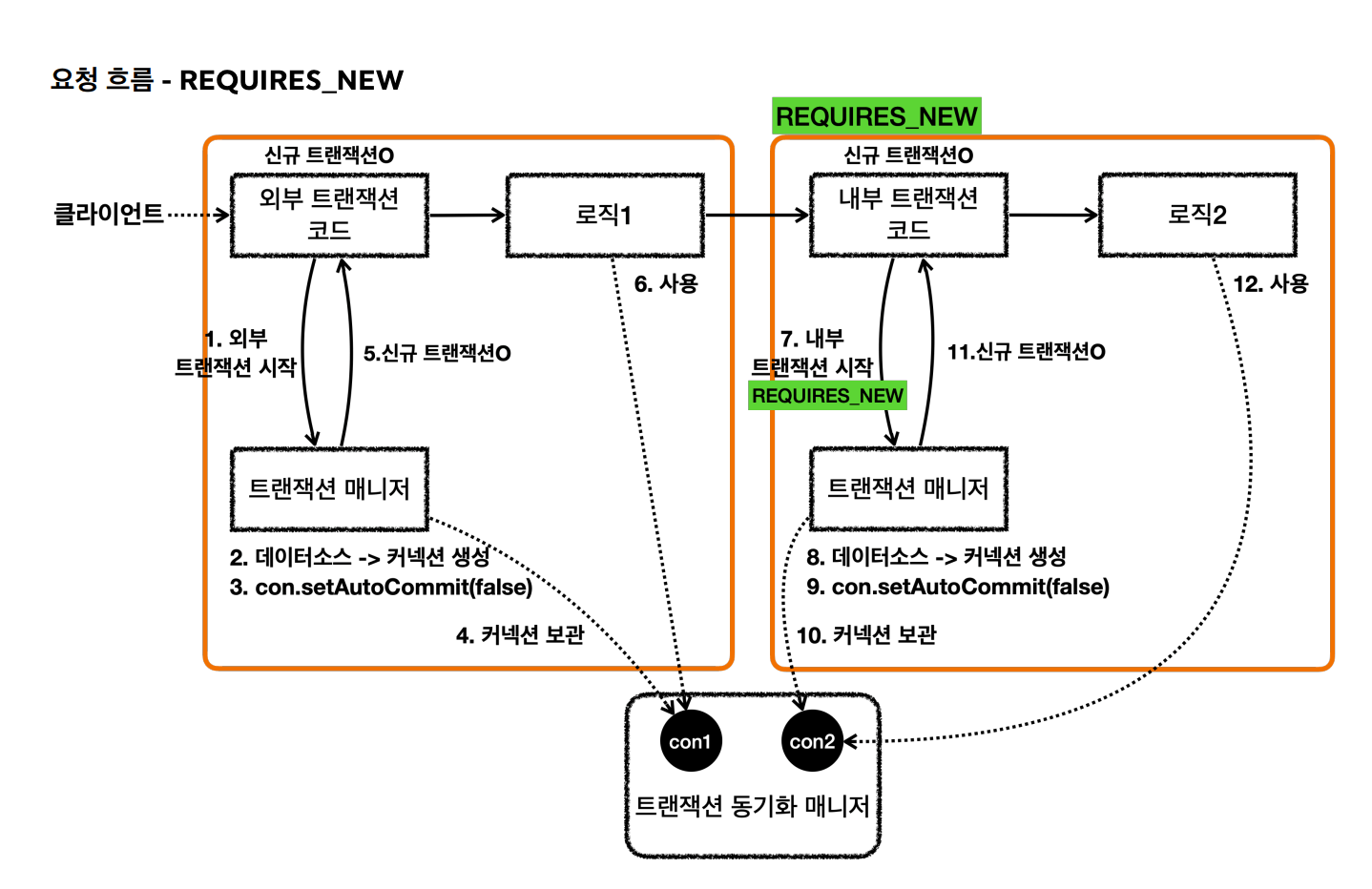
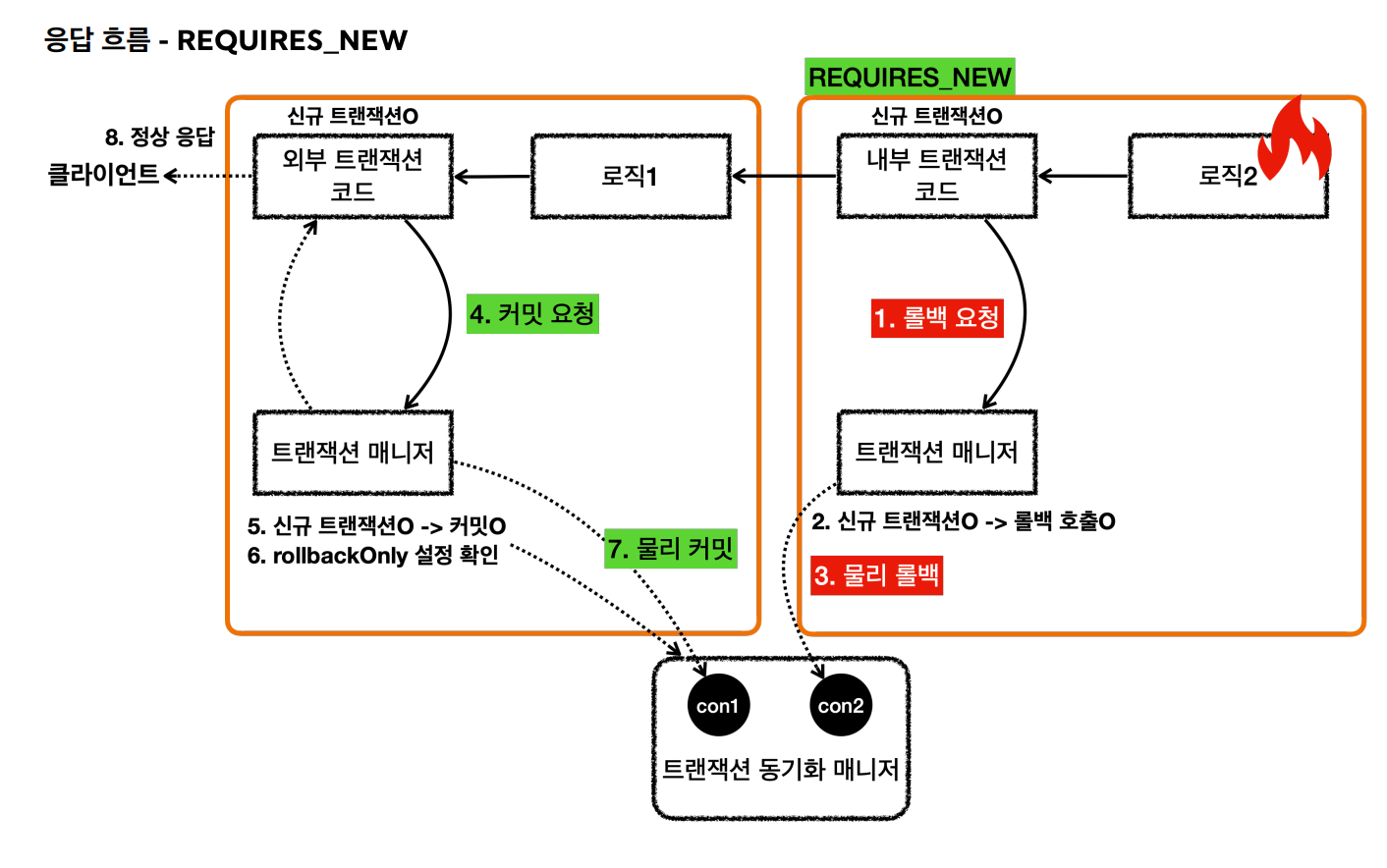
내부 트랜잭션이 신규 트랜잭션인지 확인하고 롤백한다.
정리
- REQUIRES_NEW 옵션을 사용하면 물리 트랜잭션이 명확하게 분리된다.
- REQUIRES_NEW 를 사용하면 데이터베이스 커넥션이 동시에 2개 사용된다는 점을 주의해야 한다.
트랜잭션 다양한 전파 옵션
대부분 기본 설정은 REQUIRED
아주 가끔 REQUIRES_NEW를 사용한다. 나머지는 사용할 때 알아보자
간략히 정리하면
SUPPORT - 트랜잭션을 지원한다는 뜻이다. 기존 트랜잭션이 없으면, 없는대로 진행하고, 있으면 참여한다.
NOT_SUPPORT - 트랜잭션을 지원하지 않는다는 의미이다
MANDATORY - 의무사항이다. 트랜잭션이 반드시 있어야 한다. 기존 트랜잭션이 없으면 예외가 발생한다.
NEVER - 트랜잭션을 사용하지 않는다는 의미이다. 기존 트랜잭션이 있으면 예외가 발생
NESTED - 기존 트랜잭션 없음: 새로운 트랜잭션을 생성한다. / 기존 트랜잭션 있음: 중첩 트랜잭션을 만든다.
(거의 사용안해서 DB가 지원하는지 확인 필요)
10. 스프링 트랜잭션 전파2 - 활용
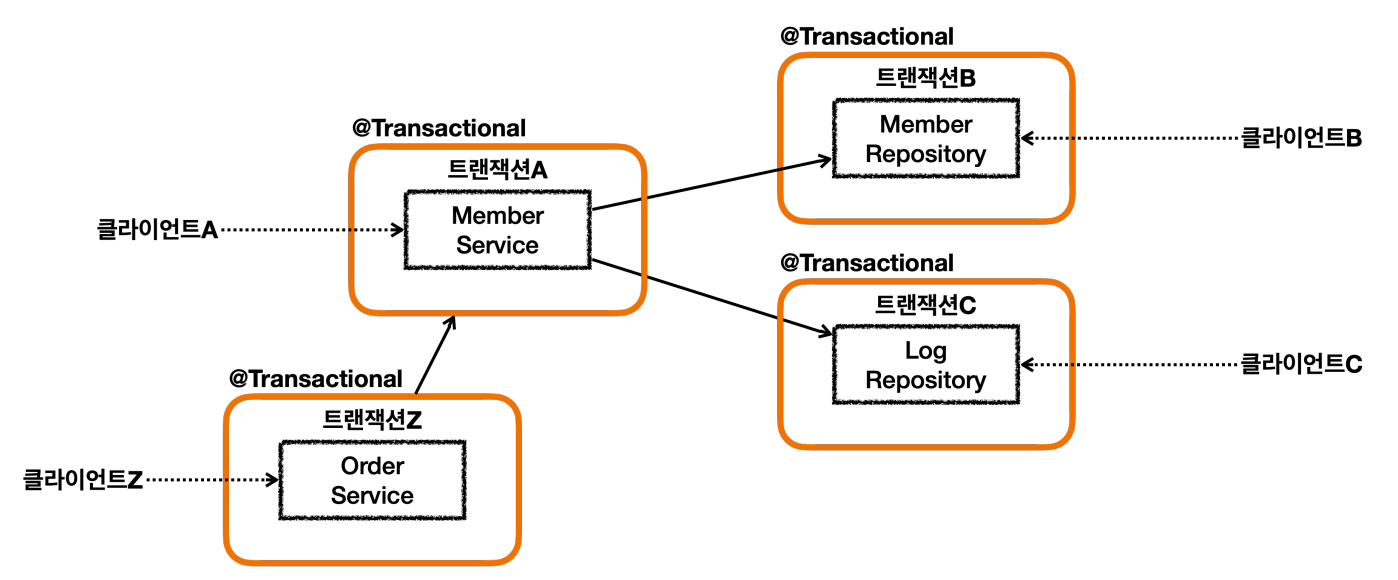
위와같은 복잡한 트랜잭션 문제를 해결하기 위해 트랜잭션 전파가 필요하다.
상황을 가정해보자
회원 가입을 시도한 로그를 남기는데 실패하더라도 회원 가입은 유지되어야 한다.
같은 요청사항이 있을 경우 이전에 배운 것과 같이 service에서 에러를 잡아서 처리하면
될 것 같지만 아래와 같이 에러가 발생해 둘다 롤백이 된다.
해결하기 위해선 물리 트랜잭션을 별도로 분리한다
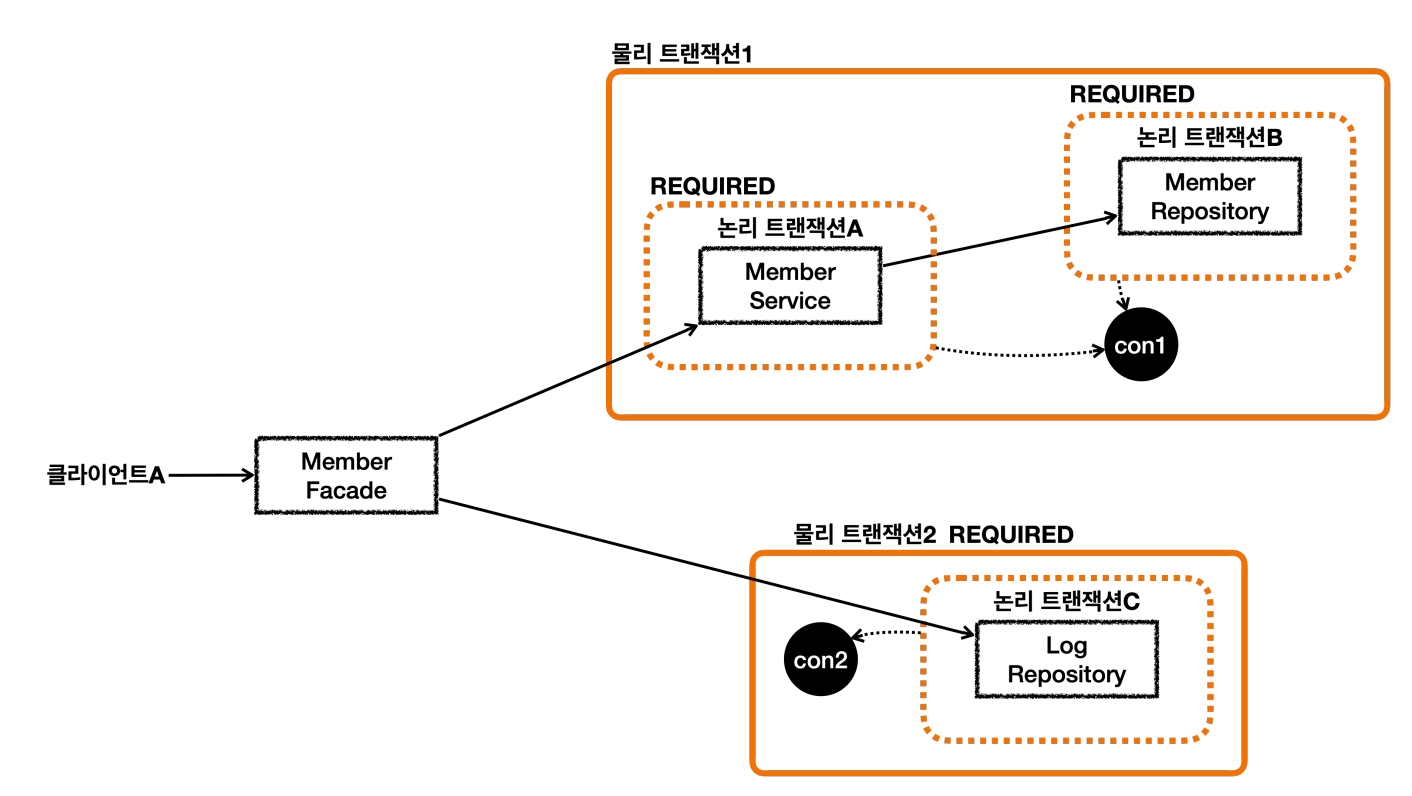
REQUIRES_NEW를 사용
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(Log logMessage)
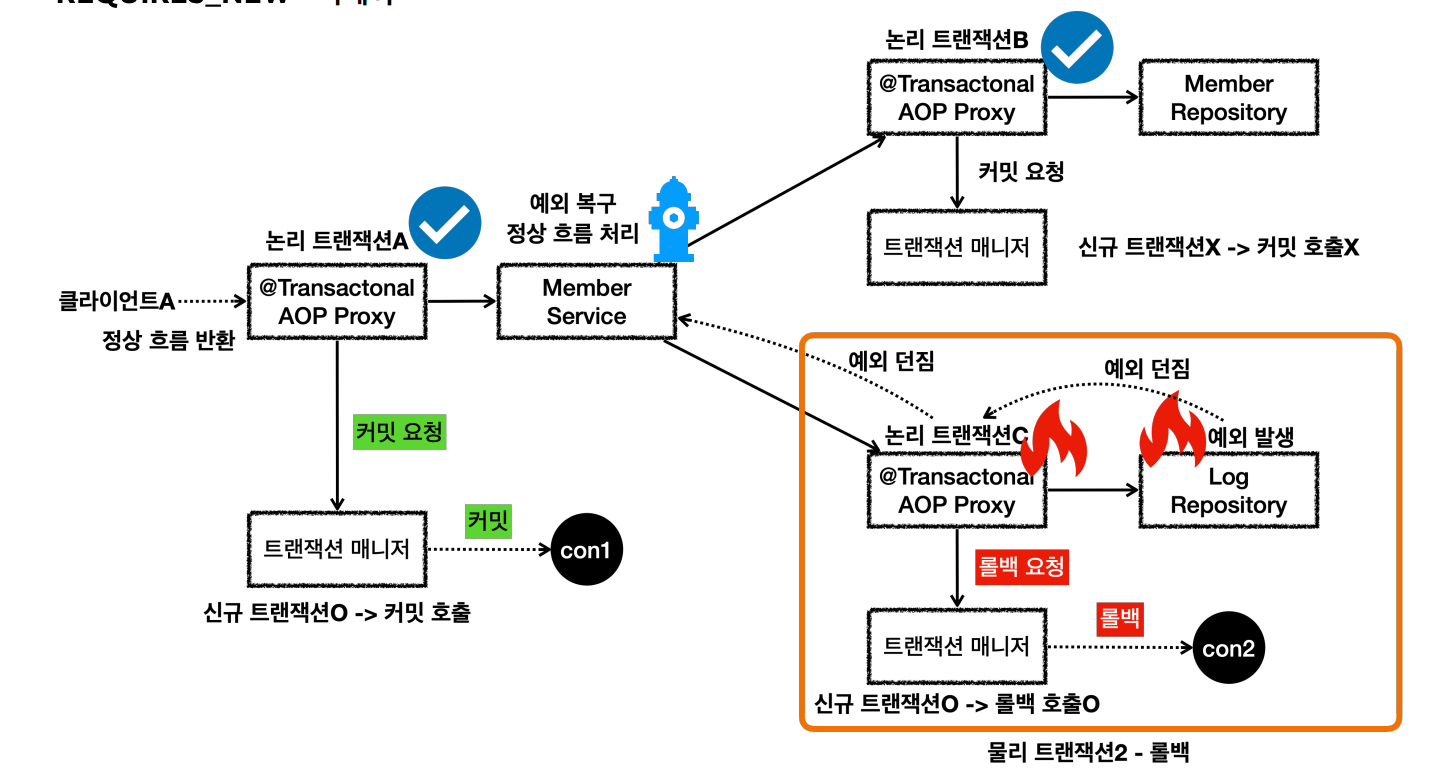
설정값을 넣어주면, 위의 그림처럼 동작하게 된다.
정리
- 논리 트랜잭션은 하나라도 롤백되면 관련된 물리 트랜잭션은 롤백된다.
- 이 문제를 해결하려면
REQUIRES_NEW를 사용해 트랜잭션을 분리한다. - 특정 레포지토리만 트랜잭션을 분리한다고 생각한다.
주의
REQUIRES_NEW를 사용하면 1개의 HTTP요청에 동시에 2개의 DB Connection을 사용한다. 성능이 중요한 곳에서 사용을 주의한다.
더 좋은 방식은 구조를 변경하는 것이다.