




AWS Certified Solution Architect Associate 대비 정리
Udemy강의 정리
1. AWS 개요
1.1 AWS의 구성요소
- Regions, Availability Zone, Data Centers, Edge Locations / Points of Presence
(리전, 가용영역 범위, 데이터센터, 엣지로케이션 / 전송지점)
리전(Region) : 데이터 센터 집합
리전선택에 영향을 줄 수 있는 요인들
- 법률 준수 여부 - 법률 상 데이터가 대상 국가 내에 보관되길 원하는 경우
- 지연시간 - 서비스를 하려는 국가 근처
- 요금 - 서비스 요금
- 리전 테이블을 통해 리전에서 특정 서비스가 제공되는지 여부 확인 가능
가용영역 (Availablility Zone) : 가용영역은 리전 내 존재 (3 ~ 6개, 보통 3개)
- AZ를 표시할 땐 리전코드(국가코드 + 위치(숫자))와 식별문자(소문자) 조합하여 표현
- 각각의 가용 영역은 여분의 전원 네트워킹, 통신기능을 갖춘 하나 또는 두개의 데이터 센터
- 각각의 가용 영역들이 재난 발생에 대비해 서로 분리되어 있다.
- 동일 리전 내 존재하는 복수의 AZ는 서로 물리적으로 격리되어 있지만, 좋은 품질의 네트워크 연결을 통해 논리적으로 연결되어 있다.
- 서비스를 어느 AZ에 배포할 지는 인스턴스를 만들 때 AWS 사용자가 직접 선택할 수 있고, AWS가 사용자를 위해 선택 가능
- AZ에 장애가 발생할 경우
Elastic IP를 사용해 다른 인스턴스에 신속하게 다시 매핑하여 인스턴스나 소프트웨어의 오류를 마스킹할 수 있다.
Edge Locations : 42개국에 200개가 넘는 전송지점 소유 -> 최소 지연 시간으로 사용자에게 컨텐츠를 전달하는데 유용
- 기본 TTL : 24hr
- Cache 기본 저장 시간 : 24hr
1.2 AWS 책임
AWS Shared Responsibility Model에 따르면 보안과 규정 준수는 AWS와 고객의 공동 책임
1.3 AWS Service Level
AWS의 서비스들은 아래와 같이 3종류의 Level 을 가지고 있으며, 각 Level에 따라 해당 서비스에 접근할 수 있는 범위가 달라진다.
- Global Service : ID 및 액세스 관리 (IAM), Route 53(DNS서비스), CloudFront(콘 텐츠 전송 네트워크), WAF(웹 애플리케이션 방화벽)
- Regional Level : VPC, S3, AMI, DynamoDB 등
- AZ Level : EC2, Subnet, EBS 등
항목별로 간단히 설명하면
Global Level은 Region이나 AZ에 상관없이 사용할 수 있다.
Object Storage인 S3를 예로 들면, Regional Level이기 때문에 같은 Region에 있는 서비스(예를 들어 EC2)라면 AZ에 상관없이 S3에 자유롭게 접근할수 있다. 반면에 다른 Region에 있는 EC2라면 기본적인 방법으로는 접근할 수 없다.
lock Storage서비스인 EBS는 AZ Level이기 때문에, 동일 AZ에 있는 서비스만 사용할 수 있다. 반면에 같은 Region이더라도 다른 AZ에 있는 EC2라면 해당 EBS를 사용할 수 없다
화재나 지진 등 AZ단위의 장애발생시 EBS는 영향을 받기 때문에(S3는 영향을 받지 않는다) 장애가 복구되기 전까지는 저장되어 있는 데이터를 사용할 수 없다.
만일 AZ에 문제가 생기더라도 유지되어야 하는 데이터라면, 주기적인 Snapshot을 만들던가 S3같은 Region 단위의 스토리지 서비스를 사용해야 한다.
2. IAM
IAM(Identity and Access Management) : 사용자 생성 및 그룹 배치
- 루트 계정은 첫 번째 IAM 사용자와 몇 가지 계정/서비스 관리 작업을 생성할 때만 사용
- 한사람이 여러개의 그룹을 가질 수 있다. (인라인 정책을 통해 개별 사용자에게 정책 설정 가능)
- 그룹 별 정책 설정 가능
- 사용자 권한 설정은 JSON 문서를 통해 작성 (editor를 통해 추가가능)
- 최소 권한의 원칙 적용
- 태그를 통해 사용자, 그룹, aws 내 리소스에 대한 정보추가 가능
추가로 태그는 AWS내 모든 리소스에 대해 정보 추가하는데 사용!
계정 Tip!
- AWS의 root account는 ID가 숫자형식(계정번호) 인데, 계정에 별칭을 줘서 해당 별칭으로 로그인 가능
- IAM 계정의 aws에 로그인하기 위해서는
https:{별칭}.signin.aws.amazon.com/console로 접속 -> 로그인 페이지로 리다이렉트 해준다.
그룹 Tip!
IAM 사용자 그룹에는 IAM 사용자만 포함
2.1 JSON 정책 문서 구조
- 문서 상단에 위치하는 정책 전반의 선택적 정보
- 하나 이상의 개별 문
IAM 정책은 하나 이상의 문으로 구성됩니다.
| Keyword | Description |
|---|---|
| Version | 사용하고자 하는 정책 언어의 버전을 지정 |
| ID | 정책 식별자 |
| Statement | 이 주요 정책 요소를 다음 요소의 컨테이너로 사용, 정책에 설명문 둘 이상을 포함 가능 |
| Sid(선택 사항) | 선택 설명문 ID를 포함하여 설명문들을 구분 |
| Effect | Allow 또는 Deny를 사용하여 정책에서 액세스를 허용하는지 또는 거부하는지 여부를 설명 |
| Principal(일부 상황에서만 필요) | 리소스 기반 정책을 생성하는 경우 액세스를 허용하거나 거부할 계정, 사용자, 역할 또는 페더레이션 사용자를 표시, 사용자 또는 역할에 연결할 IAM 권한 정책을 생성하면 이 요소를 포함 불가능. 보안 주체는 사용자 또는 역할을 의미 |
| Action | 정책이 허용하거나 거부하는 작업 목록 |
| Resource(일부 상황에서만 필요) | IAM 권한 정책을 생성하는 경우 작업이 적용되는 리소스 목록을 지정, 리소스 기반 정책을 생성하는 경우 이 요소는 선택 사항, 이 요소를 포함하지 않으면 작업이 적용되는 리소스는 정책이 연결된 리소스 |
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "FirstStatement",
"Effect": "Allow",
"Action": ["iam:ChangePassword"],
"Resource": "*"
},
{
"Sid": "SecondStatement",
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "*"
},
{
"Sid": "ThirdStatement",
"Effect": "Allow",
"Action": ["s3:List*", "s3:Get*"],
"Resource": [
"arn:aws:s3:::confidential-data",
"arn:aws:s3:::confidential-data/*"
],
"Condition": { "Bool": { "aws:MultiFactorAuthPresent": "true" } }
}
]
}IAM 정책은 시드, 효과, 원칙, 리소스, 조건
version은 IAM정책 자체의 일부지 문장의 일부 아님
2.2 IAM MFA (Multi Factor Authentication)
- IAM은 기본적으로 패스워드를 각종 정책을 통해 설정이 가능하다
- 길이, 대소문자, 숫자, 기간 등
- 추가로 각종 MFA 디바이스를 사용해 보안강화 가능
AWS는 3가지 방법을 통해 접근 가능
- AWS Management Console : 비밀번호 + MFA
- AWS Command Line Interface : 엑세스 키
- AWS Software Developer Kit : 엑세스 키
2.3 IAM Role & Security Tool
AWS는 서비스에 대한 IAM 설정이 가능
- ex) EC2, Lambda
AWS security tool
- IAM Credentials Report (account - level) / IAM 자격 증명 보고서
- 사용자의 자격증명 상태 표기한 보고서 생성 가능
- IAM Access Advisor (User-level)
- 해당 서비스의 권한과 마지막으로 엑세스 시간 확인 가능
-> tool을 통해 권한 사용 여부를 파악해 최소 권한의 원칙을 지킬 수 있다.
정리해보면 AWS는 IAM기능을 통해 사용자를 추가할 수 있고 사용자에 대한 권한 부여는 정책을 통해 관리한다.
AWS 서비스가 다른 AWS 서비스에 대해 작업을 실행하도록 권한을 부여하려면 IAM Role을 부여 해 권한 설정 가능
tip!
“IAM 사용자 그룹은 다른 사용자 그룹에 속할 수 없습니다”라는 말은, AWS의 Identity and Access Management (IAM) 시스템에서 사용자 그룹 간의 계층 구조를 지원하지 않는다는 것을 의미합니다.
다시 말해, 하나의 사용자 그룹이 다른 사용자 그룹의 하위 그룹이 될 수 없다는 뜻입니다. 모든 사용자 그룹은 독립적이며, 사용자 그룹 안에 사용자 그룹을 포함시키는 구조를 만들 수 없습니다. 대신, 사용자는 직접 특정 그룹에 속하거나, IAM 정책을 통해 권한을 부여받습니다.
예를 들어, 그룹 A와 그룹 B가 있다면, 그룹 A에 그룹 B를 추가하는 것이 아니라, 개별 사용자를 직접 그룹 A나 그룹 B에 추가해야 합니다. IAM의 설계 원칙상, 각 그룹은 독립적으로 관리되고, 사용자 권한은 그룹을 통해 직접 할당됩니다.
3. EC2
Tip! Budgets에 예산을 설정하여 특정 사용량 초과 시 이메일 알람기능 존재
3.1 EC2 Basic
EC2란 Amazon Elastic Compute Cloud의 줄임말로서 AWS에서 제공하는 서비스형 인프라스트럭처
EC2는 단순히 하나의 서비스가 아니라 여러 기능을 포괄하는 개념으로 기능에 따라 분류해보면
- EC2 Instance : 가상 머신 임대
- Network-attached storage : EBS, EFS
- Hardware storage : EC2 Instance Store
EC2 인스턴스는 네트워크 카드와 IP설정이 가능하고 방화벽 규칙을 적용해 보안 기능을 적용할 수 있다.
부트스트래핑이란?
- 머신이 작동될 때 명령을 시작하는 것 ex)업데이트, 소프트 웨어 설치
인스턴스의 이름은 다음과 같은 네이밍 컨벤션이 있다.
t2.micro
t : 인스턴스 클래스
2 : 버전
micro : 인스턴스 클래스 내 크기
인스턴스의 몇가지 종류에 대해 살펴보면
t : 범용 인스턴스 -> 웹서버, 코드 레포지토리
c : 컴퓨팅 최적화 인스턴스(고성능 프로세서 활용) -> batch, 고성능 웹서버, 머신러닝, 게임 등
r : 메모리 최적화 -> 인메모리 DB, 웹 캐시 저장
l, D : 스토리지 최적화 -> 로컬 스토리지의 대규모 데이터 세트에 대한 높은 읽기, 쓰기 엑세스 권한이 필요한 경우 (고성능 DB)
3.1.1 EC2 Security
EC2는 Security Group(보안그룹)을 traffic(InBound, Outbound) 허용 규칙을 설정할 수 있다.
(허용 규칙만 사용)
인스턴스는 여러 보안 그룹을 가질 수 있다
기본적으로 모든 인바운드 트래픽은 기본적으로 차단되고, 아웃바운드 트래픽은 승인된다.
하나의 인스턴스는 여러 보안그룹을 가질 수 있는데 Region, VPC에 따라 적용 된다.
따라서 Region이나 VPC가 변경되는 경우 새로운 보안 그룹을 적용한다
-> SSH 전용으로 별도의 보안 그룹을 관리하는 방법이 좋다.
3.1.2 EC2 Purchasing
| type | description |
|---|---|
| On-demand Instances | 기본 옵션, 장기 약정이나 선 결제 금액 없이 초단위로 사용한 인스턴스에 대한 요금 지불 |
| Saving Plans | 1년 or 3년 기간 동안 시간당 USD로 특정 사용량을 약정해 비용 절감 (약 72%) 초과 시 온디맨드 가격으로 청구 |
| Reserved Instance(RI) | 1년 or 3년 기간 동안 인스턴스 유형 또는 지역을 포함해 인스턴스 구성을 예약하고 비용 절감, Convertible Reserved Instance로 설정 시 인스턴스 타입 변경 가능 거의 변경 못함 |
| Spot Instance | 가장 할인률이 큰데, 짧은 단기 워크로드용 인스턴스로 스팟 가격보다 사용자가 제시한 최고 가격이 더 높을 때만 실행된다 (중단 되어도 되는 App에 적합, DB X) 배치 작업, 데이터 분석, 이미지 처리 및 분산된 워크로드 |
| EC2 Dedicated Hosts | 실제 물리서버 예약, 보안 규정 상 호스트를 타 고객과 공유할 수 없는 수준의 컴플라이언스(compliance)를 지켜야 하는 경우 혹은 기존에 온-프로그레미스 환경에서 보유한 고정 서버 방식의 소프트웨어 라이선스를 재사용하여 비용을 아껴야 하는 경우 가장 비싼 옵션 |
| EC2 Dedicated Instance | 인스턴스를 구동하게 되면 그 인스턴스가 할당된 물리적 서버는 같은 AWS 계정(account)의 인스턴스만 할당되어 사용하는 옵션 |
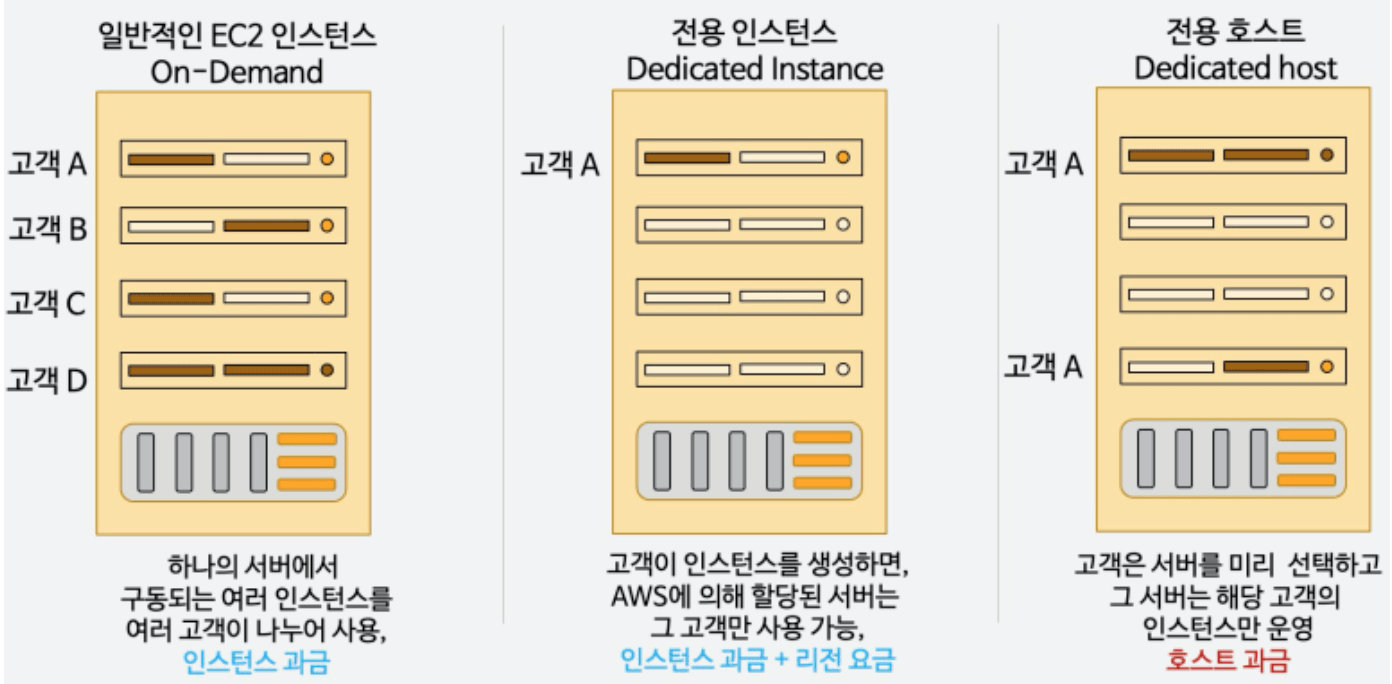
Dedicated Instance -> 하드웨어에 고유한 인스턴스를 가지는 것 / 호텔의 방
Dedicated Host -> 물리적 서버를 점유 (ex - CAD) / 호텔 전부
3.2 Spot Instance
- 온디맨드에 비해 90%까지 할인 가능
- 최대 스팟 가격을 설정하고, 지불하고자 하는 최대 가격보다 낮으면 해당 인스턴스 유지
- 스팟의 요청 유형 2가지
- 스팟 인스턴스의 일회성 요청
- 영구 인스턴스 요청 -> 이 경우 스팟 인스턴스가 종료되어도 다시 실행함 -> 즉, 종료하기 위해선 요청취소 후 관련 스팟 인스턴스 종료
- 데이터 분석, 장애 복원력이 뛰어난 워크 로드에 사용 (중요한 작업이나 데이터베이스에는 적합x)
3.3 Spot Fleets
스팟 인스턴스 세트를 정의하는 방법, 선택적으로 온디맨드 인스턴스 세트와 같이(스팟인스턴스 기반)
스팟 인스턴스를 할당하는 전략이 필요
-
최저가격 -> 가장 낮은 가격인 풀에서 인스턴스 시작 -> 가용성과 긴 워크로드에 적합 -> 하나가 사라져도 다른 하나 활성화
-
가격 용량 최적화 -> 사용 가능한 용량이 가장 큰 풀 선택 -> 그 후에 가격이 낮은 풀 선택
-> 핵심은 여러개의 런치 풀과 여러 인스턴스 유형 정의 가능
Spot Instance vs Spot Fleets
- 간단한 스팟 인스턴스 요청 -> 원하는 인스턴스 유형과 AZ를 정확히 알고있는 경우
3.4 EC2 Placement Group
EC2인스턴스가 AWS 인프라에 배치되는 방식을 제어할 때 사용
세 가지 전략 사용 가능
- Cluster
- 모든 EC2인스턴스가 동일한 가용영역에 있다
- 인스턴스 간 초당 약 10기가 바이트 대역폭 -> 향상된 네트워크
- 지연시간이 짧고, 처리량이 많은 네트워크
- 단점 : 가용영역에 장애 발생 시 모든 인스턴스가 동시에 장애
- 매우 빠른 네트워크로 빠르게 완료하거나, 처리량이 많은 어플리케이션
- Spread
- 실패 위험을 최소화
- 모든 인스턴스가 다른 하드웨어에 위치
- 단점은 가용영역 당 7개의 인스턴스로 제한
- Partition
- 여러 가용 영역의 파티션에 인스턴스 분산
- 최대 7개의 파티션
3.5 ENI(Elastic Network Interfaces)
- VPC의 논리적 구성 요소이며 가상 네트워크 카드를 나타낸다.
- ENI는 EC2 인스턴스가 네트워크에 엑세스 가능하게 함
- ENI는 다른 AZ에 있는 EC2인스턴스와 연결 불가능
=> 인스턴스에 ENI가 존재하고 IP할당이 가능한데, 장애 발생 시 정상적인 인스턴스의 ENI에 IP를 등록해서 장애 조치 가능
3.6 EC2 Hibernate(절전) 모드
절전 모드 시 EC2는 중지되고, RAM의 내용은 EBS볼륨에 덤프된다.
절전모드 사용 사례
- 오래 실행하는 프로세스 중지하지 않고 RAM상태 저장할 때
- 빠르게 재부팅하고 싶을 때
- 서비스 초기화 시간이 길어 중단없이 멈추고 싶을 때
- 온디맨드, 예약, 스팟 등 모든 종류의 인스턴스에 사용 가능
- 루트 볼륨 유형이 EBS볼륨 이어야 한다.
Tip!!
탄력적 IP : 원하는 기간만큼 소유할 수 있는 공용 IPv4, 한번에 하나의 EC2인스턴스에만 연결 가능
3.7 AMI(Amaozn Machine Image)
소프트웨어 구성이 기재된 템플릿
AMI를 토대로 원하는 운영체제, 런타임, RAM, 용량, CPU등이 세팅된 EC2 생성 가능
- AMI는 AZ마다 구축이 되며, 다른 AZ에서 사용할 경우 복사한 다음 사용해야 한다.
- 각 AWS리전에는 고유한 AMI가 있음
Golden AMI는 설치되고 구성된 전체 소프트웨어를 포함한 이미지, 향후 이 AMI로부터 EC2인스턴스를 빠르게 부팅 가능
3.8 EBS(Elastic Block Store)
EBS : 인스턴스가 실행 중인 동안 연결 가능한 네트워크 드라이브 / 네트워크 USB스틱이라고 생각
- 인스턴스가 종료 된 후에도 데이터 유지가능
- CCP level - 1개의 인스턴스에 하나의 ebs 마운트, Associate level 1개의 인스턴스에 다수의 ebs마운트 가능
- 특정 Availability zone에 연결 가능
- ex) us-east-1a에서 생성된 경우 us-east-1b 연결 불가
- snapshot기능 활용 시 볼륨 옮기기는 가능
- EC2 인스턴스를 통해 EBS Volume을 생성하는 경우 종료 시 삭제 옵션이 default(비활성화 가능)
- ex) 인스턴스 시작 후 root 볼륨, EBS볼륨 2가지가 있을 때 인스턴스 삭제하면 root볼륨은 삭제되고, EBS볼륨은 삭제되지 않는다.
EBS는 다양한 볼륨을 가지고 있는데 총 6개의 유형이 있다.
중요한 내용으로는 gp2와 프로비저닝을 마친 IOPS가 있는데 각각 살펴보자
여기서 나오는 IOPS는 (Input/output Operations Per Second)로 저장장치의 속도를 나타낸다.
- gp2는 범용 ssd로 대부분의 워크로드에 이 볼륨을 사용하는 것이 좋다.
- 디스크 크기가 증가하면 IO증가 (5334GB / 16000IOPS IOPS최대 더이상 늘리지 못함)
- io1, io2는 높은 스토리지 성능과 일관성이 필요한 부분에 사용한다. (64000IOPS)
- 독립적으로 IO증가 가능
- st1(HDD)은 자주 엑세스 하고 처리량이 많은 빅데이터나 로그 처리에 적합
- sc1은 접근 빈도가 낮은 데이터에 적합 (백업)
- 부팅 볼륨으로는 gp2, gp3, io1, io2 (ssd)만 가능
추가로 다중 연결 기능을 사용하면 EBS볼륨을 동일한 AZ(가용영역)에 있는 EC2 인스턴스에 첨부 가능
-> io1, io2 제품군에서만 사용이 가능하고 하나의 볼륨은 한번에 최대16개의 EC2 인스턴스에 부착 가능
EBS SnapShot
EBS Snapshot : 특정 시점에 백업 된 EBS 볼륨
AZ에서 EBS 볼륨을 마이그레이션 하려면 Snapshot기능 활용
-> 기능 사용 시 볼륨 내 IO를 전부 사용하니 인스턴스가 EBS를 사용중이 아닐 때만 실행해야 한다.
- EBS Snapshot archive : 75% 저렴하고 복구 시 24시간에서 72시간 소요
- EBS Recycle Bin : 스냅샷 삭제 시 보관, 1일 ~ 1년 설정 가능
- FSR(Fast Snapshot Restore) : 스냅샷 완전 초기화 (가격이 비싸다)
3.9 EFS(Elastic File System)
관리형 NFS(Network File System)
- 많은 EC2 인스턴스에 마운트 가능 (16개 까지)
- 서로 다른 AZ(가용영역)에 있는 EC2도 가능
- 가용성이 높고, 확장성이 뛰어나면서 비용도 gp2 EBS볼륨의 3배 (사용량에 따라 부과, 자동 확장)-> 비싸다
- Linux기반 AMI와만 호환가능
- KMS를 사용하여 미사용 데이터 암호화 가능
- 필요에 따라 I/O를 높은 모드로 사용 가능(default 범용)
- 온프레미스와 연동 가능
EFS는 스토리지 클래스라는 기능이 있는데 자주 엑세스 하지 데이터는 EFS-IA에 저장 가능
- 사용 시 생명주기 정책을 설정해야 한다.
- 비용 절감 가능(90%) 단, 검색 시 비용 발생
3.10 EC2 Instance Store
인스턴스 스토어는 일반 하드디스크와 같은 블록 레벨 스토리지로, 호스트 컴퓨터에 물리적으로 연결된 디스크 위에 위치 -> EBS보다 높은 IOPS가짐
- 직접 연결되어 있어 인스턴스 스토어는 EC2인스턴스에 종속적이다.
- 인스턴스 스토어가 부착되어 있는 인스턴스 타입이 존재
- 인스턴스가 삭제되면 같이 삭제된다.
- 비용은 인스턴스 비용에 포함됨
- 버퍼, 캐시같이 자주 변경되는 임시 데이터, 로드가 분산된 웹 서버 풀과 같은 여러 인스턴스에 복제되는 데이터에 적합
- 고성능 로컬 캐시에 적합 캐시가 소실 되어도 문제 없음
- 인스턴스 중지 시 데이터 손실 문제 -> 솔루션으로 인스턴스 스토어가 있는 다른 EC2인스턴스에 복사본 생성
Tip!!
EBS볼륨 암호화 하는 방법
- EBS스냅샷 생성 -> 복사한 뒤 암호화 옵션 체크 -> 스냅샷 사용해 EBS볼륨 생성
EBS vs EFS
-
EBS는 한번에 하나의 인스턴스와 연결 (io유형 제외)
-
EBS는 하나의 AZ에서만 사용
-
복제하기 위해선 EBS를 스냅샷에 넣고, AZ로 복원
-
EFS는 네트워크 파일 시스템으로 여러 AZ걸쳐 수백개의 인스턴스에 연결하는게 목표
-
다른 AZ에 걸쳐 다른 마운트 대상 가질 수 있다.
-
여러 인스턴스가 하나의 파일 시스템 공유
4. ELB, ASG
확장 종류
- 수직적 확장 : 인스턴스 크기 확장 (RDS, Elastic Cache, EC2), 기능 향상
- 수평적 확장 : 인스턴스 수 확장 (EC2 추가), 스케일 아웃 / 인
- 고가용성 : 수평 확장과 함께 실행 (RDS 다중 AZ, 여러 AZ에서 동일 APP실행)
4.1 ELB(Elastic Load Balancing)
로드 밸런싱이란?
애플리케이션을 지원하는 리소스 풀 전체에 네트워크 트래픽을 균등하게 배포하는 방법
- 로드 분산
- 단일 엑세스 지점(DNS) 노출 (어플리케이션에 사용 가능한 정적 DNS)
- 인스턴스 상태 확인 (ELB Health Checks : 비정상 인스턴스로 트래픽 전송x, Port 4567, /health)
- 웹사이트에 SSL 제공
- App에서 사용할 수 있는 static DNS이름 제공
- ALB의 경우 동일한 클라이언트에 대한 트래픽이 동일한 인스턴스로 리다이렉트 할 수 있는 기능을 제공하는데 ELB Sticky Session이라 한다
- Application 기반 쿠키는 AWSALBAPP라는 이름을 가지고, 로드밸런서에서 생성되는 기간 기반 쿠키는 AWSALB라는 이름을 가짐 (AWSALBTG도 있음)
- 보안 처리 시, 해당 쿠키 제거에 주의해야 함
- ELB상태 확인을 활성화하면 ELB가 비정상 EC2인스턴스로 트래픽을 보내지 않는다.
ALB : HTTP와 HTTPS타입의 트래픽 위한 로드밸런서
NLB : TCP기반의 TLS를 위한 것, 초고성능이 필요할 때
GWLB : 보안, 침입 탐지, 방화벽에 특화
종류
- ALB (Application Load Balancer) : HTTP, HTTPS, WebSocket
- 자신의 이름에 해당하는
리스너 ID, 사용자 요청을 건네줄 판단 기준이 되는규칙보유 - URL경로 기반, 쿼리 문자열과 헤더 기반, 호스트 이름 기반 라우팅
- MSA기반, Container기반 App에 가장 좋은 로드 밸런서 (포트 매핑 기능 존재)
- X-Forwarded-For헤더로 사용자 IP전달해 사용자 구별
- 대상그룹에 EC2인스턴스, 사설IP, Lambda함수
- 자신의 이름에 해당하는
- NLB (Network Load Balancer) : HTTP, HTTPS,TLS, UDP - L4 Load Balancer
- 1 ~ 3개 IP로만 액세스할 수 있는 App만들면 네트워크 로드 밸런서 옵션으로 고려
- AZ당 하나의 정적 IP를 가지며 탄력적 IP할당
- AWS프리티어에는 포함되지 않고 높은 성능이 필요할 때 사용
- 경로, 호스팅 기반 사용 불가
- TCP, HTTPS 및 HTTP상태 확인 지원
- GWLB (Gateway Load Balancer) : 레이어 3(네트워크 계층)에서 작동 (IP프로토콜)
- 네트워크의 모든 트래픽이 방화벽을 통과하게 하거나 침입 탐지 및 방지 시스템에 사용
- 모든 트래픽이 통과
- 6081포트를 사용하고 GENEVE 프로토콜
4.2 Cross-Zone Load Balancing
(영역 간 로드밸런싱) 교차 영역 로드밸런싱을 사용할 경우 모든 AZ의 등록된 인스턴스에 고르게 분산된다.
- ALB : 기본적으로 활성화, AZ간 데이터에 대한 요금 x
- NLB : 기본적으로 비활성화, 활성할 경우 AZ간 데이터에 대한 요금 지불
4.3 SSL / SNI
SSL사용 시 암호화 통신 가능
SNI : 하나의 웹 서버에 여러 SSL을 로드해 여러 웹사이트 지원
최신 프로토콜이며 클라이언트가 초기 SSl 핸드셰이크에서 대상 서버의 호스트 이름 나타내도록 요구 (ALB, NLB, CloudFront에서 작동)
4.4 Connection Draining(등록 취소 지연)
인스턴스가 등록 취소, 비정상인 상태에 있을 때 어느정도 시간을 주어 활성 요청을 완료할 수 있게 설정하는 기능
- 취소중인 인스턴스로 새요청 전송 중지 시간 1~3600 (기본 300)
4.5 ASG(Auto Scaling Group)
트래픽에 따라 ec2 추가 및 제거
- 기능은 무료, EC2 인스턴스와 같은 리소스 비용만 추가
- 스케일링 정책 정의 필요 (최소 크기, 최대 크기, 초기 용량) / 구성하면 최대 용량 넘어설 수 없음
- CloudWatch를 통해 경보 가능
- 정책 설정 시 참고 지표 : CPU사용률, RequestCountPerTarget률(인스턴스 당 요청 수) 등
정책
- Target Tracking Scaling (대상 추적 스케일링) : 기준선 설정 (ex - CPU, 평균 연결 개순)
- Simple / Step (단순, 단계) 스케일링 : 몇가지 조건에 따라 설정
- Scheduled Actions(예약된 작업) : 사용 패턴을 바탕으로 스케일링
- Predictive Scaling(예측 기반) : 시간에 걸쳐 과거 로드를 분석하고 예측된 정보를 바탕으로 스케일링
- Scaling Cooldown : 스케일링 작업이 끝날 때 마다 안정화 시간을 가짐, 새로운 지표의 양상을 살펴보기 위함
- 요청을 빨리 처리하고 cooldown 시간을 줄이기 위해선 즉시 사용 가능한 AMI사용
Instance Refresh
- 모든 EC2 인스턴스 재 생성
- 구성 변경에 따라 인스턴스 교체 할 때, Auto Scaling 그룹에 포함된 인스턴스 수가 많을 때 사용
- AMI에 새로운 데이터 스크립트가 있는 경우 유용
5. RDS, Aurora, ElastiCache
- PostgreSQL, MySQL, Oracle, MSSQL, Aurora
- 백업 및 복원 지원
- 모니터링 대시보드
- DR(재해 복구)를 위한 다중 AZ지원
- 스토리지를 동적으로 늘릴 수 있도록 지원
- RDS는 자동으로 스케일링(오토스케일링)이 되어 최대 저장 임계값 설정 필요
- 보안은 IAM을 통해 관리
5.1 DB 복제
- DB Replica : 최대 15개의 읽기 전용 인스턴스 지원 (약간의 시간차가 있어 데이터가 일치하지 않을 수 있음)
- 같은 지역 / 다른 AZ 무료 , 다른 지역 일 경우 유료
- Multi-AZ 복제(재해 복구) : 가용성 향상 (데이터 항상 일치, 복제 된 예비 인스턴스에서 읽기작업 불가)
- 재해 복구를 대비해 읽기 전용 복제본도 다중 AZ로 설정 가능
- Single-AZ to Multi AZ : 다운 타임이 전혀 없고, DB 수정 클릭 후 다중 AZ기능 활성화
- 내부적으로 1) 스냅샷 생성 2) 새 AZ에 DB 생성 3) 동기화 설정
읽기 전용 복제본은 DNS이름을 갖는 새로운 엔드 포인트 추가해야 함 (App은 개별 참조)
다중 AZ는 활성화 상태의 DB와 관련 없이 동일한 연결 문자열 유지
읽기 전용 복제본은 비동기 복제를 사용하고, 다중 AZ는 동기 복제를 사용함
5.2 RDS Custom
- Oracle 및 Microsoft SQL Server에서만 사용 가능
- SSH또는 SSM관리자를 사용해 RDS뒤에 있는 EC2인스턴스에 엑세스 가능
- RDS가 수시로 자동화 하는 기능은 끄는게 좋다
- EC2에 접근하기 때문에 DB스냅샷을 만드는게 좋음
5.3 Aurora DB
- 복제 프로세스가 MySQL보다 빠르다.
- 읽기 전용 복제본도 15개 까지 가능, MySQL은 5개까지
- 공유 볼륨은 10G에서 128TB까지 자동 확장
- 비용이 20% 높지만 효율적
- 한 리전에서 다른 리전으로 데이터 복제 시 1초 이하의 시간이 걸린다.
- Aurora 글로벌 데이터베이스 사용 시 최대 5개의 2차 리전까지 Aurora 복제본 가질 수 있다.
- MySQL과 PostgreSQL지원 한다. (호환이 가능)
- 스토리지는 기본 설정으로 세 개의 가용 영역에 걸친 6개의 레플리카에 데이터 저장
Aurora Cluster 엔드 포인트 유형
- 클러스터 엔드 포인트 : writer에서 쓰는 엔드포인트, Failover가 발생해서 reader가 writer가 되면 자동 연결
- 리더 엔드 포인트 : reader에서 쓰이는 엔드 포인트
- DNS 기반의 Round Robin방식으로 로드밸런싱 기능 제공
- reader 사용 불가 혹은 삭제같은 갑작스러운 outage 발생 시 다른 reader 사용하도록 유도
- 트래픽 증가 시 복제본 Auto Scaling
- 커스텀 엔드 포인트 : writer, reader 바라볼 지 선택 가능
- 인스턴스 엔드 포인트 : 인스턴스 자체 고유 엔드포인트
Aurora Cluster의 엔드포인트는 단순히 인스턴스를 바라보게 하는 수준에 그치지 않고
load balancing 등 여러 기능을 포함하고 있다.
AWS서비스를 사용한다면 ip 주소나 host이름을 사용하는 온프레미스와는 다르게 가능한 엔드포인트를 사용하여 RDS 및 Aurora Cluster를 사용하도록 권장한다
Aurora Serverless
- 예상할 수 없는 간헐적인 워크로드가 있을 때 위한 것
Aurora Global
- DB가 복제된 리전마다 제공
- 스토리지 복제는 1초 미만의 시간에 일어나며 주로 리전 사이에서 일어남
- 주요 리전에 문제가 있는 경우 두번째 리전을 새로운 주요 리전으로 승급 가능
5.4 RDS 백업
- RDS는 매일 DB전체 백업
- 5분마다 트랜잭션 로그 백업
- 백업 보존 기간은 1 ~ 35일 설정
- 수동 스냅샷은 원하는 기간만큼 백업 유지 가능
- 실제 RDB보다 가격이 저렴
- RDB는 백업 비활성화 가능하지만 Aurora는 비활성화 불가
- S3사용해 RDS 복원 가능
5.5 RDS 보안
암호화
- KMS를 사용해 마스터와 복제본 암호화
- 마스터 DB가 암호화 되지 않은 DB는 암호화된 읽기전용 복제본 생성 불가
- 암호화되지 않은 DB암호화 할 땐, 스냅샷 생성 후 암호화한 뒤 복원 작업을 거쳐야 함
- IAM의 보안그룹 사용하여 네트워크를 통한 DB접근 통제
- 감사 로그 활성화 가능 -> 장기간 보관하고 싶은 경우 Cloud Watch logs 사용
- DB에 ssl 강제 적용 시 모든 DB사용자에게
REQUIRE SSL SQL문 실행
5.6 RDS Proxy
- Proxy를 사용하면 APP이 데이터 베이스로 설정된 연결을 풀링하고 공유 가능
- DB 리소스 부하를 줄이고 커넥션을 최소화 하여 효율성 향상
- 장애 발생 시 장애 조치를 각자 처리하고, 장애 조치와 무관한 RDS Proxy를 연결
- DB에 대한 IAM 인증을 시행하고 자격 증명을 AWS Secrets Manager에 안전하게 저장
- RDS Proxy는 공개적으로 액세스 할 수 없고, VPC에서 엑세스 해야 함
5.7 Elastic Cache
- Elastic cache가 캐싱기술인 Redis또는 Memcached 를 관리하도록 도와준다.
ex) DB캐시, 사용자 세션 저장
시험에서
Redis -> 가용성과 내구성 뛰어난 것 Memcached -> 분산되어 있는 순수한 캐시, 데이터 손실이 괜찮은 경우 (고가용성x, 복제x, 백업x, 복원x)
- 읽기 전용 복제본 최대 5개
캐시 전략
- Write Through : 데이터가 DB에 기록될 때 마다 데이터를 추가 or 업데이트, 쓰기가 길지만 읽기가 빠르고, 데이터가 항상 캐시에 업데이트
- Lazy Loading : 필요할 때만 캐시에 데이터 로드
Redis용 Amazon MemoryDB
- 초고속 성능, 다중 AZ 트랜잭션 로그를 사용한 내구성 있는 인메모리 데이터 스토리지
캐시 제거 및 TTL
3가지 전략 사용
- 명시적 삭제
- 캐시 메모리가 가득 차있거나 사용 하지 않을 때 (LRU)
- 항목 당 사용 가능 시간 설정 (TTL)
6. Route53
Route 53을 통해 DNS 등록 가능
- 사용자가 DNS레코드를 업데이트 할 수 있음
- A, AAAA, CNAME, NS(필수)
- CAA, DS, MX, NAPTR 등 제공
- A : 호스트 이름 (IPv4)
- AAAA : 호스트 이름 (IPv6)
- CNAME : 또 다른 도메인 주소로 매핑시키는 형태의 DNS 레코드 타입
- NS : DNS 서버가 참조하는 다른 DNS 서버
- TTL : 클라이언트가 레코드를 캐시에 저장하는 시간
CNAME vs ALIAS
CNAME : 호스트 이름이 다른 호스트 이름으로 라우팅 가능
ALIAS : 호스트 이름이 특정 AWS 리소스(로드 밸런서, cloud front) 로 라우팅 가능
-
별칭 레코드는 루트 및 비루트 도메인에 모두 작동 (CNAME은 루트 도메인 이름이 아닌 경우에만 가능)
-
ALIAS사용 시 TTL설정 불가능 (Route 53이 자동 설정)
-
ELB, CloudFront, API Gateway, Elastic Beanstalk, S3, VPC, Route 53 Record(Same Hosted Zone)
-
EC2의 DNS 이름에 대해서는 별칭 레코드 불가능
호스팅 영역
퍼블릭 호스팅 영역 : 인터넷에서 트래픽을 라우팅 하는 방법 지정
프라이빗 호스팅 영역 : 하나 이상의 VPC내에서 트래픽을 라우팅 하는 방법 지정
영역당 매월 0.5USD
6.1 Route 정책
-
단순
- 일반적으로 트래픽을 단일 리소스로 보내는 방식
-
가중치
- 레코드에 상대적 가중치 할당
ex) 지역간 로드 밸런싱, 새로운 app버전 테스트
- 레코드에 상대적 가중치 할당
-
지연시간 (Latency)
- 대기시간이 가장 짧은 곳으로 연결
-
장애 조치 (Failover)
- 기본 EC2인스턴스와 보조 EC2인스턴스를 두고 기본 인스턴스가 장애 발생 시 보조 인스턴스로 전송
-
Trffic flow (트래픽 플로우 및 지리적 근접성)
- 사용자 위치 기반으로 라우팅
- 기본 레코드 필수 (위치에 해당하는 항목이 없는 경우)
-
IP
- 사용자 IP기반으로 라우팅
-
다중 값
- 트래픽을 여러 리소스로 라우팅 할 때 사용
Route 53을 DNS 서비스 공급자로 사용 시 퍼블릭 호스팅 영역 생성 및 타사 레지스트리 NS레코드 업데이트
Tip!!
요금 관련 설정
- builing - bills 페이지에서 확인 가능
- 프리티어 사용 시 builing - freetier 페이지에서 사용량 확인 가능
- Cost Management - Budgets 에서 설정한 사용량 초과 시 메일 알림 기능
- 비용 예상 기능을 사용 가능 ( 예산 예측 사용하려면 5주 걸림)
7. Classic Architecture
AWS Elastic Beanstalk
AWS 클라우드에서 애플리케이션을 신속하게 배포하고 관리
Go, Java, .NET, Node.js, PHP, Python 및 Ruby, Docker
- Elastic Beanstalk의 환경 이름은 자유롭게 지정 가능
- zip으로 패키징
- 웹 어플리케이션이나 작업자 환경의 구축에 이용됨.
8. S3
백업이나 스토리지 용도로 사용 (파일 저장, 디스크 저장)
- 파일을 버킷에 저장하는데 최상위 디렉토리 개념이라고 보면 된다.
- 퍼블릭 액세스 차단 기능을 사용해 비공개로 만들 수 있음
- x-amz-server-side-encryption 헤더를 통해 암호화 보장
- 실수로 인한 객체 삭제 방지를 위해 MFA Delete를 사용(루트 계정만 가능)
버킷
- 버킷은 계정에 생성되고 전역적으로 고유한 이름을 가진다.
- 리전 단위로 정의
객체
- 객체는 파일을 말한다.
- 객체에는 키 존재 -> 파일의 전체 경로
ex) s3://my-bucket/my_folder1/another_folder/my_file.txt
-> 키는 접두사(s3://my-bucket/my_folder1/another_folder/) + 개체 이름(my_file.txt) - 버킷 내에는 디렉토리 개념이 없음 (슬래시가 포함된 매우 긴 이름의 키)
- 개체 값은 최대 5TB (5GB가 넘으면 5GB 짜리 1000개로 나눠 올려야 함)
- 메타 데이터를 가질 수 있는데 Key-Value 형태
정책
- Bucket Policies : S3 콘솔의 버킷 전체 규칙 (교차 계정 허용)
- Object Access Control List : 보다 세분화 (비활성화 가능)
- Bucket Access Control List : 보다 세분화 (비활성화 가능)
정책은 json 파일로 명시
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AddPerm",
"Effect": "Allow",
"Principal": "*",
"Action": ["s3:GetObject"],
"Resource": [""]
}
]
}- Resource 속성 : 적용되는 버킷, 객체 정의
- Effect 속성 : Allow / Deny
- Action : 허용하거나 거부할 대상 API (위에선 GetObject)
- Principal : 적용 할 사용자나 계정 명시
추가로 기업의 데이터 유출을 막기위해 Bucket을 공개하지 않는 설정 가능
- S3를 퍼블릭으로 공개하면 정적 웹사이트를 호스팅하고 인터넷에서 액세스 가능
- S3에서 파일의 버전 지정 가능 (버킷 수준에서 활성화)
- 활성화 이전엔 모든 파일의 버전 null
- 버전 관리를 중단해도 이전 버전 삭제x
Replication
- 원본 및 대상 버킷에서 버전 관리를 활성화 해야 한다
- 버전 관리를 활성화 했을 때 이미 존재하던 파일은 null버전
- 적절한 IAM 권한 부여해야 한다.
- 복제는 비동기식으로 백그라운드 에서 진행
- CRR(Corss-Region Replication) : 법규나 내부 체제 관리, 다른 리전에 있어 지연시간 줄일 때, 계정간 복제
- SRR(Same-Region Replication) : 로그 통합, 운영 환경과 개발 환경간의 실시간 복제
- 기존에 있던 객체나 복제가 실패한 객체를 복제할 땐 S3 Batch Replication 기능 사용
8.1 S3 Storage Classes
객체 생성 시 객체 클래스 선택 가능
내구성 : 그냥 파일 손실이 매우매우 적다는 뜻
가용성 : 스토리지 클래스에 따라 다른데 S3 Standard경우 연간 53분 정도 사용 불가
-
1.Standard : 자주 엑세스 하는 데이터, 짧은 대기 시간 및 높은 처리
- ex) 빅데이터 분석, 모바일 및 게임 App
-
2.S3 Infrequent Access : 덜 사용 하지만 필요할 때 접근이 빠르다.
- 비용은 적지만 데이터 조회 시 비용 발생
- ex) 주로 백업 용도
-
3.S3 One Zone-Infrequent Access : 온프레미스 데이터나 재 생성할 수 있는 데이터의 백업
-
4.Glacier Storage Class : 저렴한 객체 스토리지, 아카이브나 백업
- 스토리지 당 비용 발생, 검색 건당 비용
- Glacier Instant Retrieval : 밀리 초 단위 검색, 최소 스토리지 90일, 분기당 한번 액세스
- Glacier Flexible Retrieval : 신속(1
5분), 표준(35시간), 대량(5~12시간), 무료, 최소 보관 90일 - Glacier Deep Archive : 장기 저장용, 최소 보관기간 180일
-
5.S3 Intelligent-Tiering : 액세스 패턴에 따라 객체를 액세스 계층 간 이동 가능
- 월별 객체 모니터링 비용과 자동 이동 비용 발생

8.2 S3 Life Cyle Rule(수명 주기 규칙)
- Transition Actions(전환 작업) : 객체가 다른 스토리지 클래스로 전환되도록 구성
- Expiration Actions(만료 작업) : 일정 시간이 지나면 객체가 만료(삭제) 되도록 구성
- ex) 엑세스 로그파일 365일 이후 삭제, 파일의 이전 버전 삭제
- 특정 접두사에 규칙 생성
Amazon S3 Analytics 사용!
- 객체를 올바른 스토리지 클래스로 전환 할 시기 결정에 도움
- 보고서는 매일 업데이트
S3 Requester Pays
일반적으로는 버킷 소유자가 버킷과 관련된 모든 비용을 지불하는데
인증된 사용자의 경우 대량의 데이터를 받는 요청자가 네트워크 비용을 지불하게 가능
8.3 S3 Event alert
- 원하는 만큼 S3 이벤트 생성 가능
- 객체명 필터링 가능
- 이벤트 알림을 통해 객체 업로드 확인 가능
- SNS, SQS, Lambda Function, Amazon EventBridge으로 전송 가능
- 접근 권한는 SQS, 람다 함수쪽애서 리소스 액세스 정책 정의
- 모든 이벤트는 Amazon EventBridge로 전송
8.4 S3 성능
- S3는 기본적으로 높은 성능, 대기 시간은 100-200ms으로 자동 확장
- 객체 최대크기는 5TB
upload 향상 방법
- Multi-Part Upload : 용량이 큰 파일 저장 시 Multi-Part Upload사용, 병렬 처리 (100MB이상이면 권장, 5GB이상 필수)
- S3 Transfer Acceleration : 다른 지역 S3로 데이터 전달 시 AWS 엣지 로케이션으로 파일 전송하여 전송속도 높인다.
download 향상 방법
-> S3 Byte-Range Fetches
- 특정 바이트 범위 요청하여 병렬화
- 장애 발생 시 복원력 향상
- 다운로드 발생 시 복원력 향상
- 일부 데이터만 활용해 검색하는데 사용
S3 Select
- S3 Select로 CSV 형식으로 S3에 저장된 데이터셋의 일부를 검색해 필요한 부분만 추출 가능
- 속도는 400% 빨라지고, 비용은 80%줄어든다.
S3 Batch Operations
-
한 번에 많은 S3 객체의 메타데이터와 프로퍼티를 수정 가능
-
배치 작업으로 S3 버킷간에 객체 복사 가능
-
암호화되지 않은 모든 객체 암호화 가능
-
직접 스크립팅하지 않고 S3 Batch Operation사용 이유
-> 재시도 관리, 진행 상황 추적, 작업 완료 알림
- S3 Inventory기능 활용해 객체 목록 가져오기
- S3 Select로 객체 필터링
- S3 Batch Operation에 매개 변수와 객체 목록 전달
- 작업 수행
S3 Storage Lens
스토리지 이해, 분석, 최적화
- 이상 징후를 발견, 비용 효율성 파악, AWS조직에 모범 사례 적용 가능 (30일 사용량 및 활동 메트릭을 통해)
- 접두사 별 대이터 집계
- 대시보드를 통해 확인
9. S3 보안
4가지 방법으로 객체 암호화 가능
- SSE (서버 측 암호화, defualt)
- SSE-S3 : Amazon S3 관리 키 사용
- SSE-KMS : AWS의 KMS 키사용 (KMS 서비스 API를 호출하기 때문에 부하가 추가된다.)
- SSE-C : 고객 제공 키 사용
x-zma-server-side-encryption헤더에 -> AES256, aws:kms 추가, SSE-C의 경우 사용자 키 추가
- CSE (클라이언트 측 암호화)
S3 CORS
클라이언트가 S3버킷에서 교차 출처 요청을 하는 경우 활성화해야 한다.
기본 암호화는 SSE-S3를 제공하는데, 위에있는 4가지 방법으로 변경이 가능하다.
9.1 MFA Delete
Google Authenicator or MFA Hardware Device
-> 객체를 영구 삭제할 때 필요
-> 버킷 중단시 필요
9.2 S3 Pre-signed URLs
- URL을 통해 파일 다운로드가 가능하게 설정 가능
9.3 S3 Lock
- S3 Glacier Vault Lock 설정 시 객체 삭제 절대 불가 (정책으로 막음)
- S3 Object Lock
- Compliance mode : 사용자를 포함한 그 누구도 객체 수정 or 삭제 불가
- Governance mode : IAM을 통해 권한을 받은 일부 사용자들만 수정 or 삭제
9.4 S3 Access Log
- S3버킷에 대한 모든 엑세스가 기록된다.
- 로깅 버킷을 모니터링 하면 무한루프 돌아서 기하 급수적으로 커진다. (주의)
- Athena를 사용해 분석
- 사용자 or VPC별로 엑세스 가능한 엑세스 포인트 정의 가능
- AWS Lambda 함수를 사용해 애플리케이션에서 개체를 검색하고 반환 전 람다함수 사용 가능 -> ex) XML to JSON, 이미지 크기 조정 및 워터마킹
- S3 삭제 시 주의하기 위해 MFA 삭제 활성화 기능을 사용해 삭제 시 절차 추가 가능
10. CloudFront, AWS Global Accelerator
짧은 지연 시간과 빠른 전송 속도로 데이터, 동영상, 애플리케이션 및 API를 전세계 고객에게 안전하게 전송하는 고속 콘텐츠 전송 네트워크(CDN) 서비스, DDos공격에 대비하기 위해 Shield와 방화벽 사용
CDN이 나오면 CloudFront를 생각하자
Tip!!
추가로 Cloudflare는 제약이 크지만 무료임 + 엔터프라이즈급에서는 돈내지만 훨씬 쌈 / but 복잡해짐
- 이런 식으로 활용하면 유저의 IP는 X-Forwarded-for헤더에서 추출함
- 이 작업을 위해 nginx access logging 커스텀 설정 필요
CDN이란?
객체의 복사본이 전 세계 여러 위치에 보관되어 있기 때문에 향상된 안전성과 가용성을 제공
- 인터넷 서비스 제공자(ISP,Internet Service Provider)에 직접 연결되어 데이터를 전송하므로, 콘텐츠 병목을 피할 수 있는 장점
- 웹 페이지, 이미지, 동영상 등의 컨텐츠를 본래 서버에서 받아와 캐싱
- 해당 컨텐츠에 대한 요청이 들어오면 캐싱해 둔 컨텐츠를 제공
- 컨텐츠를 제공하는 서버와 실제 요청 지점 간의 지리적 거리가 매우 먼 경우 or 통신 환경이 안좋은 경우
-> 요청지점의 CDN을 통해 빠르게 컨텐츠 제공 가능 - 서버의 요청이 필요 없기 때문에 서버의 부하를 낮추는 효과
- 웹사이트 이미지, 비디오, 미디어 파일 또는 소프트웨어 다운로드 같은 정적 컨텐츠 배포에 적합
엣지 로케이션
- 컨텐츠가 캐싱되고 유저에게 제공되는 지점
- AWS가 CDN 을 제공하기 위해서 만든 서비스인 CloudFront의 캐시 서버 (데이터 센터의 전 세계 네트워크)
- CloudFront 서비스는 엣지 로케이션을 통해 콘텐츠를 제공
- CloudFront를 통해 서비스하는 콘텐츠를 사용자가 요청하면 지연 시간이 가장 낮은 엣지 로케이션으로 라우팅되므로 콘텐츠 전송 성능이 뛰어나다.
- 객체의 복사본이 전 세계 여러 위치에 보관되어 있기 때문에 향상된 안전성과 가용성을 제공
- 콘텐츠가 이미 지연 시간이 가장 낮은 엣지 로케이션에 있는 경우 CloudFront가 콘텐츠를 즉시 제공
Cloud Front동작 방식
콘텐츠가 엣지 로케이션에 있으면 바로 전달, 없으면 최종 버전에 대한 소스로 지정된 오리진에서 검색
CloudFront는 AWS 백본 네트워크를 통해 콘텐츠를 가장 효과적으로 서비스할 수 있는 엣지로 각 사용자 요청을 라우팅하여 콘텐츠 배포 속도를 높인다.
한줄 정리하면 AWS 백본 네트워크를 사용하여 사용자의 요청이 통과해야 하는 네트워크 홉(hop) 수를 획기적으로 줄이고 성능 향상, 낮은 지연 시간 및 높은 데이터 전송 속도를 제공
tip!!
- CloudFront Key Pairs는 Root계정만 생성 가능하다.
- CloudFront가 기존 애플리케이션의 확장성을 높이고, 비용을 절감하는 데 용이
10.1 캐시 요청 정책
캐시의 각 객체는 캐시 키로 식별 - 호스트 이름 + URL 리소스 부분
-
캐시 기반
- CloudFront가 어떻게 캐싱할 지 설정
- 사용자, 디바이스, 언어, 사용자 위치 등을 캐시에 추가가능 HTTP 헤더, 쿠키, 쿼리 문자열
- 3가지 옵션 / Node, Whitelist, Include All-Except
- TTl 정책 설정
-
오리진 요청 정책
- 오리진 요청에는 포함하되, 캐시 키에는 포함x
- 캐시 정책이 아닌 자원을 요청하기 위해 필요한 부분 (HTTP 헤더, 쿠키, 쿼리 문자열)
- 사용자 지정 HTTP 헤더 또는 CloudFront HTTP 헤더를 오리진에 추가
-
응답 헤더 정책
- CloudFront가 응답과 함께 실어보낼 HTTP Header
10.2 캐시 무효화
CloudFront는 Backend Server의 변경사항에 대해 감지할 수 없다 -> 무효화 기능을 통해 수정된 파일이 캐시에 바로 반영되게 설정 가능
- 추가 비용 필요
- 프로젝트가 처음에 수정이 많을 경우 TTl 짧게, 안정화 되면 TTL을 늘려 캐싱을 길게 한다
10.3 캐시 동작
- 주어진 URL 경로에 대해 다른 설정 구성
- 기본 캐시 동작은 마지막에 항상 처리되며 정적 배포와 동적 배포를 분리하여 캐시 적중률을 극대화 가능
-> 정적 콘텐츠는 헤더, 세션 캐싱 규칙 없애고 - S3
-> 동적 콘텐츠는 올바른 헤더 및 쿠키 기반으로 캐시 - HTTP
10.4 Cloud Front ALB or EC2
유저 요청은 크게 2가지 방법으로 요청된다 (ALB 사용 여부)
- user <-> Edge Location <- Allow public IP or Edge Locations -> EC2(public)
- user <-> EDge Location <- Allow public IP or Edge Locations -> ALB <- Allow SecurityGroup of Load Balancer -> EC2(Private)
10.5 Cloud Front - Real Time Logs
실시간 로그를 활성화 한 경우 CloudFront가 수신한 모든 요청은 Kinesis 데이터 스트림에 실시간으로 전송 가능
- Kinesis Data Firehose 사용해 레코드를 배치 처리해서 S3, OpenSearch등 원하는 대상으로 전송 가능
- Kinesis 데이터 스트림에서 엑세스 할 필드나 캐시 동작 (경로 패턴) 지정 가능
10.6 Security
어떤 유료 공유 콘텐츠 액세스를 제공할 때 액세스 권한이 있는지 확인하려고 한다면
URL이나 Cookie에 서명하는 방법 사용
- URL이나 쿠키를 생성하면 정책을 연결해서 URL이나 쿠키의 만료 시점을 지정
- 이 때 클라이언트 IP를 알면 활용
- 음악, 영화같은 콘텐츠는 몇 분 정도로 짧지만, 오래 액세스 할 콘텐츠라면 길게 유지
- Signed URL
어플리케이션에서 CloudFront의 컨텐츠에 접근 할 수 있는 URL을 제공하여 컨텐츠 제공을 제어하는 방법이다.
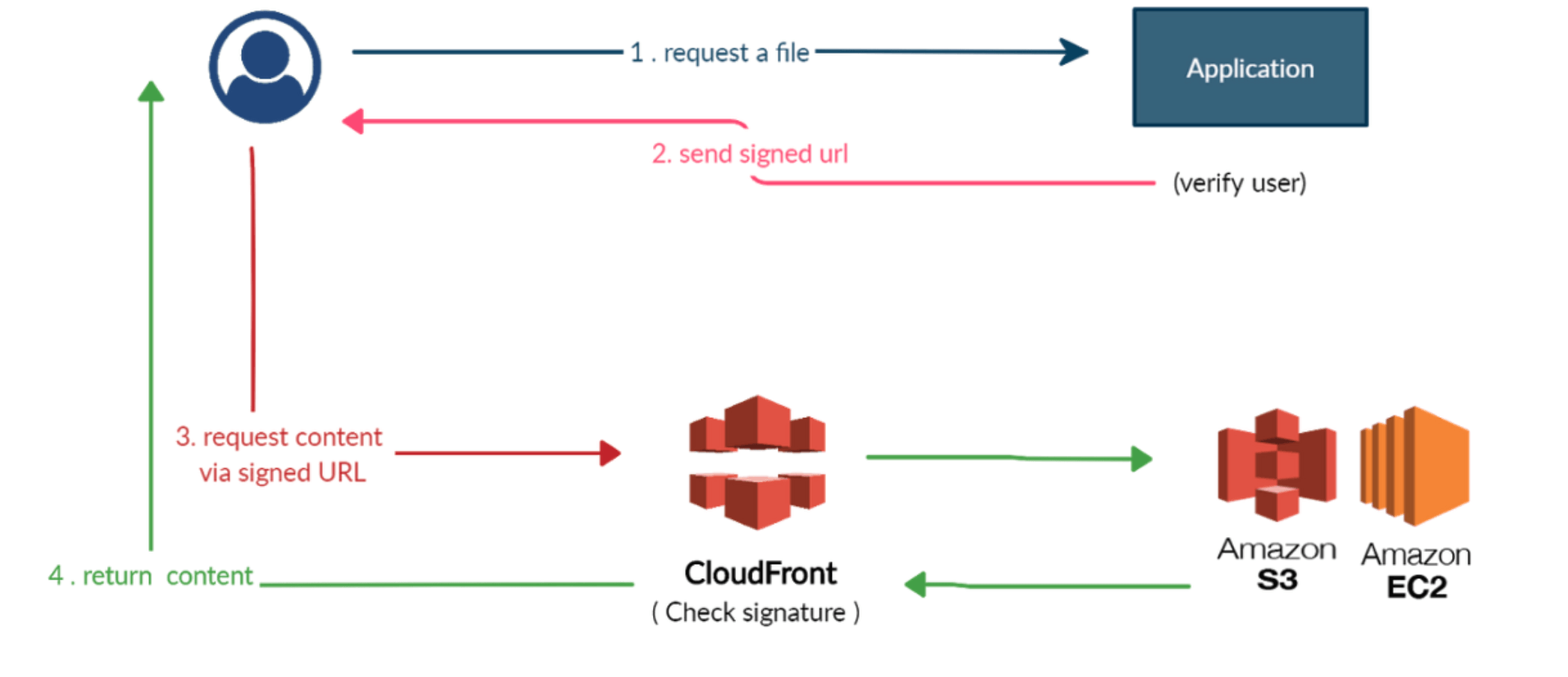
- URL에는 시작시간, 종료시간, IP, 파일명, URL의 유효기간 등의 정보를 담을 수 있음
- 이 URL 접근 이외의 접근을 막고 허용된 유저에게만 URL을 전달하여 컨텐츠 제공을 제어 가능
- 단 하나의 파일 또는 컨텐츠에 대한 허용만 가능
- S3 Signed URL과 비슷한 방식
- Signed Cookie
Signed URL은 하나의 컨텐츠만 제공 제어를 한다고 하면, Signed Cookie는 다수의 컨텐츠의 제공방식을 제어하고 싶을 때 사용된다.
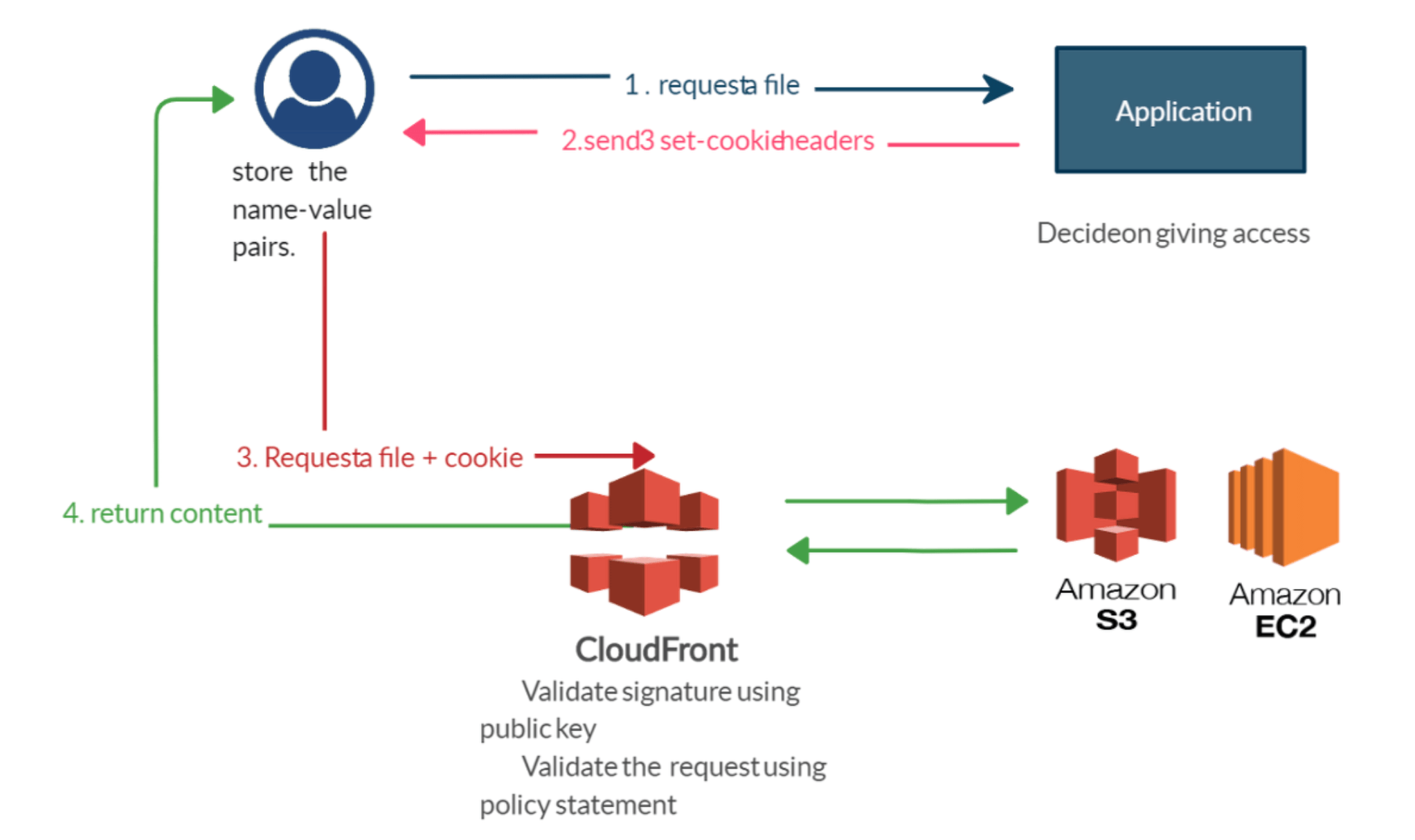
- Signed URL과 마찬가지로 여러 제약사항 설정 가능
- 다수의 파일 및 스트리밍 접근 허용 가능
- 사용사례 : 정기 구독 프리미엄 유저만 볼 수 있는 강의 동영상 등
- Origin Access Identity (OAI)
S3의 컨텐츠를 CloudFront를 사용해서만 볼 수 있도록 제한하는 방법이다.
즉, S3의 정적인 컨텐츠 URL로 바로 접근하는게 아니라 CDN을 통해서 접근하는 것이다.
왜냐하면 S3로 직접 접속을 하면 캐싱을 못해 속도 측면에서 마이너스가 될수 있고, 국가별 라우팅, 인증 등이 CloudFront에 구현 되어있다면 유저가 직접 S3로 접속하면 안되기 때문이다.
- S3는 CloudFront와 잘 맞는다 → 정적인 컨텐츠를 호스팅 하기 때문
- CloudFront만 권한을 가지고 S3에 접근하고 나머지 접근권한은 막음
-> CloudFront는 유저와 S3사이에서 중개하는 역할 - S3 Bucket Policy로 CloudFront의 접근을 허용해야 사용 가능
- Cloud Front를 사용해 데이터를 S3버킷에 전송하여 파일 업로드 하는 것을 인그레스라고 한다.
- Field Level Encryption
- 민감한 정보 보호 시,사용자와 가까운 엣지에서 암호화 (CloudFront부터 Origin 사이 통신 암호화)
- 클라우드 프론트로 보내는 POST요청의 경우 암호화를 원하는 필드를 최대 10개까지 지정 가능
- Edge Location에서 공용키를 사용해 원하는 필드들을 암호화 하고 Web Server에서 비밀키를 활용해 해독
Tip!!
- 암호화 하려는 POST필드 세트 지정(최대 10개 필드)
- 공개 키를 지정하여 암호화

- CloudFront와 S3, EC2간의 지역 단위 재해에 대한 복구가 가능한 아키텍처 구현 가능
10.6 Cloud Front Tip!!
- 특정 지역의 컨텐츠 접근을 제한 가능
- 비용 절감을 위해 엣지 위치 수를 줄일 수 있다.
- Lambda@Edge는 CloudFront의 기능으로, 사용자에 가깝게 코드를 실행하도록 해주어 성능을 향상시키고 지연 시간을 줄여 준다.
10.7 AWS Global Accelerator
- 대부분 비디오 스트리밍이나 VOIP, 게임 등 실시간 고성능 통신
- 애니캐스트씀
- 최대한 빠르게 AWS 엣지 로케이션으로 가기위해서 가까운데로 감
- 두개의 고정 ip제공함
- IoT , Voice over IP , 비HTTP를 사용할 때 매우 굿
- 결정적이고 신속한 리전장애 조치가 필요할때도 좋다.
Tip!! Global Accelerator vs CloudFront
- CloudFront는 이미지나 비디오처럼 캐시 가능한 내용, API가속, 동적 사이트 전달같은 동적 내용 모두 성능 향상
- 캐시된 내용 전달
- Global Accelerator는 리전으로 프록시, 캐시가 아님
11. AWS Storage 추가 기능
AWS Snow Family
2가지 사용 사례를 가진 매우 안전한 휴대용 장치
- Snow Family (물리적장치)
- Data migration : Snowcone, snowball Edge, Snowmobile
- Edge computing : Snowcone, Snowball Edge
오프라인에서 데이터 마이그레이션을 실행하는 장치
만약 일주일이상 걸린다면 snow Family 써야함
Snowball Edge
- Storage 80TB 하드 용량
- Compute 42TB 하드 용량
- 재해복구나 대용량 데이터
- 컴퓨팅능력을 갖고 있다
Snowcone
- 크기가 훨씬 작다
- 가혹한 환경을 견딜수 있다. 물속 사막 드론도 OK
- Data sync로 온라인, 오프라인도 가능
- 8TB 10배 작다
Snowmobile (트럭)
- 100 PB
- 보안성 안정성 뛰어나다
- 10PB 이상에 데이터를 전송 시 사용
Edge Computing
- 클라우드에서 멀리있는곳은 무엇이든 해당됨
- EC2 인스턴스와 람다펑션 사용가능 (AWS IoT Greengrass)
Tip!!
- Snowball은 Glacier에 데이터를 직접 끌어올 순 없다.
- 무조건 S3의 수명 주기 정책을 통해서만 갖고 올 수 있다.
Amazon FSx
- 완전 관리형 서비스로 타사 고성능 파일 시스템을 실행
- RDS -> FSx
- FSx for Windows File Server
- 완전 관리형 Windows 파일 서버 공유 드라이브
- SMB프로토콜, NTFS 지원
- Windows뿐만 아니라 Linux EC2도 지원
- 분산 파일시스템 DFS를 이용하면 파일시스템을 그룹화 가능
(온프레미스의 Windows 파일 서버와 FSx for Windsows 서버 결합)
- FSx for Lustre
- 고성능
- 동영상 처리나 금융 모델링 전자 설계 자동화 등의 애플리케이션에서 쓰임
- 확장성이 높음
- S3와 무결절성 통합이 가능 (FSx로 S3를 파일시스템처럼 읽어들일수있음)
- FSx의 연상 출력값을 다시 S3에 쓸 수 있다.
- VPN과 직접 연결을 통해 온프레미스 서버에서 사용가능
- FSx for NetApp ONTAP
- 높은 운영체제 호환성
- 온프레미스의 ONTAP이나 NAS에서 실행 중인 워크로드를 AWS로 옮길 수 있다
- NFS, SMB, iSCSI프로토콜과 호환
- 스토리지는 자동으로 확장 및 축소된다. (오토스케일링)
- 복제와 스냅샷 가능
- 비용도 적게듬 중복제거가능
- 지정시간 복제기능 , 새 워크로드 등 테스트할때 좋음
- FSx for OpenZFS
- 관리형 ZFS파일 시스템
- 여러 NFS프로토콜과 호환
- 스냅샷, 압축을 지원하고 비용적지만 데이터 중복제거는 X
- 지정시간 복제기능, 새 워크로드 등 테스트할때 좋음
Storage Gateway
- AWS에서는 하이브리드 클라우드 시스템 권장
- 하드웨어인 게이트웨이가 온프레미스 서버에 인터넷 or 직접 연결이 되는 형태
- S3 데이터를 온프레미스에 두려면 AWS Storage Gateway 활용
- AWS Storage Gateway를 이용해서 온프레미스 데이터를 클라우드로 이동
- 대부분을 AWS에 저장하고 파일 액세스 지연 시간을 줄이기 위해 AWS Storage Gateway를 온프레미스 캐시로 사용
- Gateway가 회사에 설치되어 있어야함
- 설치안되어있으면 하드웨어 어플라이언스 (AWS에서주문)
- S3 File Gateway
- Glacier은 불가
- S3버킷을 온프레미스상의 Application과 연결할 때 표준 네트워크 파일 시스템 활용
(NFS나 SMB프로토콜)
- FSx파일 게이트웨이
- Amazon FSx for Windows File Server에 네이티브 액세스를 제공
- 그렇다면 번거롭게 Amazon FSx를 생성하려는 이유 -> 게이트웨이를 생성 -> 자주 액세스하는 데이터의 로컬 캐시를 확보
-> 엑세스 시 지연시간 단축 - SMB, NTFS, Active Directory와 호환
- 볼륨 게이트웨이
- 볼륨 게이트웨이 사용하면 온프레미스 서버에 볼륨 마운트 가능
- 블록 스토리지로 Amazon S3가 백업하는 iSCSI 프로토콜을 사용
- 볼륨이 EBS 스냅샷으로 저장되어 필요에 따라 온프레미스 볼륨을 복구
- 2가지 유형
- 캐시 볼륨 : 엑세스 지연시간 낮음
- 저장 볼륨 : 전체 데이터가 온프레미스에 있으며, 주기적으로 Amazon S3백업
- 테이프 게이트웨이
- 물리적으로 테이프를 사용하는 백업 시스템이 있는 회사가 백업에 테이프 대신에 클라우드를 활용해 데이터를 백업
- iSCSI와 호환 가능한 인터페이스
게이트웨이는 데이터 센터에 설치되어 있어야 한다
-> 이 서비스는 Storage Gateway 하드웨어 어플라이언스
Data Sync
데이터를 동기화하며 이를 통해 대용량의 데이터를 한 곳에서 다른 곳으로 옮길 수 있다
- 모든데이터 동기화 가능 (Glacier 포함 , EFS, FSx도 가능) SFTP x
- 파일을 한곳에서 다른곳으로 옮길때 이를 이용하여 파일의 메타데이터를 보존 가능
- Snowcone 장치에 DataSync에이전트가 사전에 설치되어 있다.
- 서로다른 AWS 스토리지 서비스간 메타데이터 또한 유지
- 지속적이지 않고 일정에 따라 움직인다.
- JSON 파일과 같은 데이터를 실시간으로 S3로 전송할 수 있음
S3 한번 더 정리
- 객체 아카이브 할 떄는 S3 Glacier
- 한번에 한개의 EC2인스턴스에만 EBS사용
- IO1, IO2는 다중 연결 가능
- 고성능 물리 스토리지 필요한 경우는 EC2 Instance 스토리지 사용
- 인스턴스가 네트워크 파일 시스템을 필요로 하고, 마운트 하면서 POSIX파일 시스템 사용하면 Amazon EFS서비스 사용
- FTP, FTPS, SFTP인터페이스가 필요한 경우엔 AWS Transfer Family사용
- 데이터를 옮기는데 네트워크 용량이 없거나, 물리적으로 대용량 옮겨야 하는 경우엔 Snow~~ 사용
12. SQS, SNS, Kinesis, ActiveMQ
대기열 모델 -> SQS
pub / sub모델 -> SNS
실시간 스트리밍, 대용량 데이터 -> Kinesis
12.1 SQS
- 시험에 분리 나오면 SQS
- 특징은 무제한 처리량
- 초당 원하는 만큼 메시지 전송, 대기열도 원하는 만큼
- 대기열 기본값 4일 최대 14일
- 며칠간 보관하고 향후 처리 가능
- 메시지가 작아야 한다 (256KB)
- 중복메시지 존재 가능
- 확장이 가능한 유형의 아키텍처
- 트래픽이 증가되면 알아서 자동 스케일링
Message Visibility Timeout (가시성 시간 초과)
Amazon SQS가 다른 소비자들의 메시지 재수신 및 재처리 막는 기간
- 가시성 시간내에는 메세지가 다른 소비자에게 보이지 않음 -> 시간 내 처리 안하면 2번 처리될 수 있음
-> 소비자는 ChangeMessageVisibility API를 호출해 SQS에 알려야 함 - 가시성 시간 초과를 증가하면 소비자들은 더 오랜 시간 동안 메시지 처리 가능
Long Polling
- 시험 - SQS대기열에대한 API호출 수 최적화하고 지연시간 줄이는법 = 롱폴링
FIFO (선입선출)
- 처리량에 제한을 할 수도 있음
- 이름에 .fifo 붙혀야함
- 메시지가 순차적으로 한번만 처리 된다.
12.2 SQS + ASG (Auto Scaling Group)
- ASG에 SQS대기열 사용 가능
ASG내의 EC2인스턴스의 메시지를 SQS에서 폴링 -> 자동으로 대기열 크기에 따라 확장
CloudWatch의 ApproximateNumberOfMessages라는 지표 -> 대기열에 몇개의 메시지가 남았는지 표기
예를 들어 위의 지표가 1000이 넘을 경우 메시지가 대기열에서 처리하는 걸 기다리고 있으니
경보를 발생하여 ASG에 알려 EC2확장 / 축소도 이와 동일
- 쓰기 대상 데이터베이스에서 SQS를 버퍼로 활용 가능
12.3 SNS (Simple Notification Service)
분산 시스템 및 서버리스 어플리케이션을 분리할 수 있는(decoupling) 고사용성, 완전 관리형 pub/sub 메시지 서비스
- Topic당 최대 구독자는 12,500,000명
- Topic은 100,000개로 제한
- 이를 통해 MSA 분리 가능하게 한다
- 한번에 송수신 되는 대용량 메시지를 처리 불가능한 경우가 있고, 데이터 간 송수신 순서를 보장하지 못한다.
- 이벤트 트리거로 이용 가능
- Messgage Filtering
- JSON 필터링을 이용해서 Filter Policy로 필터링가능
- ex) 발주 완료 여부 체크해서 다른 SQS Queue에 보냄
- 구독자로 SQS, HTTP Endpoint, Lambda, Kinesis Data Firehose 지원하지만 Kinesis Data Streams지원 안함
- 이메일 알림 보내려 할 때 도움되는 AWS서비스
12.4 SNS + SQS : Fan out패턴
SNS 토픽으로 한번 메시지 전송하고 원하는 만큼 SQS대기열을 SNS토픽에 구독시키는 것
이러한 패턴을 사용하기 위해선 SQS대기열 접근 정책을 SNS토픽이 SQS대기열에 쓸 수 있게 허용해야 한다.
12.4 Kinesis
실시간 스트리밍 데이터를 손쉽게 수집하고 처리하여 분석 가능
4가지 서비스로 구성되어 있음
- Kinesis Data Stream
확장성과 내구성이 뛰어난 실시간 데이터 스트리밍 서비스
- 시작할 때 스트림은 몇개의 샤드로 구성하겠다고 결정해야함(프로비저닝)
- 레코드는 파티션키와 데이터블롭(up to 1MB)으로 구성 1MB/sec
- 파티션키는 레코드가 이용할 샤드를 결정하는 데 사용
- 파티션키를 해싱해서 보냄
- Kinesis Data Streams에서 Cunsumers로 가는 레코드는 파티션키, 시퀀스 no, 데이터블롬 세가지
-> 2MB/sec, 불변성 ,한번 들어오면 삭제불가능 ,리얼타임 - 데이터는 1일에서 365일저장
- 생성자 소비자에 커스텀 코드 작성 가능
- 용량제한은 샤드수에의해 결정됨
- 2가지 모드 존재 (On-demand, Provisioned)
- 사전에 사용량 예측 x - 온디맨드 / o - 프로비저닝
- 트래픽 때문에 문제생기면 더 많은 샤드 추가해야 함
- 실시간으로 초당 기가바이트 데이터 포착이 가능하고, 리플레이 기능을 통해 여러 개의 소비 애플리케이션으로 전송 가능
- Kinesis Data Firehose
데이터 스트림을 AWS내부나 외부의 데이터 스트림 분석
- S3, RedShift, Amazon OpenSearch로 전송 가능
- 거의 실시간 서비스
- 바로 전달해주는 느낌
- Kinesis Data Analytics
SQL언어나 Apache Flink를 활용해 데이터 스트림 분석
- 데이터 스트림에 대한 실시간 분석 작업을 수행
- Kinesis Video Stream
비디오 스트림을 수집하고 처리하여 저장
Kinesis vs SQS Ordering
- 키네시스는 샤드당 나눠서 가짐 / SQS는 전부 나눠가질 수 있음
Tip!!
- SQS : pull model, 다른 소비자가 읽을 수 없게 처리 필요, 작업자, 소비자 제한 x,
- SNS : pub/sub 모델, 팬 아웃 아키텍처 이용 시 SQS와 결합
- Kinesis : 실시간 빅데이터, ETL/ 프로비저닝 모드 미리 원하는 샤드양 지정, 온드맨드 알아서
12.5 AmazonMQ
RabbitMQ와 ActiveMQ 두 가지 기술을 위한 관리형 메시지 브로커 서비스
- 기존에 사용하던 프로토콜(ex-mqtt,anqp)등 사용하고 싶을 경우 Amazon MQ사용하면 된다.
- 확장성이 크진 않음
- 활성/대기 브로커가 두 가용 영역에 걸쳐 구성되면, 하나의 가용 영역에 문제가 생겨도 다른 하나가 계속 작동하기 때문에 가용성이 높아짐
13. ECS, Fargate, ECR, EKS
Docker란? - 앱 배포를 위한 소프트웨어 개발 플랫폼 (컨테이너 기술)
- 컨테이너에 앱 패키징
- 컨테이너는 표준화 되어있어 아무 운영체제나 실행 가능
- 유지 및 배포가 쉬움
ECS : Docker관리를 위한 Amazon전용 플랫폼
EKS : Kubernetes
Fargate : Amazon 서버리스 컨테이너 플랫폼 ECS, EKS 둘다 함께 작동 가능
ECR : 컨테이너 이미지 저장에 사용
13.1 ECS
ECS의 유형으론 크게 2가지가 있다.
첫번째론 EC2 Launch Type

- ECS클러스터는 여러 요소로 이루어지는데 EC2를 시작 유형으로 사용할 땐 EC2인스턴스가 그 요소에 해당
- EC2활용 시 인프라를 직접 프로비저닝 및 관리
두번쨰는 EC2 Fargate Launch Type

이 유형의 경우는 관리할 EC2 인스턴스가 없다. (서버리스)
Fargate 유형에서 ECS 클러스터를 사용하는 경우 ECS 태스크만 정의하고 나면 AWS에서 CPU와 RAM 요구사항을 토대로 ECS 태스크를 실행한다.
확장하려면 태스크 수만 늘리면 된다.
- Cloud Watch로 ECS CPU사용량 확인이 가능하다
- 보안 그룹은 ECS에 별로 중요하지 않음, 대부분 IAM 관련
13.2 ECR (Elastic Container Registry)
Docker Image저장, 관리, 공유 및 배포할 수 있도록 해주는 컨테이너 레지스트리
- 이미지 취약점 스캐닝, 버저닝 태그 및 수명주기 확인 지원
13.3 EKS
- EC2 시작모드는 작업자 모드는 배포할 떄 사용 (EC2처럼)
- Fargate모드는 EKS 클러스터 내 서버리스 컨테이너 배포할때 사용
- 데이터볼륨을 연결하려면 EKS 클러스터에 스토리지 클래스 매니페스트를 지정해야함
- 컨테이너 스토리지 인터페이스 (CSI) 규격 드라이버
-> EKS 클러스터에서 EBS를 사용할 수 있게 해주는 기능
13.4 App Runner
웹어플리케이션, API배포를 돕는다
- 오토스케일링 가능, 가용성 높다, 로드밸런싱, 암호화
- 빨리배포해야하는 앱 웹
14. Serverless
- 서버가 없다x 서버를 관리할 필요가 없다o
- Gateway + lambda
- 확장성과 유연성에 탁월
14.1 Lambda Function
- 제한시간이 있어서 실행시간이 짧음, 최대 15분
- 온디맨드로 실행
- 함수가 실행되는동안에만 과금
- 자동 스케일링
- 변동성이 높은 워크 로드에 유용
- 확장성이 좋고, 사용량이 변동할 때도 자동으로 스케일링을 처리
- 정적파일 저장하면 효율적(사진)
- 람다에 컨테이너를 실행해야 할 경우 해당 컨테이너가, 람다 런타임 API를 구현하지 않으면 ECS나 Fargate에서 컨테이너를 실행
- lambda가 SQS를 실행하지 못하는 경우는 IAM권한이 없을 때
lambda 한도
- 시험에 자주 나옴
- 한도는 리전 당 존재
- 실행한도
- 실행 시 메모리 할당량은 128MB ~ 10GB
- 메모리는 1mb씩 증가
- 최대 실행시간은 15분
- 환경 변수는 4KB
- 최대 1000개까지 동시 실행 가능
- 배포 한도
- 압축 시 최대 50mb, 압축 안하면 250mb
- 환경변수 한도는 4KB
Lambda Snapshot
- Lambda함수의 성능을 높이기 위한 기능
- JAVA 11이상에서 실행되는 Lambda함수들의 추가 비용 없이 성능 10배 상승
- 해당 기능 하용 시, 함수의 초기화 없이 호출 된다.
CloudFront Functions, Lambda@Edge
사용 사례
- 웹사이트 보안과 프라이버시
- 동적 웹 어플리케이션
- 검색 엔진 최적화 (SEO)에도 가능
결론
- CloudFront Function이 대용량 처리, 더 빠르다
Lambda in VPC
- lambda는 기본적으로 외부 -> 프라이빗 RDS와 연결하려면 vpc내부에서 lambda실행 해야 한다.
- VPC에서 lambda를 사용하는 대표적인 사례는 RDS프록시
- DB연결 풀링과 공유를 통해 확장성 향상
- 장애 발생 시 조치시간을 66%줄여 가용성 향상
- RDS프록시 수준에서 IAM인증을 강제하여 보안성 향상
14.2 DynamoDB
- 데이터가 다중 AZ간에 복제되서 가용성이 높다
- NoSQL
- 트랜잭션 지원
- 비용이 적고, 오토 스케일링 기능 탑재
- 속성 추가가 쉬움
- 항목의 최대 크기는 400KB
- 시험에서 스키마 빠르게 전개 나오면 dynamoDB
- 프로비저닝 모드 / 온디맨드 모드
- 시험에 나옴
- 온디맨드 모드는 수백만개의 트랜잭션으로 1분내 확장 -> 온디맨드 / 프로비저닝은 적합x
- JSON형태로 S3에 내보낼 떄 테이블 선택 후 S3로 내보내기
- 키-값 저장소로 Elastic Cache대체 가능
- 보안, 인증, 승인 모든게 IAM으로 이루어 진다
DAX (DynamoDB Accelerator)
- DynamoDB를 위한 고가용성 인메모리 캐시
- 테이블에 읽기작업이 많을때 DAX 클러스터를 생성하고, 데이터를 캐싱하여 읽기 혼잡을 해결
- 마이크로 초 수준의 지연시간 제공
- DynamoDB의 테이블 핫키에서 과도한 양의 읽기를 오프로딩 해주어 ProvisionedThroughputExceededException 예외 처리 오류 방지
- Elastic Cache에 비해 대용량 연산 저장 시 좋음 / 쿼리, 스캔 캐시는 Elastic Cache가 좋음 -> 그래서 보통 DynamoDB캐싱 솔루션 추가할 떄 DAX를 사용
DynamoStream
- 이벤트 처리하는 기능
- DynamoDB 테이블에서 발생한 각 항목에 대한 변경 사항을 기록
- 기존 애플리케이션의 성능에 영향을 주지 않고 변경 사항을 캡처
- 람다 함수를 통해 이벤트에 실시간으로 자동 응답하는 트리거 생성 가능
- KinesisDataStream -> Kinesis DataFirehose -> redshift(analytics), S3(archiving), OpenSearch(indexing)로 전송도 가능
Global Table
- 복수의 리전에서 짧은 지연시간으로 엑세스할 수 있게 해준다.
- 다수의 리전에 걸처 active-active 복제 가능 -> 어느 리전에서나 읽기와 쓰기 가능
- READ , WRITE 모든 리전에서 가능 분리
- DynamoDB Stream을 활성화해야 사용가능
TTL (TimeToLive) 기능
- 만료 타임스탬프가 지나면 자동으로 항목 삭제
- 사용사례
- 최근 항목만 저장하거나, 2년 후 데이터 삭제 규정 따를 때
- 웹세션 핸들링
- 세션 로그인 일정시간 지나면 해당 테이블에서 삭제
- 재해복구
14.3 API Gateway
- lambda와 통합하면 완전 Serverless Application이여서 인프라 관리가 필요없다.
- 방식은 3가지
- Edge 최적화 : Global Client (여전히 하나의 AWS리전에 존재)
- Regional : API Gateway를 생성한 리전과 같은 리전에 있어야 함
- Private : VPC내에서만 엑세스
14.4 AWS Step Functions
- 서버리스 워크플로우를 시각적으로 구성하는 기능
- 주로 람다함수
14.5 Cognito
- 사용자에게 웹 및 모바일앱과 상호작용 할 수 있는 자격 증명 부여
- ‘수백명의 사용자’, ‘모바일 사용자’, ‘SAML을 통한 인증’이 나오면 Cognito
- 비밀번호 재설정 기능이 있고, 이메일 및 전화번호 검증 및 사용자 멀티팩터 인증 가능
15. AWS Database
- RDB - Aurora
- NoSQL - DynamoDB, Elastic Cache, Neptune DocumentDB, Keyspaces
- 객체 스토어 - S3, Glacier
- DataWarehouse - Redshift(OLAP), Athena, EMR
- Search - OpenSearch
- Graph - Amazon Neptune
- Ledger - Amazon Quantum Ledger Database
- 시계열 - Amazon Timestream
15.1 AuroraDB
- 서버리스
- PostgreSQL, MySQL과 호환
- GlobalDB 원할 땐 Aurora Global
- 리전마다 16개 read instance제공
- 스토리지 복제는 1초 미만
15.2 DocumentDB
- MongoDB와 비슷
15.6 Neptune
- 그래프 데이터베이스
- 3개의 AZ, 최대 15개의 읽기전용 복제본
- 빠르고, 신뢰도 높다
- 완전 관리형 그래프 데이터베이스 서비스로 고도로 연결된 데이터셋 처리
15.7 Keyspaces
- Apache Cassandra는 오픈소스 NoSQL이다.
- Keyspaces는 AWS가 Cassandra를 직접 관리해준다.
- IoT장치 정보, 시계열 데이터 등
15.8 QLDB
- 원장은 금융 트랜잭션을 기록하는 장부
- 즉, QLDB는 금융 트랜잭션 원장
- 불변 시스템, DB에 무엇인가 쓰면 삭제 or 수정 불가능
15.9 Timestream
- 시계열 데이터
16. Data & analysis
16.1 Athena
- S3버킷에 저장된 데이터 분석에 사용하는 서버리스 쿼리 서비스
- CSV, JSON등 다양한 형식제공
- Quicksight와 함께 사용 (대시보드 생성)
- AWS서비스에서 발생하는 모든 로그를 쿼리하고 분석 가능
- 서버리스로 S3 데이터 분석 = athena
- 성능 향상 방법
- 비용을 지불할 때 스캔된 데이터의 TB당 가격 지불하니 데이터를 적게 스캔할 유형의 데이터 사용 / 권장 형식 Apache Parquet과 ORC
- 데이터 압축
- 데이터 분할
- 큰 파일 사용해서 오버헤드 최소화 (128MB이상의 파일 사용)
16.2 Redshift
- AWS 클라우드에서 완벽하게 관리되는 페타바이트급 데이터 웨어하우스 서비스
- 데이터 웨어하우스는 노드라는 컴퓨팅 리소스의 모음으로, 노드는 클러스터라는 그룹을 구성
- 대량의 컬럼형 데이터에 대해 분석 쿼리를 효율적으로 수행할 수 있는 데이터베이스
- OLTP X
- OLAP 온라인 분석처리
- PB(페타바이트)의 데이터로 확대 가능
- 열기반 스토리지 -> 행기반과 다르게 병렬쿼리엔진이 있다
- 다중 AZ모드가 없다.
- 스냅샷 다른 AWS리전에 자동으로 복사하도록 레드시프트를 구성하여
- 재해복구전략을 적용 가능
- 데이터 수집 방법 3가지
- Data Firehose / S3 COPY / EC2 Instance JDBC
16.3 OpenSearch(Elastic Search)
- 검색 기능이 좋음
- 람다함수나 키네시스 데이터호스로 데이터 넣어줄 수 있음
16.5 EMR (Elastic Map Reduce)
- 빅데이터 작업을 위한 하둡 클러스터 생성
- 빅데이터를 위한 프로비저닝이 어려운데 이걸 대신
16.6 QuickSight
- 대화형 대시보드 생성
- 다양한 DB와 연결
- Salesforce와 JIRA도 연결 가능
16.7 Glue
- 추출과 변환 로드 서비스를 관리 ETL 서비스
- CSV와 Parquet간의 데이터 변환에 유용
- Glue Job Bookmark(작업 북마크) 새 ETL 작업을 실행할떄 이전 데이터 재처리방지
- Glue Elastic Views는 SQL을 사용해 여러 데이터 스토어의 데이터를 결합하고 복제
16.8 Lake Formation
- 데이터 레이크 생성 돕는다
- 데이터 레이크란 데이터 분석을 위해 모든 데이터를 한곳으로 모아주는 중앙 집중식 저장소
- 추가로 세분화된 액세스 제어가 가능(민감한 정보 접근제어)
16.9 MSK - Managed Streaming for Apache Kafka
- Kafka는 Amazon Kinesis의 대안
- 대규모 스트리밍 데이터를 분산 처리하는 데 사용되는 오픈소스 플랫폼
17. Machine learning
17.1 Rekognition
- 기계학습을 통해 객체 사람 텍스트 이미지 장면을 찾는 서비스
- 기계 학습을 통한 이미지와 비디오 분석 자동화
17.2 Transcribe
- 자동으로 음성을 텍스트로 변환
- Redaction을 사용하여 PII(개인 식별 정보) 제거 가능
- 다국어 오디오를 자동으로 언어 식별 가능
17.3 Polly
- 텍스트를 음성으로 변환
17.4 Translate
- 언어 번역
17.5 Lex + Connect
Lex : 챗봇 구축 Connect : 전화 받고 고객 응대 흐름 생성하는 클라우드 기반 서비스
17.6 Comprehend
- 자연어를 처리하는 NLP
17.7 SageMaker
- 완전 관리형 ML을 구축하는 개발자와 데이터 과학자를 위한 서비스
17.8 Forecast
- 예측을 도와준다.
17.9 Kendra
- Text, pdf, html등 추출해 문서 검색
17.10 Personalize
- 실시간 맞춤화 추천
17.11 Textract
- 스캔한 문서의 데이터 추출
18. AWS Monitoring (CloudWatch, CloudTail, Config)
18.1 AWS Cloud Watch
- CloudWatch는 AWS의 모든 서비스에 대한 지표 제공, 모니터링과 대시보드 만드는데 사용
- 서비스 당 네임스페이스 한개
- 시간 기반이므로 타임스탬프가 꼭 있어야 함
- 모든 지표를 한번에 볼 수 있다.
- 필터링 가능 (Subscription Filter)
- CloudWatchlog를 S3로 내보낼 수 있음
- 내보내기를 시작하기 위한 API호출은 CreateExportTask (최대 12시간)
- Kinesis Data Stream으로 내보내 멀티 계정, 멀티 리전로그를 모아서 보는게 가능
- 기존 Cloud watch는 로그만 보내는데 통합 cloud watch agent는 프로세스나 램같은 추가적인 시스템 단계지표 수집
Cloud Watch Alarm
- 3가지 상태가 존재 - OK, INSUFFICIENT_DATA, ALARM
- 주요 타깃 - EC2, EC2 Auto Scaling, SNS
Contributor Insights
- 상위 10개의 기고자 또는 비슷한 걸 본다면 Contributor Insights
- 불량 호스트 식별, 사용량 많은 유저 찾아낼 수 있다.
- ECS, EKS, EC2 Kubernetes, Fargate로 부터 오는 로그와 지표를 위한 것
CloudWatch Application Insights
- 모니터링하는 애플리케이션의 잠재적인 문제와 진행 중인 문제 분리할 수 있게 자동화된 대시보드
18.2 EventBridge
- 클라우드에서 CRON작업 예약 가능 ex) 1시간마다 람다함수 트리거해 스크립트 실행
18.3 CloudTail
API 호출에 대한 모든 호출 기록
- 로그를 Cloud Watch Logs 또는 S3에 저장 가능 -> 90일 동안 저장
- 90일 안넘으면 콘솔의 이벤트 내역 활용
- 이벤트는 AWS Services, AWS SaaS Partners, Custom App이 가능
18.4 AWS Config
- 구성 변경을 기록하고 규정 준수 규칙에 따라 리소스 평가
- AWS 리소스의 구성을 평가, 감사 및 평가할 수 있는 서비스
- ex) 보안그룹에 제한되지 않은 SSH접근 확인
- ex) S3에 무단 구성 변경 사항 있나 확인
- 변화가 생길 때마다 알림 받을 수 있음
CloudTail vs CloudWatch vs Config
ELB로 예시
- CloudWatch는 들어오는 연결 수 모니터링, 대시보드 생성
- SSL사용해야 한다 같은 규칙 Config로 지정
- API를 호출해서 SSL인증서 바꾸거나 삭제하면 CloudTail이 알림
19. Identity and Access Management (IAM)
Organizations
- 다수의 AWS 계정을 동시에 관리
- 모든 걔정의 비용을 통합 결제 가능
- 한 번에 모든 계정에 대해 CloudTrail을 활성화해서 모든 로그를 중앙 S3 계정으로 전송 가능
- 서비스 제어 정책, 즉 SCP를 정의 가능 (영구적인 관리자 계정은 전부 제어 가능)
- 정책에 명시적거부가 하나라도 포함되면 엑세스 거부
- PrincipalOrgID 를 지정하면 해당 조직의 계정에서만 작업하게 설정
- SNS, SQS, 람다는 리소스 기반 정책
- Kinesis는 IAM역할을 사용하고 있다.
IAM Permission Boundaries
- IAM개체의 최대 권한을 정의하는 고급 기능
AWS IAM 자격증명센터
- SSO
- Salesforce, Box, Microsoft365 등에 연결
마이크로소프트 AD
- 온프로미스에서 사용자를 프록시 한다면 AD커넥터가 필요하고,
- AWS클라우드에서 사용자를 관리하고 MFA를 사용해야 할 때는 AWS관리형 AD가 필요
- 온프로미스가 없을때엔 Simple AD
AWS Control tower
- AWS 리소스 관리를 위한 서비스
- 가드레일이라는 기능을 사용해 특정 AWS리전에만 엑세스하는 등의 제약사항 설정
20. AWS Security(KMS, SSM, Parameter Store, CloudHSM, Shield, WAF)
20.1 KMS
- 키관리 서비스
- 키를 사용하기 위해 호출한 모든 API를 감시 가능
- cloud trail과 통합 가능
20.2 SSM
- AWS에서 인프라를 보고 제어하기 위해 사용할 수 있는 AWS 서비스
20.3 AWS Secret Manager
- 암호를 저장하는 최신 서비스
- x일마다 암호 교체하는 기능 있음
- RDS와 Aurora 통합 혹은 암호에 대한 내용이 나오면 AWS Secrets Manager
20.4 ACM
- TLS/SSL인증서를 AWS에서 프로비저닝, 관리 및 배포하게 해준다.
20.5 WAF
- 7계층에서 일어나는 웹 취약점 공격으로부터 웹 어플리케이션 보호
- ALB, API Gateway, CloudFront, Cognito등 사용자 풀에서 배포 가능
- Firewall Manager로 방화벽 규칙 manage
20.6 AWS Shield
- DDOS공격으로부터 보호하기 위한 서비스
20.7 Amazon GuardDuty
- 지능형 위협 탐지를 이용해 AWS계정 보호 가능
20.8 Amazon Inspector
- 자동화된 보안 평가 실행
20.9 Amazon Macie
- 머신 러닝과 패턴 매칭을 이용해 AWS에 있는 민감한 데이터를 발견하고 보호
- PII(개인식별정보)같은 민감정보에 관해 경보 제공
21. VPC(Virtual Private Cloud)
VPC : 리소스(지역 리소스)를 배포하기 위한 사설 네트워크
- EC2, RDS, ELB 등을 탑재하고 ENI(Elastic Network Interface)에 사설 IP혹은 공인 IP를 부여해 사용
- 서브넷 사용 시 VPC내에서 네트워크 분할 가능
- 라우팅 테이블 설정 추가해 공용 서브넷 인터넷 접근 o, 사설 서브넷 인터넷 접근x
- NAT Gateways를 사용하면 프라이빗 서브넷의 인스턴스가 프라이빗 상태를 유지하며 인터넷 액세스 가능
-> 작동 방식 : NAT Instance를 공용 서브넷에 배포하고 사설 서브넷에서 게이트 웨이로 라우팅
NACL(Network Access Control Lists) : 공용 서브넷을 서브넷 수준에서 방어(default : All allow)
-> 그 후, 보안 그룹 적용
VPC Flow Logs
인터페이스로 들어가는 모든 IP 트래픽에 대한 정보 캡처
- 접근이 거부되거나 트래픽이 잠기거나 VPC 내 허용된 트래픽을 디버깅 할 때 사용
- ex) Elastic Load Balancers, ElasticCache, RDS, Aurora, etc
- VPC Flow Log는 S3, CloudWatch Logs 및 Kinesis Data Firehose로 이동 가능
VPC Peering
2개의 VPC를 비공개로 연결
- 동일한 네트워크에 있는 것처럼 작동
- CIDR(IP 주소 범위)이 겹치지 않아야 한다.
- 통신하는 각 VPC에 설정해야 한다
- 연결 생성 요금 X, 연결을 통한 전송 요금 O
VPC Endpoints
VPC 내 Resource들이 VPC 외부 서비스 (S3, Dynamo DB, Cloudwatch) 등에 접근할 때 Internet Gateway, NAT Gateway 등의 외부 인터넷전송 서비스를 타지 않고 내부 네트워크를 통해 접근할 수 있도록 지원하는 서비스
즉, AWS 여러 서비스와 VPC를 연결하는 중간 매개체로 VPC 바깥으로 트래픽이 나가지 않고 AWS의 여러 서비스 사용
- 보안 강화,비용 절감, 권한 제어, VPC 종속
온프레미스 데이터 센터와 AWS를 연결 할 경우
- Site-to-Site VPN을 사용해 공개 인터넷으로 연결
- 링크가 즉시 설정됨
- 적은 대역폭에 추천
- Direct Connect(DX)를 사용해 AWS에 비공개로 연결
- 전송 데이터양에 따라서 비용이 달라지지 않음
- 시간당 비용지불
- 웨어하우스와 동일한 AWS 리전에 설치하는게 경제적임
- 여러 DX 위치에서 DX연결 구성시 높은 복원력과 내결함성 획득
Network Firewall
- VPC수준에서 ip별, 프로토콜 별 등
22. Disaster Recovery and Migration
22.1 Amazon DR
- 복구 시점 목표를 의미하는 RPO(Recovery Point Objective) -> 재해 발생 시 데이터 손실을 얼마만큼 감수할 지 설정
- 복구 시간 목표를 의미하는 RTO(Recovery Time Objective) -> 어플리케이션 다운 타임
22.2 DMS(Database Migration Service)
22.3 RDB
22.4 BackUp
22.5 Application Migration Service(MGN)
23. More Solution Architecture
24. document, Architecture
24.1 AWS Well-Architected Framework and tool
- 체크리스트 느낌으로 체크하고 넘어갈 수 있음
24.2 AWS Trusted Advisor
- 계정에 대한 평가를 제공하는 서비스
유용한 링크
참조할 수 있는 아키텍처나 솔루션이 있음
title: AWS SAA 키워드, 오답정리 date: 2024-09-07 update: 2024-09-07 category:
- Cloud tags:
- Cloud
- AWS summary:
- AWS CertifiedDeveloper Associcate 학습 정리 thumbnail: ‘./thumbnail.png’ keywords:
- AWS
계속 Update중
Udemy Practice Exams 강의 듣고 문제 풀이 후 오답노트
- 적은노력 → 서버리스
- TCP/UDP → NLB
- DDOS → WAF
- 실시간 데이터처리 → Kinesis
- 확장성 → Auto Scaling
- 비용효율성 → S3
- 분리, 비동기 → SQS
- NLP → Amazon Comprehend
- 로그 누가?붙으면 → CloudTrail
- 수백 명의 사용자, 모바일사용자, SAML을 통한 인증 → Cognito
- RDS와 Aurora의 통합이나 암호화(비밀) → Secrets Manager
- IP멀티 캐스트 → Transit Gateway
- smb → S3 File Gateway, 파일서버 시스템용
- 퍼블릭 인터넷을 거치지 않고도 인스턴스 → VPN Endpoint
- 민감한 정보 → macie
- SSL/TLS 생성관리배포 → Certificate Manager (ACM)
- 컨테이너 → ECS, fargate, EKS
- 배치 동적 / 언제든지 중단,종료→ 스팟인스턴스
- 운영 최소화 → Auto Scaling X
- 가까운 엣지 로케이션, 고성능 → Global Accelerator
- 운영 오버헤드 최소화 → ECS, Fargate, ECR 및 EKS + Lambda
- 데이터 분석을 한곳으로 모은다 → lake Formation
- 전세계 사용자 → S3 + CloudFrount 원본으로
- 시간초과 최소화 → RDS 프록시
- 동적호스팅 → API Gateway + lamdba
- .csv → Glue
- 여러서버에서 동시에 액세스 → EFS
- 보안평가 → Inspector
- SQL 주입 → WAF
- 말도안되는 대규모 → Lambda@Edge + Cloud Front
- NAT Gateway → 무조건 퍼블릭서브넷에 존재
- 여러 VPC 연결 → Transit Gateway
- 수동승인 → Step Function
- Saas → App Flow
키-값 스토어 크기
- Amazon DynamoDB - 400KB
- S3 - 5tb
- 인스턴스 스토어는 일반 하드디스크와 같은 블록 레벨 스토리지로, 호스트 컴퓨터에 물리적으로 연결된 디스크에 위치 s3계층별 꼭 확인 다시